


OpenAI 的 GPT-4o 在图像理解、生成和编辑任务上展现了顶级性能。流行的架构猜想是:
-
Tokens → [Autoregressive 模型] → [Diffusion 模型] → 图像像素
该混合架构将自回归与扩散模型的优势结合。Salesforce Research、马里兰大学、弗吉尼亚理工、纽约大学、华盛顿大学的研究者在最新的研究(统一多模态模型 BLIP3-o)中也采用了自回归 + 扩散框架。

-
论文标题:BLIP3-o: A Family of Fully Open Unified Multimodal Models—Architecture, Training and Datase
-
论文地址:https://arxiv.org/pdf/2505.09568v1
-
GitHub 代码:https://github.com/JiuhaiChen/BLIP3o
-
模型权重:https://huggingface.co/BLIP3o/BLIP3o-Model
-
在线演示:https://huggingface.co/spaces/BLIP3o/blip-3o
-
预训练:https://huggingface.co/datasets/BLIP3o/BLIP3o-Pretrain-Long-Caption
-
指令微调:https://huggingface.co/datasets/BLIP3o/BLIP3o-60k
在这个框架里,自回归模型先生成连续的中间视觉特征,用以逼近真实图像表示,进而引出两个关键问题:
-
真实特征来源 (Ground-truth features):用 VAE 还是 CLIP 将图像编码为连续特征?
-
特征对齐方式:使用 MSE 损失,还是借助扩散模型(Flow Matching)来对齐预测与真实特征?
统一多模态下的图像生成
研究者考察两种图像编码–解码范式:
-
VAE:将图像编码为 low level 像素特征,以获得更好的重建质量。但 VAE 编码器在处理更高分辨率输入时,会生成更长的向量序列,从而增加训练过程中的计算负担。
-
CLIP + Diffusion:先将图像映射到 high level 语义特征,再通过扩散模型重建真实图像。在实际操作过程中,会先用 CLIP 得到图像特征,然后基于 CLIP feature 训练一个扩散模型来重建图像。该方法好处是无论输入图像分辨率如何,每张图像都可编码为固定长度的连续向量 (比如长度为 64 的向量),这种编码方式能有较好的图像压缩率;但需要额外训练来使扩散模型适配不同的 CLIP 编码器。
针对自回归模型预测的视觉特征与 VAE/CLIP 提供的真实特征,有两类训练目标:
-
MSE:对预测特征与真实特征计算均方误差
-
Flow Matching:基于自回归模型生成的预测特征,通过流匹配损失训练一个 Diffusion Transformer,用 Diffusion Transformer 的输出值来逼近 CLIP 或 VAE 特征
结合不同的编码–解码架构与训练目标,共有三种设计选择:
-
CLIP + MSE:最小化预测表征与 CLIP 真实表征之间的 MSE, 比如 Emu2、SeedX。在生成图片的时候,自回归模型生成视觉特征,基于这个视觉特征,使用一个扩散模型来解码图片。
-
CLIP + Flow Matching:以自回归模型预测的视觉特征为条件,使用流匹配损失来训练 Diffusion Transformer,以预测真实的 CLIP 表征。在生成图片的时候,自回归模型生成视觉特征,基于这个视觉特征,Diffusion Transformer 生成一个 CLIP feature,然后再基于这个 CLIP feature,使用一个轻量的扩散模型来解码图片。整个过程涉及两次扩散过程,第一次生成 CLIP feature,第二次生成真实图片。
-
VAE + Flow Matching:以自回归模型预测的视觉特征为条件,使用流匹配损失来训练 Diffusion Transformer,以预测真实的 VAE 表征。在生成图片的时候,自回归模型生成视觉特征,基于这个视觉特征,Diffusion Transformer 生成一个 VAE feature, 由 VAE 解码器来生成真实图片。
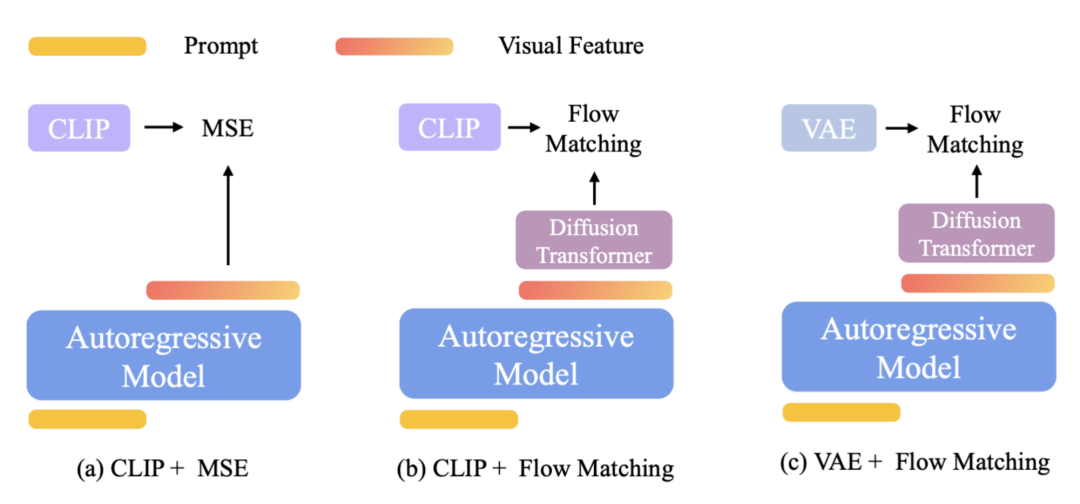
Caption: 在统一多模态模型中,图像生成有三种设计方案。所有方案均采用自回归 + 扩散框架,但在图像生成组件上各有不同。对于流匹配损失,保持自回归模型冻结,仅微调图像生成模块 (Diffusion Transformer),以保留模型的语言能力。
下图对比了这三种方案在相同设置下的表现,证明 CLIP + Flow Matching 能在提示对齐、图像多样性与视觉质量之间取得最佳平衡。
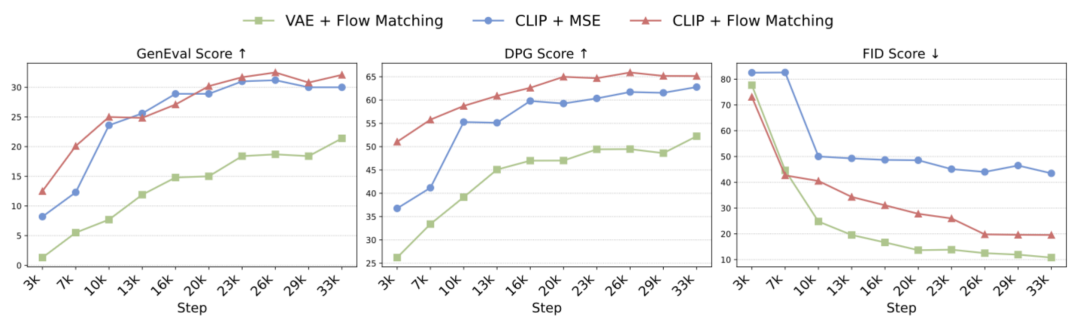
Caption: 不同方案的对比
研究者发现将图像生成集成到统一模型时,自回归模型对语义级特征(CLIP)的学习比对像素级特征(VAE)的学习更为高效。同时,将流匹配 (Flow Matching)作为训练目标能够更好地捕捉图像分布,从而带来更丰富的样本多样性和更出色的视觉质量。同时有两个阶段的扩散过程,相对于传统的一个阶段的扩散模型,将图像生成分解成了两个阶段,第一阶段自回归模型和 diffusion transformer 只负责生成语义特征,第二阶段再由一个轻量的扩散模型来补全 low-level 特征,从而大幅减轻训练压力。
统一图像理解与生成
通过 CLIP 编码器,图像理解与图像生成共用同一语义空间,实现了两者的统一。
研究者采用顺序训练(late fusion)而非联合训练(early fusion),原因在于:
-
可以冻结自回归模型,保留其图像理解能力;
-
把全部训练资源集中在图像生成模块,避免多任务间的相互干扰。
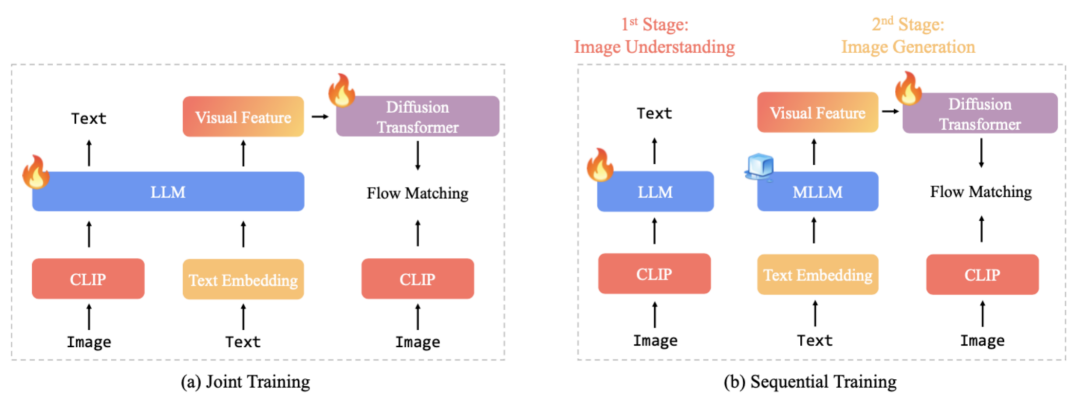
caption:联合训练(early fusion)同时更新理解和生成模块,顺序训练 (late fusion)先独立调优「理解」,再冻结骨干只训练「生成」。
BLIP3-o:统一多模态模型
基于上述对比,研究者选定 CLIP + Flow Matching 与顺序训练 (late fusion),构建了 4B 和 8B 参数的 BLIP3-o:
-
预训练数据:25M 开源图文 + 30M 专有图像
-
图像字幕 (caption):均由 Qwen-2.5-VL-7B-Instruct 生成,平均 120 token;为增强对短提示的适应,还额外混入~10%(6M)的短字幕(20 token)
-
4B 参数开源模型:纯 25M 开源图文对,及~10%(3M)短字幕
-
指令微调:GPT-4o 生成 60K 条高质量示例,显著提升提示对齐和视觉美感
所有代码、模型、数据均陆续开源中,欢迎试用!

Caption: BLIP3-o 可视化示例
研究者发现:
模型能迅速调整至 GPT-4o 风格,提示对齐 (instruction following) 和视觉质量均大幅提升。
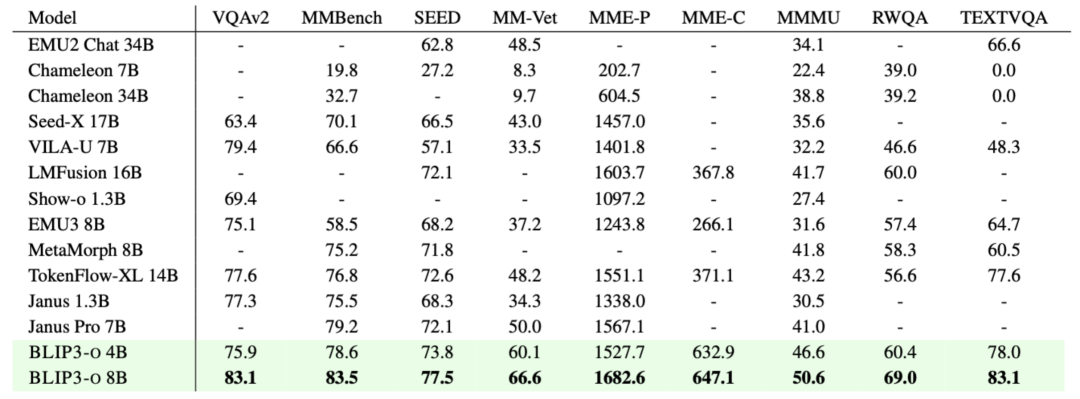
caption:图像理解表现
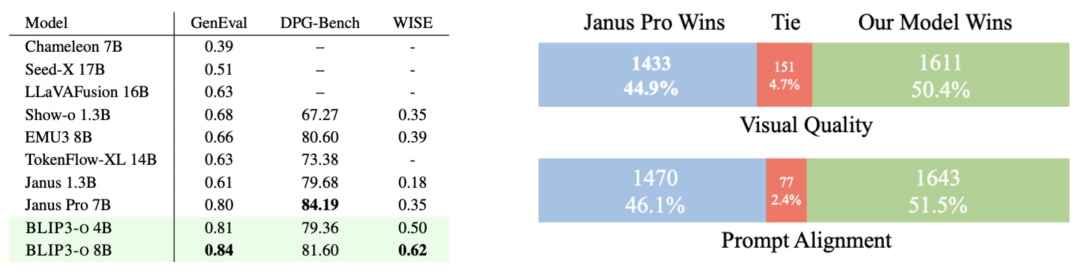
Caption: 图像生成的基准性能与人工评估
结论
本文首次系统地探索了结合自回归与扩散架构的统一多模态建模,评估了三个关键维度:图像表示(CLIP 特征 vs. VAE 特征)、训练目标(流匹配 vs. MSE)和训练策略(early fusion vs. 顺 late fusion)。实验结果表明,将 CLIP 嵌入与流匹配损失相结合,不仅加快了训练速度,也提升了生成质量。
基于这些发现,本文推出了 BLIP3-o, 一系列先进的统一多模态模型,并通过 BLIP3o-60k 6 万条指令微调数据集,大幅改善了提示对齐效果和视觉美感。研究者还正在积极开展该模型的应用研究,包括迭代图像编辑、视觉对话和逐步视觉推理。

©
(文:机器之心)