

本文由 @Simon V(https://github.com/simveit) 授权转载和翻译并发表到本公众号。原始地址为:https://veitner.bearblog.dev/tma-introduction/ & https://veitner.bearblog.dev/making-matrix-transpose-really-fast-on-hopper-gpus/
TMA简介
2025年4月27日https://veitner.bearblog.dev/making-matrix-transpose-really-fast-on-hopper-gpus/
高效地将数据从全局内存传输到共享内存以及反之亦然通常是CUDA应用程序的瓶颈。因此,我们应充分利用这种操作的最快机制。TMA是Hopper GPU中的一个新特性,其主要目标是提供一种高效的从全局内存到共享内存的数据传输机制,用于多维数组。在本篇博客中,我们将解释如何使用TMA对2D数组进行操作。
为了专注于基础知识,我们将执行一个非常简单的操作:给定一个矩阵M,我们希望对矩阵中的每个元素加1。
创建张量映射
为了利用2D TMA操作,我们需要一个TensorMap。下面我们展示了如何创建它:
int *d;
CHECK_CUDA_ERROR(cudaMalloc(&d, SIZE));
CHECK_CUDA_ERROR(cudaMemcpy(d, h_in, SIZE, cudaMemcpyHostToDevice));
void *tensor_ptr = (void *)d;
CUtensorMap tensor_map{};
// rank是数组的维度数。
constexpruint32_t rank = 2;
uint64_t size[rank] = {GMEM_WIDTH, GMEM_HEIGHT};
// stride是从一行的第一个元素到下一行第一个元素所需遍历的字节数。它必须是16的倍数。
uint64_t stride[rank - 1] = {GMEM_WIDTH * sizeof(int)};
// box_size是用作TMA传输目标的共享内存缓冲区的大小。
uint32_t box_size[rank] = {SMEM_WIDTH, SMEM_HEIGHT};
// 元素之间的距离,以sizeof(element)为单位。例如,stride为2可以用来只加载复值张量的实部。
uint32_t elem_stride[rank] = {1, 1};
// 创建张量描述符。
CUresult res = cuTensorMapEncodeTiled(
&tensor_map, // CUtensorMap *tensorMap,
CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_INT32,
rank, // cuuint32_t tensorRank,
tensor_ptr, // void *globalAddress,
size, // const cuuint64_t *globalDim,
stride, // const cuuint64_t *globalStrides,
box_size, // const cuuint32_t *boxDim,
elem_stride, // const cuuint32_t *elementStrides,
// 交错模式可用于加速加载小于4字节长的值。
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
// 交织可用于避免共享内存bank冲突。
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_NONE,
// L2提升可用于将缓存策略的效果扩展到更广泛的L2缓存行集合。
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
// TMA传输会将任何超出边界的元素设置为零。
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE);
assert(res == CUDA_SUCCESS);
注释取自NVIDIA文档(https://docs.nvidia.com/cuda/cuda-c-programming-guide/#asynchronous-data-copies-using-the-tensor-memory-accelerator-tma)。如代码所示,我们基本上为GMEM和SMEM设置配置。我们考虑矩阵d为行主序布局,并且不在此阶段执行任何swizzling。
Kernel
下面的kernel改编自NVIDIA文档。我们可以看到TMA的基本用法。
template <int BLOCK_SIZE>
__global__ void kernel(const __grid_constant__ CUtensorMap tensor_map) {
// 批量张量操作的目标共享内存缓冲区应该是128字节对齐的。
__shared__ alignas(1024) int smem_buffer[BLOCK_SIZE * BLOCK_SIZE];
// GMEM中左上角Tile的坐标。
int x = blockIdx.x * BLOCK_SIZE;
int y = blockIdx.y * BLOCK_SIZE;
int col = threadIdx.x % BLOCK_SIZE;
int row = threadIdx.x / BLOCK_SIZE;
// 使用参与屏障的线程数量初始化共享内存屏障。
#pragma nv_diag_suppress static_var_with_dynamic_init
__shared__ barrier bar;
if (threadIdx.x == 0) {
// 初始化屏障。块中所有`blockDim.x`线程都参与。
init(&bar, blockDim.x);
// 使初始化的屏障在异步代理中可见。
cde::fence_proxy_async_shared_cta();
}
// 同步线程,使初始化的屏障对所有线程可见。
__syncthreads();
barrier::arrival_token token;
if (threadIdx.x == 0) {
// 启动批量张量复制。
cde::cp_async_bulk_tensor_2d_global_to_shared(&smem_buffer, &tensor_map, x,
y, bar);
// 到达屏障并告知预期传入的字节数。
token = cuda::device::barrier_arrive_tx(bar, 1, sizeof(smem_buffer));
} else {
// 其他线程只需到达。
token = bar.arrive();
}
// 等待数据到达。
bar.wait(std::move(token));
// 在共享内存中符号性地修改一个值。
smem_buffer[row * BLOCK_SIZE + col] += 1;
// 等待共享内存写入对TMA引擎可见。
cde::fence_proxy_async_shared_cta();
__syncthreads();
// 同步线程后,所有线程的写入对TMA引擎可见。
// 启动TMA传输,将共享内存复制到全局内存
if (threadIdx.x == 0) {
cde::cp_async_bulk_tensor_2d_shared_to_global(&tensor_map, x, y,
&smem_buffer);
// 等待TMA传输完成读取共享内存。
// 从上一个批量复制操作创建一个"批量异步组"。
cde::cp_async_bulk_commit_group();
// 等待组完成从共享内存的读取。
cde::cp_async_bulk_wait_group_read<0>();
}
// 销毁屏障。这会使屏障的内存区域无效。如果kernel中还有进一步的计算,
// 这允许重用共享内存屏障的内存位置。
if (threadIdx.x == 0) {
(&bar)->~barrier();
}
}
在
cde::cp_async_bulk_tensor_2d_global_to_shared(&smem_buffer, &tensor_map, x,
y, bar);
我们将我们的矩阵Tile复制到共享内存中。这里的x和y对应于矩阵中左上角Tile的坐标。然后我们在共享内存中执行一个简单的操作(为每个元素加1)并将其传回全局内存。
Swizzling
在共享内存中我们可能会遇到bank冲突。关于这个主题的更多背景知识,你可以阅读NVIDIA文档(https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#data-movement-and-conversion-instructions-cp-async-bulk-tensor)中的专门章节。
我们可以在张量映射中定义交织模式来避免bank冲突。TMA将以交织方式传输数组,因此我们需要使用交织后的索引来正确地索引共享内存中的列。kernel的调整如下:
template <int BLOCK_SIZE>
__global__ void kernel(const __grid_constant__ CUtensorMap tensor_map) {
// 批量张量操作的目标共享内存缓冲区应该是128字节对齐的。
__shared__ alignas(256) int smem_buffer[BLOCK_SIZE * BLOCK_SIZE];
// GMEM中左上角Tile的坐标。
int x = blockIdx.x * BLOCK_SIZE;
int y = blockIdx.y * BLOCK_SIZE;
int col = threadIdx.x % BLOCK_SIZE;
int row = threadIdx.x / BLOCK_SIZE;
int col_swizzle = (row % 2) ^ col;
// 使用参与屏障的线程数量初始化共享内存屏障。
#pragma nv_diag_suppress static_var_with_dynamic_init
__shared__ barrier bar;
if (threadIdx.x == 0) {
// 初始化屏障。块中所有`blockDim.x`线程都参与。
init(&bar, blockDim.x);
// 使初始化的屏障在异步代理中可见。
cde::fence_proxy_async_shared_cta();
}
// 同步线程,使初始化的屏障对所有线程可见。
__syncthreads();
barrier::arrival_token token;
if (threadIdx.x == 0) {
// 启动批量张量复制。
cde::cp_async_bulk_tensor_2d_global_to_shared(&smem_buffer, &tensor_map, x,
y, bar);
// 到达屏障并告知预期传入的字节数。
token = cuda::device::barrier_arrive_tx(bar, 1, sizeof(smem_buffer));
} else {
// 其他线程只需到达。
token = bar.arrive();
}
// 等待数据到达。
bar.wait(std::move(token));
// 在共享内存中符号性地修改一个值。
smem_buffer[row * BLOCK_SIZE + col_swizzle] += 1;
// 等待共享内存写入对TMA引擎可见。
cde::fence_proxy_async_shared_cta();
__syncthreads();
// 同步线程后,所有线程的写入对TMA引擎可见。
// 启动TMA传输,将共享内存复制到全局内存
if (threadIdx.x == 0) {
cde::cp_async_bulk_tensor_2d_shared_to_global(&tensor_map, x, y,
&smem_buffer);
// 等待TMA传输完成读取共享内存。
// 从上一个批量复制操作创建一个"批量异步组"。
cde::cp_async_bulk_commit_group();
// 等待组完成从共享内存的读取。
cde::cp_async_bulk_wait_group_read<0>();
}
// 销毁屏障。这会使屏障的内存区域无效。如果kernel中还有进一步的计算,
// 这允许重用共享内存屏障的内存位置。
if (threadIdx.x == 0) {
(&bar)->~barrier();
}
}
并且在张量映射中我们需要调整交织设置
int *d;
CHECK_CUDA_ERROR(cudaMalloc(&d, SIZE));
CHECK_CUDA_ERROR(cudaMemcpy(d, h_in, SIZE, cudaMemcpyHostToDevice));
void *tensor_ptr = (void *)d;
CUtensorMap tensor_map{};
// rank是数组的维度数。
constexpruint32_t rank = 2;
uint64_t size[rank] = {GMEM_WIDTH, GMEM_HEIGHT};
// stride是从一行的第一个元素到下一行第一个元素所需遍历的字节数。它必须是16的倍数。
uint64_t stride[rank - 1] = {GMEM_WIDTH * sizeof(int)};
// box_size是用作TMA传输目标的共享内存缓冲区的大小。
uint32_t box_size[rank] = {SMEM_WIDTH, SMEM_HEIGHT};
// 元素之间的距离,以sizeof(element)为单位。例如,stride为2可以用来只加载复值张量的实部。
uint32_t elem_stride[rank] = {1, 1};
// 创建张量描述符。
CUresult res = cuTensorMapEncodeTiled(
&tensor_map, // CUtensorMap *tensorMap,
CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_INT32,
rank, // cuuint32_t tensorRank,
tensor_ptr, // void *globalAddress,
size, // const cuuint64_t *globalDim,
stride, // const cuuint64_t *globalStrides,
box_size, // const cuuint32_t *boxDim,
elem_stride, // const cuuint32_t *elementStrides,
// 交错模式可用于加速加载小于4字节长的值。
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
// 交织可用于避免共享内存bank冲突。
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_32B,
// L2提升可用于将缓存策略的效果扩展到更广泛的L2缓存行集合。
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
// TMA传输会将任何超出边界的元素设置为零。
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE);
assert(res == CUDA_SUCCESS);
结论
以上我们展示了TMA在Hopper架构中的一个非常简单的应用。此外,交织相当复杂,为了更好地理解它,进一步实验并深入研究这个主题会很有帮助。如果有人有好的学习资源建议,我很乐意听取。你可以在Github(https://github.com/simveit/tma_intro)上找到代码。
Making matrix transpose really fast on Hopper GPUs
2025年5月2日
介绍
在这篇博客中,我想展示如何实现高效的矩阵转置操作,用于Hopper GPU。我将使用原生CUDA API,不使用抽象,因为我相信这是学习硬件细节的好方法。正如你将看到的,使用交织并能够将交织的索引映射到普通索引是非常重要的。不幸的是,这在其他优秀的CUDA编程指南中没有很好地记录。我希望这篇博客能帮助更多的人使用原生CUDA实现高性能的kernel。
交织
可视化交织模式
在实现矩阵转置之前,重要的是我们要理解交织。交织是一种避免共享内存冲突的技术。在以下我们将使用在Hopper GPU上TMA的以下概念。为了更好地理解可能发生的Bank冲突,让我们可视化2d int矩阵的Bank分配。我们使用以下不使用交织的布局:
const int GMEM_WIDTH = 32;
constint GMEM_HEIGHT = 32;
constint BLOCK_SIZE = 32;
constint SMEM_WIDTH = BLOCK_SIZE;
constint SMEM_HEIGHT = BLOCK_SIZE;
// 创建张量描述符。
CUresult res = cuTensorMapEncodeTiled(
&tensor_map, // CUtensorMap *tensorMap,
CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_INT32,
rank, // cuuint32_t tensorRank,
tensor_ptr, // void *globalAddress,
size, // const cuuint64_t *globalDim,
stride, // const cuuint64_t *globalStrides,
box_size, // const cuuint32_t *boxDim,
elem_stride, // const cuuint32_t *elementStrides,
// 交织模式可用于加速加载小于4字节长的值。
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
// 交织可用于避免共享内存Bank冲突。
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_NONE,
// L2提升可用于将缓存策略的效果扩展到更广泛的L2缓存行集合。
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
// 任何超出边界的元素都将被TMA设置为零。
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE);
然后像下面这样填充共享内存块。
smem_buffer[row * BLOCK_SIZE + col] = (row * BLOCK_SIZE + col) % 32;
我们可以可视化这个:
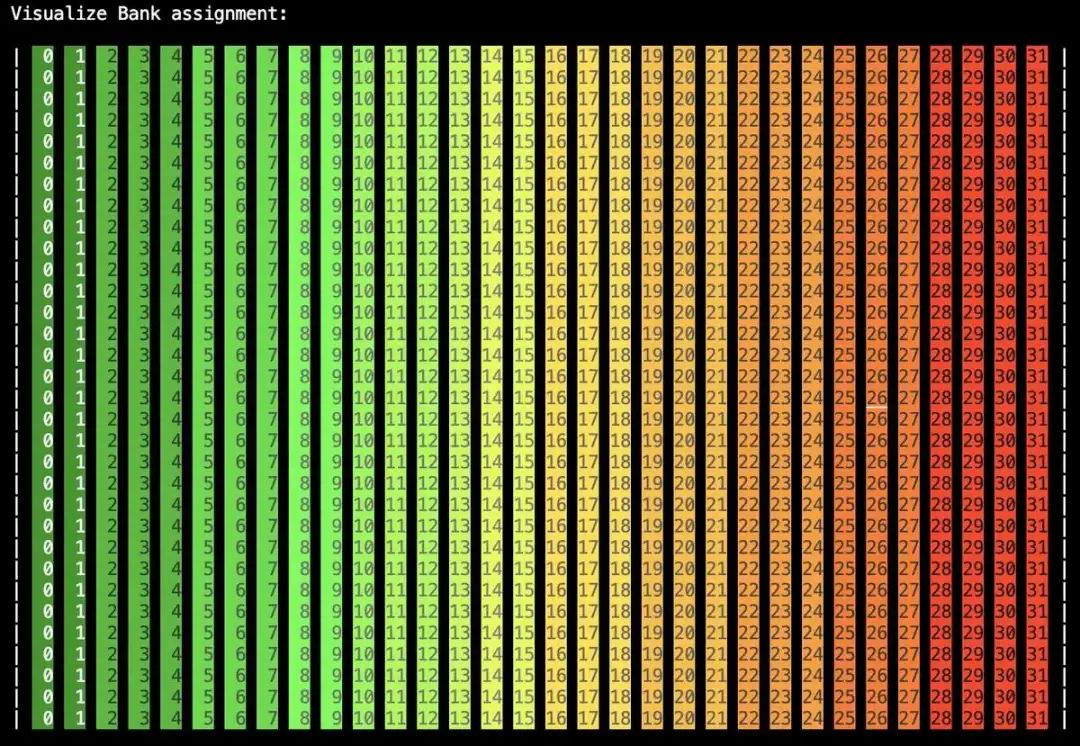
我们看到每一列都被分配给一个Bank。这意味着如果同一warp中的线程访问相同的列,我们将有一个Bank冲突。我们现在可以修改布局,使我们使用128B交织模式
// 创建张量描述符。
CUresult res = cuTensorMapEncodeTiled(
&tensor_map, // CUtensorMap *tensorMap,
CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_INT32,
rank, // cuuint32_t tensorRank,
tensor_ptr, // void *globalAddress,
size, // const cuuint64_t *globalDim,
stride, // const cuuint64_t *globalStrides,
box_size, // const cuuint32_t *boxDim,
elem_stride, // const cuuint32_t *elementStrides,
// 交织模式可用于加速加载小于4字节长的值。
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
// 交织可用于避免共享内存Bank冲突。
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_128B,
// L2提升可用于将缓存策略的效果扩展到更广泛的L2缓存行集合。
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
// 任何超出边界的元素都将被TMA设置为零。
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE);
assert(res == CUDA_SUCCESS);
对SMEM中的值进行相同的赋值将产生以下图片:
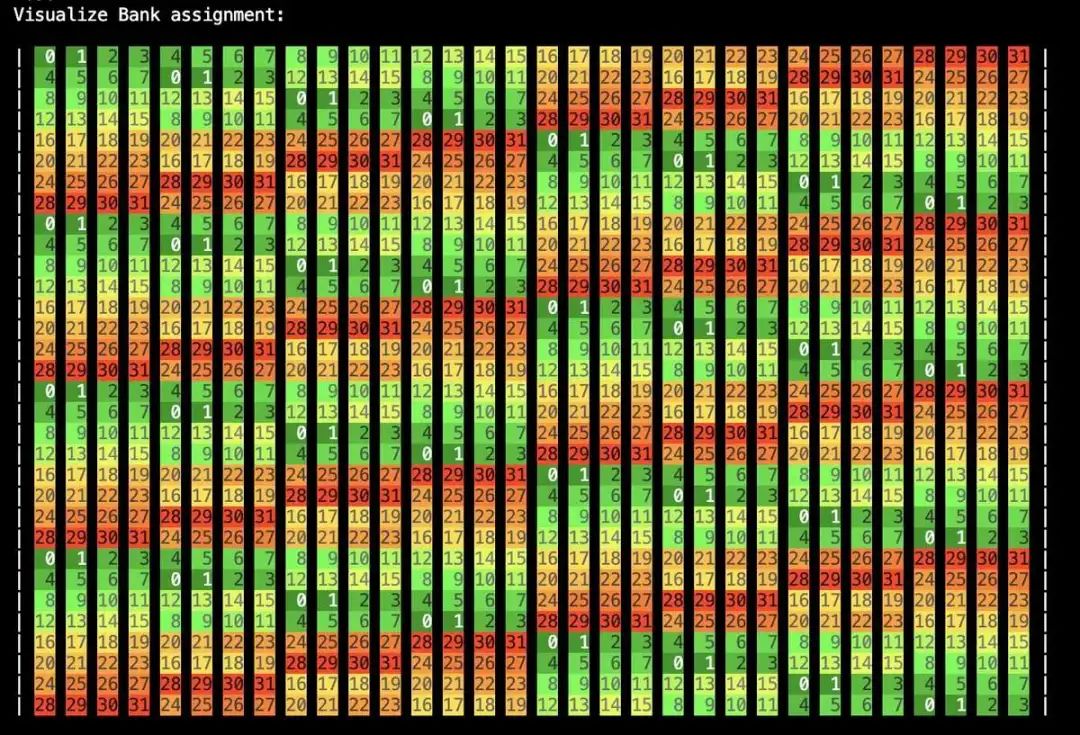
我们可以看到我们现在有显著更少的潜在Bank冲突。交织模式是周期性的,在矩阵中每8 * 32 * sizeof(int) = 128个元素重复一次。
使用正确的索引修改共享内存。
TMA在从全局内存传输数据到共享内存时会自动为我们进行数据交织。那么我们如何恢复这些被交织的索引呢?虽然NVIDIA的官方文档(https://docs.nvidia.com/cuda/cuda-c-programming-guide/#tma-swizzle)中并没有详细说明TMA交织的具体实现,但在Igor Terentyev的GTC Talk(https://www.nvidia.com/en-us/on-demand/session/gtc24-s62192/)中提供了相关的计算公式。具体公式如下:

图片解析开始
这张图详细描述了在 128 字节段内对 16 字节块进行 swizzle(交织)操作的索引计算方法。
1. 约束条件(Constraints)
-
NX * sizeof(T) == SWIZZLE_SIZE其中T array[][NX],即二维数组的每一行有NX个元素,T是元素类型。 也就是说,每一行的字节数必须等于SWIZZLE_SIZE。 -
SWIZZLE_SIZE允许的取值:32, 64, 128 这意味着每一行的字节数只能是 32、64 或 128 字节。
2. 索引计算流程
假设有一个二维数组 T array[][NX],我们要根据 [y][x] 位置计算其 swizzle 后的索引。
步骤 1:计算 128 字节段内 16 字节块的索引
-
i16 := (y * NX + x) * sizeof(T) / 16先将二维索引[y][x]转为一维线性索引,再乘以元素字节数,得到字节偏移,最后除以 16 得到属于哪个 16 字节块。 -
y16 := i16 / 8128 字节段内有 8 个 16 字节块,所以i16除以 8 得到块组编号。 -
x16 := i16 % 8i16对 8 取模,得到在 128 字节段内的块内偏移。
步骤 2:计算 16 字节块的 swizzled 索引
-
x16_swz := y16 ^ x16这里用到了异或(^)操作。y16和x16进行异或,得到 swizzled 的块内偏移。
步骤 3:计算最终 swizzled 索引
-
x_swz := x16_swz * 16 / sizeof(T) % NX + x % (16 / sizeof(T))x16_swz * 16 / sizeof(T):swizzled 块的起始元素索引(以元素为单位)。% NX:保证索引不会越过一行。x % (16 / sizeof(T)):在 16 字节块内的元素偏移。
图片解析结束
我们可以为sizeof(T)=4的数据类型实现如下:
template <int BLOCK_SIZE>
__device__ int calculate_col_swizzle(int row, int col) {
int i16 = (row * BLOCK_SIZE + col) * 4 >> 4;
int y16 = i16 >> 3;
int x16 = i16 & 7;
int x16_swz = y16 ^ x16;
return ((x16_swz * 4) & (BLOCK_SIZE - 1)) + (col & 3);
}
我们可以通过以下代码验证公式的正确性:
int col_swizzle = calculate_col_swizzle<BLOCK_SIZE>(row, col);
smem_buffer[row * BLOCK_SIZE + col_swizzle] = (row * BLOCK_SIZE + col) % 32;
使用交织布局,我们可以得到以下结果:
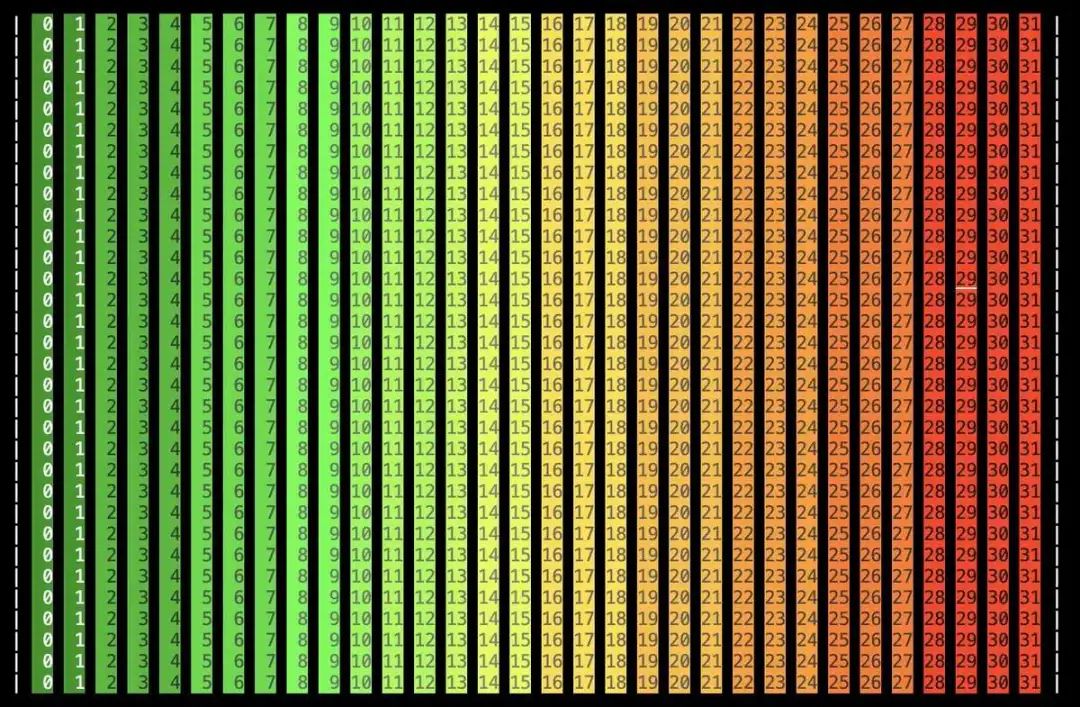
应用:矩阵转置
朴素方法
以下图片来自NVIDIA博客(https://developer.nvidia.com/blog/efficient-matrix-transpose-cuda-cc/),非常清楚地说明了如何在共享内存中执行转置:
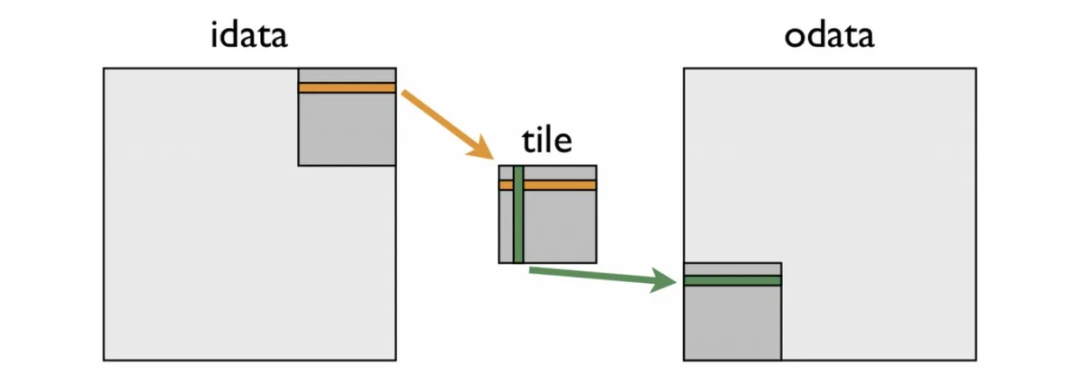
我们取一个矩阵块,转置该块,并将其放置在矩阵的另一端。下面我们概述了如何使用TMA和布局实现这种朴素算法,而不使用交织。完整代码可以在我的github仓库中找到,链接在博客末尾。我们需要两个布局,它们是转置的:
// 创建张量描述符。
CUresult res = cuTensorMapEncodeTiled(
&tensor_map, // CUtensorMap *tensorMap,
CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_FLOAT32,
rank, // cuuint32_t tensorRank,
tensor_ptr, // void *globalAddress,
size, // const cuuint64_t *globalDim,
stride, // const cuuint64_t *globalStrides,
box_size, // const cuuint32_t *boxDim,
elem_stride, // const cuuint32_t *elementStrides,
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_NONE,
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE);
assert(res == CUDA_SUCCESS);
CUresult res_tr = cuTensorMapEncodeTiled(
&tensor_map_tr, // CUtensorMap *tensorMap,
CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_FLOAT32,
rank, // cuuint32_t tensorRank,
tensor_ptr_tr, // void *globalAddress,
size_tr, // const cuuint64_t *globalDim,
stride, // const cuuint64_t *globalStrides,
box_size_tr, // const cuuint32_t *boxDim,
elem_stride, // const cuuint32_t *elementStrides,
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_NONE,
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE);
assert(res_tr == CUDA_SUCCESS);
我们可以使用以下kernel执行转置:
template <int BLOCK_SIZE>
__global__ void kernel(const __grid_constant__ CUtensorMap tensor_map,
const __grid_constant__ CUtensorMap tensor_map_tr) {
// 一个bulk tensor操作的目标共享内存缓冲区应该被128字节对齐。
__shared__ alignas(1024) float smem_buffer[BLOCK_SIZE * BLOCK_SIZE];
__shared__ alignas(1024) float smem_buffer_tr[BLOCK_SIZE * BLOCK_SIZE];
// GMEM中上左块的坐标。
int x = blockIdx.x * BLOCK_SIZE;
int y = blockIdx.y * BLOCK_SIZE;
int col = threadIdx.x % BLOCK_SIZE;
int row = threadIdx.x / BLOCK_SIZE;
// 用参与屏障的线程数初始化共享内存屏障。
#pragma nv_diag_suppress static_var_with_dynamic_init
__shared__ barrier bar;
if (threadIdx.x == 0) {
// 初始化屏障。所有`blockDim.x`线程参与。
init(&bar, blockDim.x);
// 使初始化的屏障在异步代理中可见。
cde::fence_proxy_async_shared_cta();
}
// 同步线程,使初始化的屏障对所有线程可见。
__syncthreads();
barrier::arrival_token token;
if (threadIdx.x == 0) {
// 发起bulk tensor复制。
cde::cp_async_bulk_tensor_2d_global_to_shared(&smem_buffer, &tensor_map, x,
y, bar);
// 在屏障上到达并告诉有多少字节即将到来。
token = cuda::device::barrier_arrive_tx(bar, 1, sizeof(smem_buffer));
} else {
// 其他线程只到达。
token = bar.arrive();
}
// 等待数据到达。
bar.wait(std::move(token));
// 转置块。
smem_buffer_tr[col * BLOCK_SIZE + row] = smem_buffer[row * BLOCK_SIZE + col];
// 等待共享内存写入对TMA引擎可见。
cde::fence_proxy_async_shared_cta();
__syncthreads();
// 在同步线程之后,所有线程的写入对TMA引擎可见。
// 发起TMA传输以将共享内存复制到全局内存
if (threadIdx.x == 0) {
// 在矩阵中转置块
cde::cp_async_bulk_tensor_2d_shared_to_global(&tensor_map_tr, y, x,
&smem_buffer_tr);
// 等待TMA传输完成读取共享内存。
// 从之前的bulk复制操作中创建一个“bulk异步组”。
cde::cp_async_bulk_commit_group();
// 等待组完成从共享内存读取。
cde::cp_async_bulk_wait_group_read<0>();
}
// 销毁屏障。这将使屏障的内存区域无效。如果内核中进一步的计算发生,这将允许共享内存屏障的内存位置被重用。
if (threadIdx.x == 0) {
(&bar)->~barrier();
}
}
对于转置,我们只需要:
smem_buffer_tr[col * BLOCK_SIZE + row] = smem_buffer[row * BLOCK_SIZE + col];
一旦完成,我们就可以将转置的块传输到转置布局的另一端(即我们交换x和y)。
这个kernel在32768 x 32768的矩阵转置上实现了以下性能:
Latency = 9.81191 ms
Bandwidth = 875.46 GB/s
% of max = 26.5291 %
交织转置
一旦我们有了上面的索引公式,交织转置在原理上是非常直接的。不幸的是,这个公式很难找到,所以花了些时间才正确。对于布局,我们只需要将交织模式更改为:
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_128B
重要的是,我们需要使用上面的公式来考虑到TMA在从GMEM->SMEM或从SMEM->GMEM转换时交织和取消交织内存。输入布局是行主格式,输出布局是列主格式,所以我们需要使用col_swizzle而不是col来对应输入块的共享内存,使用row_swizzle而不是row来对应输出块的共享内存。完整的kernel如下:
template <int BLOCK_SIZE>
__device__ int calculate_col_swizzle(int row, int col) {
int i16 = (row * BLOCK_SIZE + col) * 4 >> 4;
int y16 = i16 >> 3;
int x16 = i16 & 7;
int x16_swz = y16 ^ x16;
return ((x16_swz * 4) & (BLOCK_SIZE - 1)) + (col & 3);
}
template <int BLOCK_SIZE>
__device__ int calculate_row_swizzle(int row, int col) {
int i16_tr = (col * BLOCK_SIZE + row) * 4 >> 4;
int y16_tr = i16_tr >> 3;
int x16_tr = i16_tr & 7;
int x16_swz_tr = y16_tr ^ x16_tr;
return ((x16_swz_tr * 4) & (BLOCK_SIZE - 1)) + (row & 3);
}
template <int BLOCK_SIZE, int LOG_BLOCK>
__global__ void kernel(const __grid_constant__ CUtensorMap tensor_map,
const __grid_constant__ CUtensorMap tensor_map_tr) {
// bulk tensor操作的目标共享内存缓冲区应该被128字节对齐。
__shared__ alignas(1024) float smem_buffer[BLOCK_SIZE * BLOCK_SIZE];
__shared__ alignas(1024) float smem_buffer_tr[BLOCK_SIZE * BLOCK_SIZE];
// GMEM中上左块的坐标。
int x = blockIdx.x * BLOCK_SIZE;
int y = blockIdx.y * BLOCK_SIZE;
int col = threadIdx.x & (BLOCK_SIZE - 1);
int row = threadIdx.x >> LOG_BLOCK;
int col_swizzle = calculate_col_swizzle<BLOCK_SIZE>(row, col);
int row_swizzle = calculate_row_swizzle<BLOCK_SIZE>(row, col);
// 用参与屏障的线程数初始化共享内存屏障。
#pragma nv_diag_suppress static_var_with_dynamic_init
__shared__ barrier bar;
if (threadIdx.x == 0) {
// 初始化屏障。所有`blockDim.x`线程参与。
init(&bar, blockDim.x);
// 使初始化的屏障在异步代理中可见。
cde::fence_proxy_async_shared_cta();
}
// 同步线程,使初始化的屏障对所有线程可见。
__syncthreads();
barrier::arrival_token token;
if (threadIdx.x == 0) {
// 发起bulk tensor复制。
cde::cp_async_bulk_tensor_2d_global_to_shared(&smem_buffer, &tensor_map, x,
y, bar);
// 在屏障上到达并告诉有多少字节即将到来。
token = cuda::device::barrier_arrive_tx(bar, 1, sizeof(smem_buffer));
} else {
// 其他线程只到达。
token = bar.arrive();
}
// 等待数据到达。
bar.wait(std::move(token));
// Transpose tile.
smem_buffer_tr[col * BLOCK_SIZE + row_swizzle] =
smem_buffer[row * BLOCK_SIZE + col_swizzle];
// 等待共享内存写入对TMA引擎可见。
cde::fence_proxy_async_shared_cta();
__syncthreads();
// 在同步线程之后,所有线程的写入对TMA引擎可见。
// Initiate TMA transfer to copy shared memory to global memory
if (threadIdx.x == 0) {
// 在矩阵中转置块
cde::cp_async_bulk_tensor_2d_shared_to_global(&tensor_map_tr, y, x,
&smem_buffer_tr);
// 等待TMA传输完成读取共享内存。
// 从之前的bulk复制操作中创建一个“bulk异步组”。
cde::cp_async_bulk_commit_group();
// 等待组完成从共享内存读取。
cde::cp_async_bulk_wait_group_read<0>();
}
// 销毁屏障。这将使屏障的内存区域无效。如果内核中进一步的计算发生,这将允许共享内存屏障的内存位置被重用。
if (threadIdx.x == 0) {
(&bar)->~barrier();
}
}
这个kernel在32768 x 32768的矩阵转置上实现了以下性能:
Latency = 6.86226 ms
Bandwidth = 1251.76 GB/s
% of max = 37.9323 %
线程批处理
在像矩阵转置这样的内存带宽问题中,通常(如您在reduce或scan的博客文章中可以读到的,我们可以通过让每个线程处理多个元素来获得巨大的性能提升。我们可以实现如下:我们只启动一部分线程,即,而不是BLOCK_SIZE * BLOCK_SIZE线程,我们只启动BLOCK_SIZE * BLOCK_SIZE / BATCH_SIZE线程。我们然后让每个线程处理BATCH_SIZE元素(注意:在我们的实现中,我们选择BLOCK_SIZE=32来启动最大数量的线程,我们可以增加BLOCK_SIZE=64并使用BATCH_SIZE=16再次启动最大数量的线程。)
在像矩阵转置这样的内存带宽问题中,通常(正如你可以在我关于归约或扫描的博客文章中读到的那样),我们可以通过让每个线程处理多个元素来获得巨大的性能提升。我们可以这样实现:我们只启动一部分线程,即不是启动BLOCK_SIZE * BLOCK_SIZE个线程,而是只启动BLOCK_SIZE * BLOCK_SIZE / BATCH_SIZE个线程。然后让每个线程处理BATCH_SIZE个元素(注意:在我们的实现中,我们选择BLOCK_SIZE=32来启动最大数量的线程,我们可以增加BLOCK_SIZE=64并使用BATCH_SIZE=16再次启动最大数量的线程)。
完整的kernel如下所示:
template <int BLOCK_SIZE>
__device__ int calculate_col_swizzle(int row, int col) {
int i16 = (row * BLOCK_SIZE + col) * 4 >> 4;
int y16 = i16 >> 3;
int x16 = i16 & 7;
int x16_swz = y16 ^ x16;
return ((x16_swz * 4) & (BLOCK_SIZE - 1)) + (col & 3);
}
template <int BLOCK_SIZE>
__device__ int calculate_row_swizzle(int row, int col) {
int i16_tr = (col * BLOCK_SIZE + row) * 4 >> 4;
int y16_tr = i16_tr >> 3;
int x16_tr = i16_tr & 7;
int x16_swz_tr = y16_tr ^ x16_tr;
return ((x16_swz_tr * 4) & (BLOCK_SIZE - 1)) + (row & 3);
}
template <int BLOCK_SIZE, int LOG_BLOCK, int BATCH_SIZE, int LOG_BATCH_SIZE>
__global__ void kernel(const __grid_constant__ CUtensorMap tensor_map,
const __grid_constant__ CUtensorMap tensor_map_tr) {
// bulk tensor操作的目标共享内存缓冲区应该被128字节对齐。
__shared__ alignas(1024) float smem_buffer[BLOCK_SIZE * BLOCK_SIZE];
__shared__ alignas(1024) float smem_buffer_tr[BLOCK_SIZE * BLOCK_SIZE];
// GMEM中上左块的坐标。
int x = blockIdx.x * BLOCK_SIZE;
int y = blockIdx.y * BLOCK_SIZE;
int col = (threadIdx.x & (BLOCK_SIZE / BATCH_SIZE - 1)) * BATCH_SIZE;
int row = threadIdx.x >> (LOG_BLOCK - LOG_BATCH_SIZE);
// 用参与屏障的线程数初始化共享内存屏障。
#pragma nv_diag_suppress static_var_with_dynamic_init
__shared__ barrier bar;
if (threadIdx.x == 0) {
// 初始化屏障。所有`blockDim.x`线程参与。
init(&bar, blockDim.x);
// 使初始化的屏障在异步代理中可见。
cde::fence_proxy_async_shared_cta();
}
// 同步线程,使初始化的屏障对所有线程可见。
__syncthreads();
barrier::arrival_token token;
if (threadIdx.x == 0) {
// 发起bulk tensor复制。
cde::cp_async_bulk_tensor_2d_global_to_shared(&smem_buffer, &tensor_map, x,
y, bar);
// 在屏障上到达并告诉有多少字节即将到来。
token = cuda::device::barrier_arrive_tx(bar, 1, sizeof(smem_buffer));
} else {
// 其他线程只到达。
token = bar.arrive();
}
// 等待数据到达。
bar.wait(std::move(token));
// 转置块。
#pragma unroll
for (int j = 0; j < BATCH_SIZE; j++) {
int col_ = col + j;
int row_ = row;
int col_swizzle = calculate_col_swizzle<BLOCK_SIZE>(row_, col_);
int row_swizzle = calculate_row_swizzle<BLOCK_SIZE>(row_, col_);
smem_buffer_tr[col_ * BLOCK_SIZE + row_swizzle] =
smem_buffer[row_ * BLOCK_SIZE + col_swizzle];
}
// 等待共享内存写入对TMA引擎可见。
cde::fence_proxy_async_shared_cta();
__syncthreads();
// 在同步线程之后,所有线程的写入对TMA引擎可见。
// 发起TMA传输以将共享内存复制到全局内存
if (threadIdx.x == 0) {
// 在矩阵中转置块
cde::cp_async_bulk_tensor_2d_shared_to_global(&tensor_map_tr, y, x,
&smem_buffer_tr);
// 等待TMA传输完成读取共享内存。
// 从之前的bulk复制操作中创建一个“bulk异步组”。
cde::cp_async_bulk_commit_group();
// 等待组完成从共享内存读取。
cde::cp_async_bulk_wait_group_read<0>();
}
// 销毁屏障。这将使屏障的内存区域无效。如果内核中进一步的计算发生,这将允许共享内存屏障的内存位置被重用。
if (threadIdx.x == 0) {
(&bar)->~barrier();
}
}
这个kernel在32768 x 32768的矩阵转置上实现了以下性能:
Latency = 3.09955 ms
Bandwidth = 2771.35 GB/s
% of max = 83.9804 %
Conclusion
我们看到,一旦我们有了从swizzled索引获取索引的公式,实现矩阵转置在Hopper架构上以非常高效的方式就非常简单了。还有一篇很棒的博客文章使用CUTLASS执行相同的操作,但我相信实现操作而不使用任何抽象是很有教育意义的。如果你对CUTLASS感兴趣,可以查看这篇博客文章(https://research.colfax-intl.com/tutorial-matrix-transpose-in-cutlass/)。
(文:GiantPandaCV)