


作者 | 石濑 阿虎
编辑 | 张洁
谷歌旗下首个AI视频创作平台Flow,首批合作导演名单里出现了唯一一个亚洲女性面孔:Junie Lau。
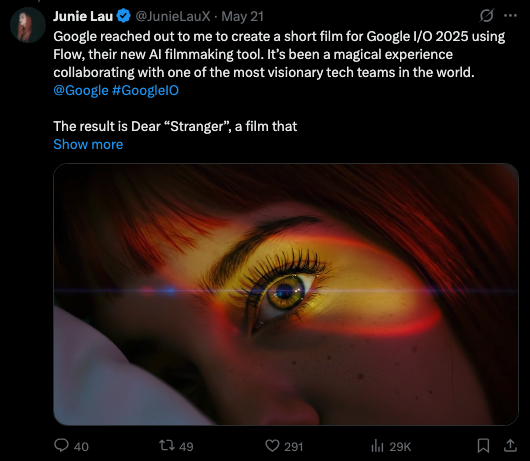
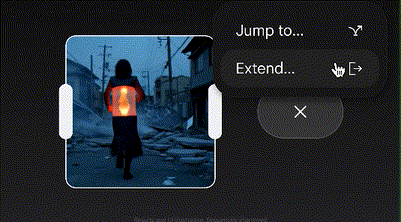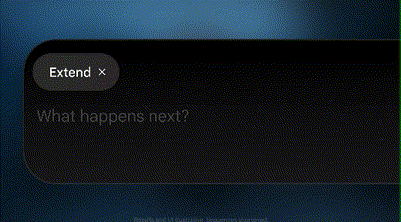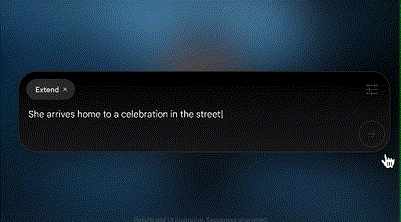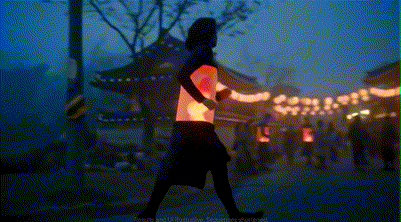
基于Flow平台,Junie制作的AI微电影《浮生若梦》(Dear “Stranger”)于近日面向公众发布。
这条短片讲述了主人公Eden出生之时,她的祖母离开了。一列火车撞进平行宇宙,时间裂解,记忆如潮水般涌入舞台。女孩Eden穿越无数时空,寻找那个用沉默爱了她一生的女人。
幕后创作者Junie在AI影视创作领域有很多一线实践经验。她的AI短片《e^(i*π) + 1 = 0》曾在有“AI奥斯卡”之称的Runway AI电影节中获得银奖,又在柏林、阿姆斯特丹、翠贝卡等国际电影节上频频展映。她也是OpenAI Sora官方艺术家,去年还作为Runway中国社区负责人,完成了Runway中国社群的落地和推广。我们曾跟她进行过几次对话:
相关阅读:对话全球首部AI电影制作人:幕后制作全流程揭秘;花1460元生成5个20秒高清视频,刚上线的Sora还只是“丐版”?
这次的《浮生若梦》是Junie跟谷歌Flow的深度合作。Flow整合了Veo、Imagen和Gemini等谷歌AI模型,它们分别对应处理视频、图片、文本这三种模态,支持创作者一键生成8秒音画同步的视频,并且可以基于不同视频片段、图片素材组合进行编排生成。
其中,谷歌新一代视频模型Veo 3在音画同步、画面细节、物理模拟等多方面表现惊艳,强势带动了“Veo 3+Flow”的话题讨论热度,更有创作者称这开启了“AI视频创作新时代”。
Veo 3正式上线Flow后,“AI新榜”也第一时间氪金实测了多个案例(练习时长两年半,谷歌Veo 3刷屏,我们花900元做了一条AI“猫片”),不吹不黑谷歌这一次真的有两把刷子,起码在“一键生成有声视频”上带来了新的体验。
为了进一步了解深度体验者的创作体验,《浮生若梦》正式发布后一天,“AI新榜”独家对话了Junie。在对话中,她向我们分享了Flow诞生背后的故事,以及过去一年来她使用AI进行影像创作和实验的经验和见解。
以下是对话实录:
AI新榜:这次短片所有工作流都是借助Veo 3和Flow完成的吗?
Junie:其实不是。项目启动及主要制作阶段,我们更多依赖的是Flow平台及其底层的Veo 2模型能力。直到谷歌I/O大会前两天,大约5月18号左右,Veo 3模型才正式开放给包括我在内的少数内部创作者进行测试使用。因此,短片是基于Veo 2完成的,而Veo 3更多是在项目后期作为补充进行了尝试。
AI新榜:你们是怎么用Veo 3的?
Junie:我们内部尝试最多的例子就是,通过文字指令让一名歌手在特定环境下唱Rap,Veo 3在这一方面效果做得挺好的。另外,Veo 3也可以通过上传图片生成视频(注:该功能已于近期面向Ultra会员开放),可以利用图片来控制人物一致性,然后再为这个角色添加声音,这个对未来的影像创作影响挺大的。
AI新榜:与之前的AI视频工具相比,Flow在创意表达和叙事上是否有明显的提升?
Junie:我认为我们正在进入AI视频制作的“第四个时代”。最初AI视频生成只有无声的画面,然后发展到“有声”,但那时候制作流程很复杂,并且需要我们在多个平台之间切换。
现在只需一个想法,通过自然语言描述,就能直接生成有台词、有声音的视频画面,还能保持人物形象和声音的一致性。
Flow还有一个“Extend”(延长)的功能,可以无限延长视频,并且保证角色形象的一致性。此外,我们也可以通过文字指令控制角色的下一步行动,甚至实现空间的快速切换,比如从火车场景跳转到草坪,再从草坪到外太空,只要指令不是过于离谱,它都可以实现。
AI新榜:制作这部9分钟的短片大概耗时多久?与谷歌团队的协作模式是怎样的?
Junie: 整个短片制作持续了三周,我们和谷歌团队保持了非常紧密的沟通节奏,几乎每两天就会召开一次会议。这些会议上他们分享了很多没有公开的技术文档和实操技巧(Tips and Tricks)。例如,使用Flow时如何保持场景、人物一致性等等。
AI新榜:是有偿合作吗?
Junie:是的,我个人还没有“无偿”工作过。
AI新榜:那和谷歌合作下来,最大的感受是什么?
Junie:在这次与谷歌团队的合作中,我不仅仅是Flow平台的使用者,更和他们的技术团队紧密合作、全程参与了Flow平台的设计与调优过程。
AI新榜:有什么具体的例子说明吗?
Junie:最开始Veo 2只有基础的文生视频、文生图和图生视频功能,之后才陆续上线了一些重要的新功能。
一个是Ingredient(元素)功能,它是利用Gemini的能力把用户上传的图片进行解析和“翻译”,作为元素融入到新生成的视频中。
另一个内部测试功能是,可以把人物和场景作为独立“元素”导入平台,并通过文字Prompt(指令)精确控制这些元素在视频中的运动和互动。例如,你可以指定一男一女在特定环境中做特定的动作。
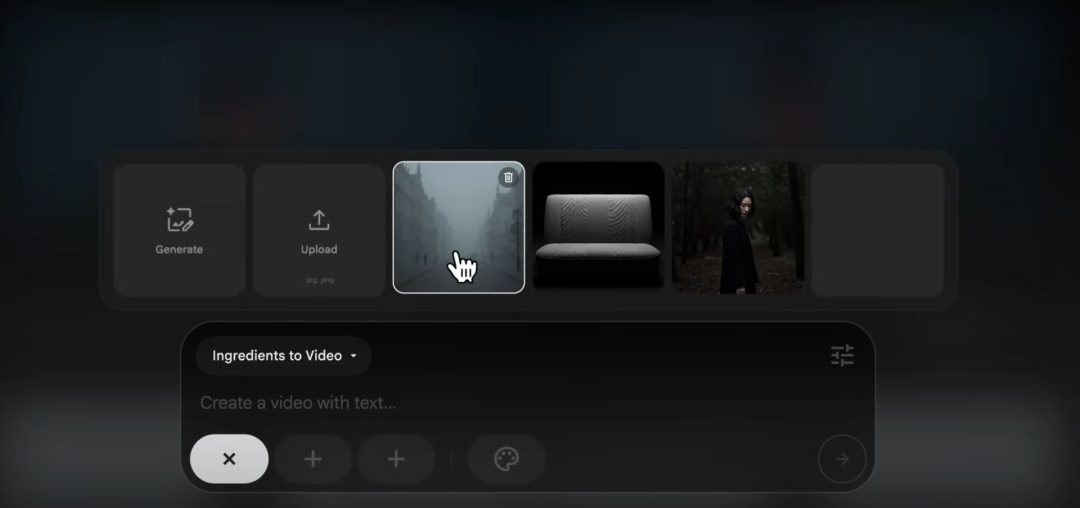
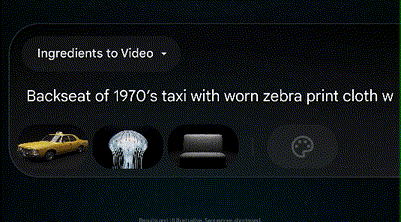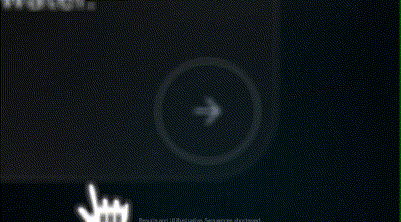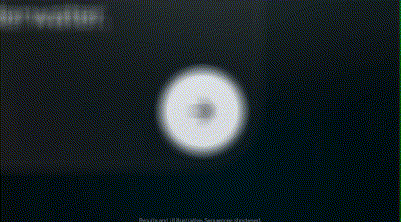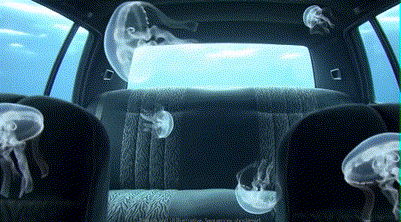
到了最后一周,一个比较重要的新功能是:它支持用户上传不同的图片作为元素,并通过自然语言指令控制这些不同图片元素在视频中的行为和相互作用。另外Flow平台上也加入了更多控制镜头移动和视角变化的能力。
AI新榜:你提到通过人物、场景等元素控制,这是否可以理解为类似“图层”的概念,可以独立控制单个元素?
Junie: 可以这样理解。不过,我认为无论是Veo 2还是Veo 3,它们的核心优势在于真实性,比市面上其他一些AI视频工具更偏向于真实感。在文字输入的层面,只要你的指令足够清晰详细,除非是非常刁钻的,模型都能比较准确地遵循。这种通过元素和文字指令结合进行控制的方式,确实提供了类似分层编辑的灵活性。
AI新榜:有什么使用技巧方便分享吗?
Junie:我个人认为,输入的指令越详细,Flow能生成的内容就越丰富、越符合预期。如果指令过于简单,比如只输入“一个人在走路”,那么生成的结果可能就会相对普通。
这就又引发另外一个点,我们如何生成详细的指令?
我觉得最好的办法就是配合Gemini来使用,其实Flow平台是基于Gemini的,用它生成指令的话,会更好地控制Veo 2。我觉得Flow TV这个平台还蛮有意思的,这也是我觉得和Sora差异最大的地方。
Flow TV上集合了五花八门的案例,你可以搜索具体的元素或风格,比如输入“绿色”,平台就会展示大量与“绿色”相关的、由其他用户或官方生成的优秀案例。这提供了一种更有针对性的、基于你创意意图的案例搜索方式。
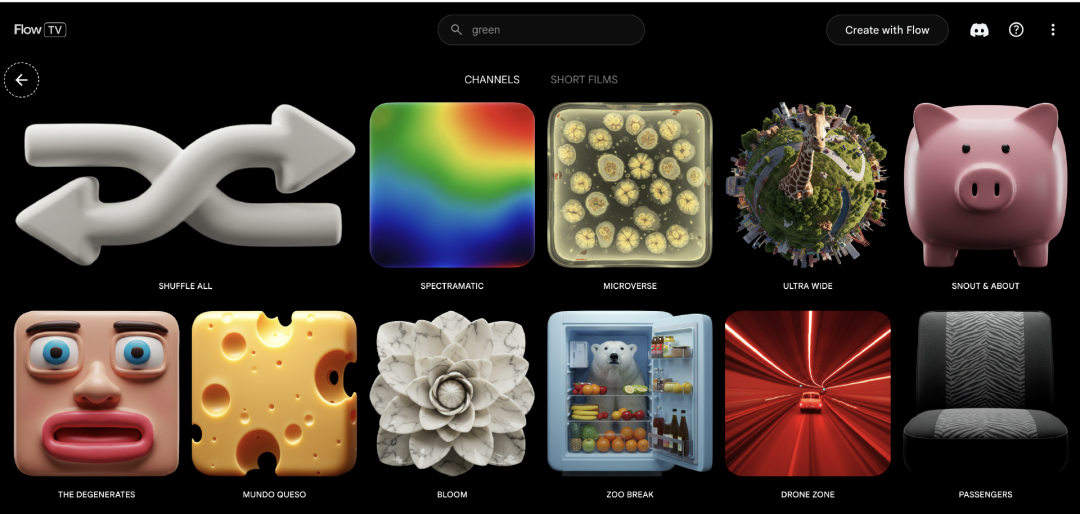
Flow TV:https://labs.google/flow/tv/channels
与Midjourney或Sora等平台过去那种更偏向于“功能展示”或随机案例的呈现方式不同,Flow TV允许用户通过关键词搜索来学习别人是如何通过Prompt实现某种特定效果。
AI新榜:从去年Sora上线之后,我们体感上会觉得今年AI视频的讨论度不如以往,你会有这样的感受吗?
Junie:我觉得是因为没有“好作品”出现。很多人还是过分关注“AI视频何时能媲美好莱坞”这样的问题上,一定程度上导致了行业内缺乏具有创新性的故事。实际上,现在的AI视频工具本身已经非常出色,只是还没有大量优秀的原创作品涌现。
我之前作为外部合作伙伴加入的生成式AI影视工作室Promise,我们会用AI和传统影视相结合的方式创作,比如通过AI模型和动捕技术来制作更具动态张力的打斗镜头。
https://www.promisestudios.com/;Promise是一家AI影视工作室,近期获得了来自a16z、谷歌以及North Road等资本投资,将与Google旗下DeepMind展开合作,在其自研平台“MUSE”中集成Gemini、Veo等最新模型。
现在很多影视创作者都在积极探索不同的镜头表达方式。之前,他们可能因资源和预算限制而难以施展自己的创意,但随着AI视频工具的迭代优化,他们可以实现自己真正想要表达的内容,我相信,我们会看到越来越多新鲜且具有不同视角的AI影视作品。
AI新榜:推荐一些你觉得“本身已经非常出色”的AI工具?
Junie:我个人觉得Flow、Sora都还蛮好用的,还有一个不能替代的AI工具是ElevenLabs。可能和创作习惯有关,我观察到很多创作者会使用的工作流是“AI生成脚本-文生图-图生视频-剪辑”,这或许是他们不太习惯Sora这类工具的原因,反而更倾向于可灵这种能精准执行预设指令的工具。
AI新榜:不用工作流的话,你给AI视频创作者的建议是什么?
Junie:多多探索,多多实验。我想探索新的艺术表达和叙述方式,所以我会觉得“重制”已有的东西是没有意义的,“创作”应该是动态的过程。你输入灵感给AI后,你们不断交流碰撞,再诞生整个剧本内容。
当然,艺术表达的方式很多元化,每个人对AI也会有不同的观点。比如有的人制作视频需要用AI降本增效,就要求它有强大的可控性,那可灵就很适合,这和每个人的使用喜好和习惯不同。
我最近听了《黑天鹅》导演Darren Aronofsky的讲座,他提到一个观点很有意思,他会希望AI视频工具能有一个“AI幻觉”功能——不是指错误或混乱,而是AI能够基于输入的图像或概念,进行独特的、非线性的视觉处理或抽象化重构,然后将这些“幻觉式”的处理结果返还给创作者。这个过程并非为了直接生成成品,而是旨在激发创作思路,打开新的视角和可能性。
从更宏观的角度看,AI工具的出现也鼓励创作者去讲述更多个人化、更贴近内心的故事。因为影视创作者所呈现的故事,是要和不同的人产生情感连接,这种连接是不同背景、不同经历的两个灵魂之间碰撞的过程。这样一个创作过程才是有意义的。
ps. 评论区留给你们,欢迎更多的朋友跟我们分享自己的AI创作体验。




「
(文:AI新榜)