



5月20日,在最新一期百度AI Day活动上,百度集团副总裁吴甜、中国信息通信研究院人工智能研究所平台与工程化部主任曹峰等分享了文心4.5 Turbo和X1 Turbo大模型的最新技术创新点、全球大模型发展趋势及测评结果等内容。

据中国信通院发布的大模型推理能力评估结果显示,百度文心X1 Turbo在24项能力评估中,16项达5分、7项达4分、1项达3分,综合评级获当前最高级“4+级”,成为国内首款通过该测评的大模型。
活动现场,百度集团副总裁吴甜对文心大模型最新版本的技术创新进行了讲解。
她介绍,文心4.5和4.5 Turbo实现了文本、图像和视频的混合训练。针对不同模态数据在结构、规模、知识密度上的差异,通过多模态异构专家建模、自适应分辨率视觉编码、时空重排列的三维旋转位置编码、自适应模态感知损失计算等技术,大幅提升跨模态学习效率和多模态融合效果,学习效率提高近2倍,多模态理解效果提升超过30%。

后训练方面,百度研制了自反馈增强的技术框架,基于大模型自身的生成和评估反馈能力,实现了“训练-生成-反馈-增强”的模型迭代闭环,显著降低了模型幻觉,模型理解和处理复杂任务的能力大幅提升。
在训练阶段,通过融合偏好学习的强化学习技术,实现多元统一奖励机制,提升了对结果质量判别的准确率。
深度思考方面,突破了仅基于思维链优化的范式,在思考路径中结合工具调用,构建了融合思考和行动的复合思维链,模型解决问题能力得到显著提升,模型输出结果思路清晰、逻辑严密,表达自然。
数据方面,打造了“数据挖掘与合成-数据分析与评估-模型能力反馈”的数据建设闭环,为模型训练源源不断地生产知识密度高、类型多样、领域覆盖广的大规模数据。同时,数据建设流程具备良好的可扩展性,能够轻松迁移到全新的数据类型,实现快速、高效的数据生产。
此外,吴甜指出,大模型的能力进一步拓展、效率进一步提升之后,可以探索更前瞻、更有想象力的创新应用,现场展示了“剧本”驱动多模协同的超拟真数字人技术,可实现语言、声音、形象的协调一致,据悉,目前这套技术已经支持超过10万数字人主播,直播转化率达31%,降低80%直播开播成本。
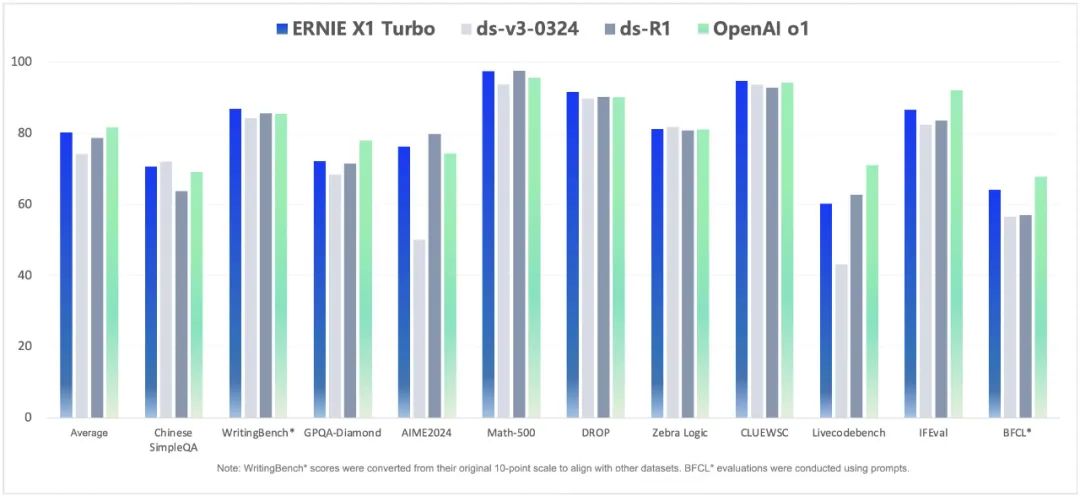
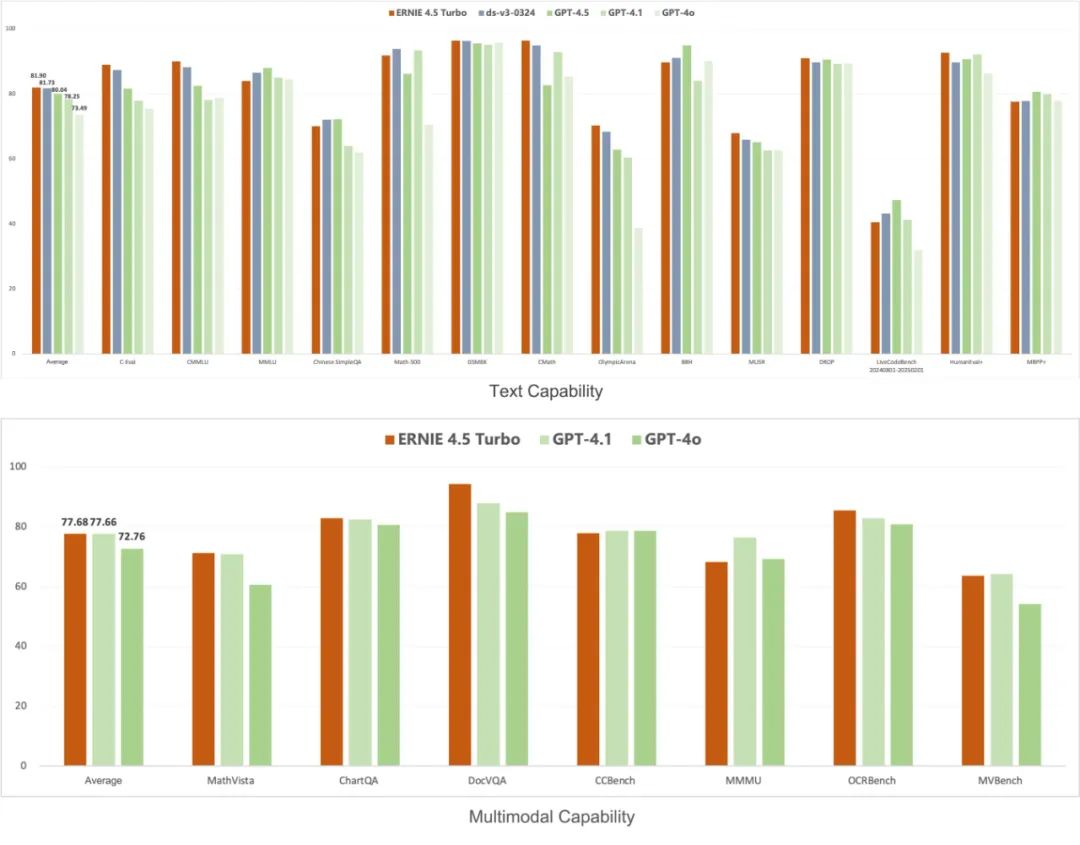
据公开信息了解,目前X1 Turbo输入价格为每百万代币1元,输出价格为每百万代币4元,价格约为DeepSeek R1的25%;4.5 Turbo的输入价格仅为每百万代币0.8元,输出价格为每百万代币3.2元,比DeepSeek V3低约40%,可谓性价比满满。
不过,目前国内外大模型领域的竞争已经重回大厂之间的巅峰较量,PK的不仅是性价比,也在模型的先进程度上展开了激烈交锋,国产大模型在英伟达先进AI算力受限的背景下,如何进行持续创新缩小与OpenAI、谷歌等最先进模型之间的差距仍有不少功课要做。
百度作为国内AI大模型头部厂商之一,未来会如何通过技术创新推动行业进步十分值得关注和期待。
-END-

(文:头部科技)