
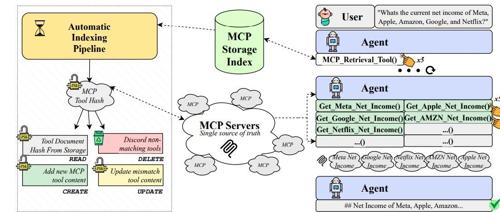
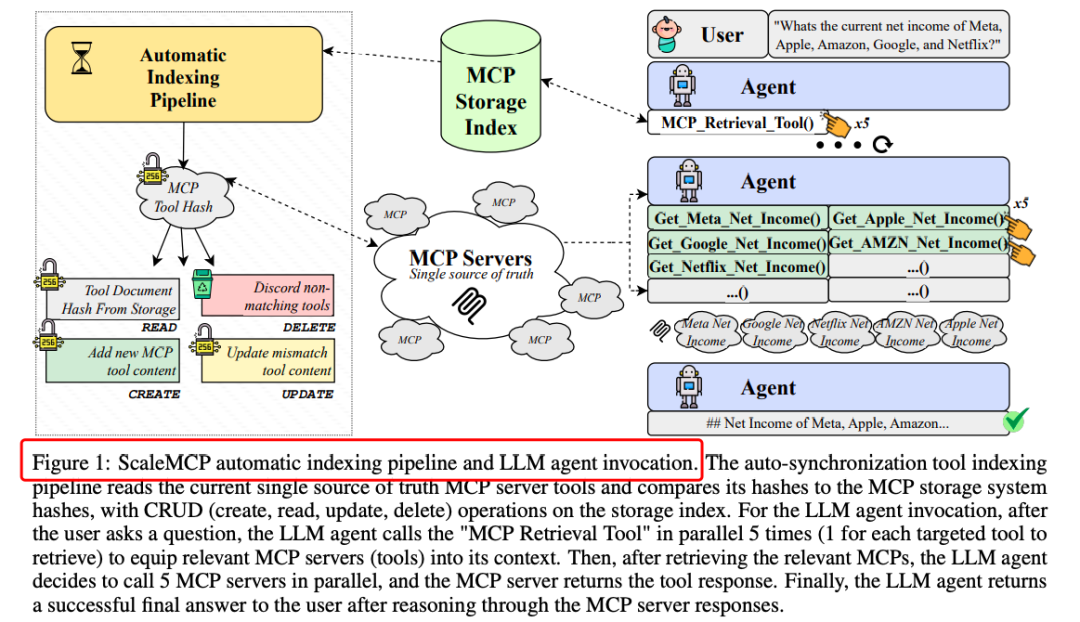

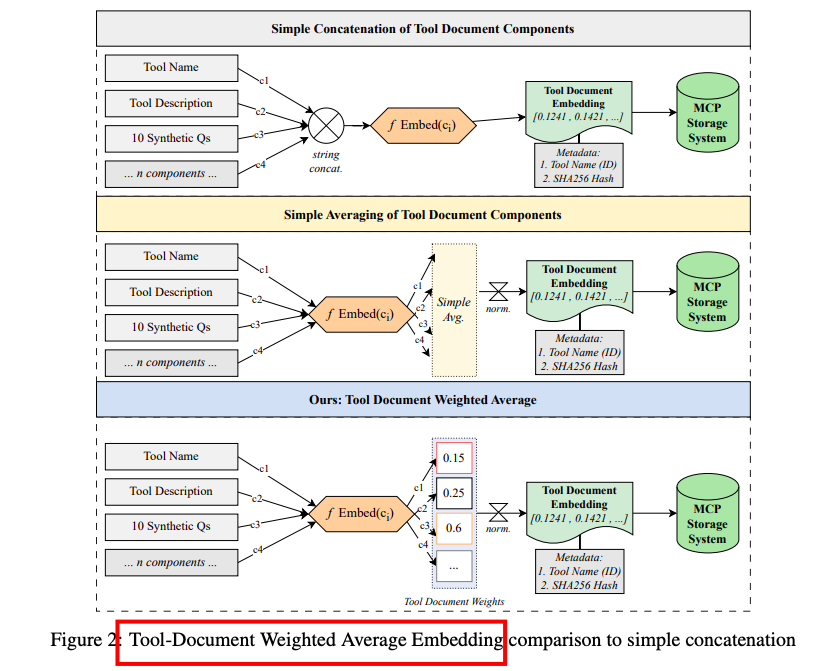
数据集构建
-
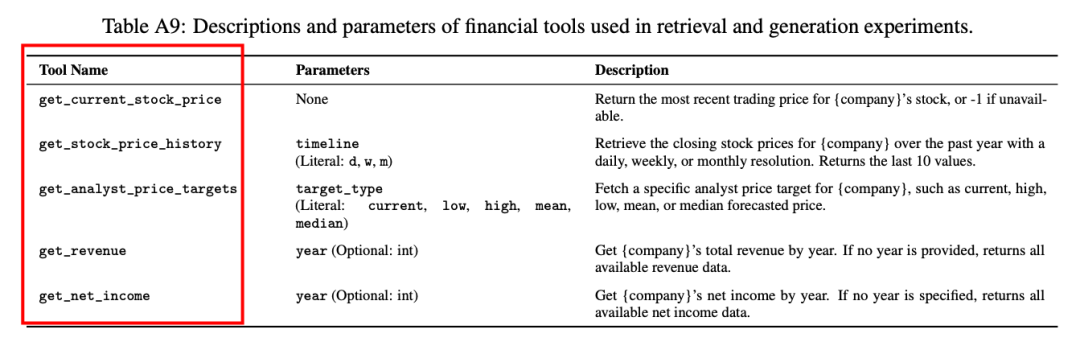
工具创建:基于《财富》1000强公司,为每家公司生成了5个确定性的工具,涉及股票价格、分析师目标价、收入和净收入等财务指标。
-
工具文档合成问题:为每个工具模板生成了0、5或10个合成问题,以丰富工具文档的语义表示。
-
用户查询实例生成:创建了约140,000个用户查询实例,覆盖了广泛的财务任务和公司。

实验1:MCP向量数据库检索
-
设置:在5,000个MCP服务器的数据集上评估了5种嵌入模型和5种检索器类型,使用简单拼接策略存储工具表示。
-
结果:单纯向量检索表现不佳,而使用Cohere的跨编码器重排序器和LLM重排序器(如GPT-4o和Claude Sonnet 3.7)显著提升了性能。在VertexAI嵌入模型和GPT-4o重排序器下,Recall@10达到0.94,MAP@10达到0.59。

实验2:LLM代理评估
-
设置:使用DeepEval框架评估了10种LLM代理在检索和工具调用任务上的端到端性能。
-
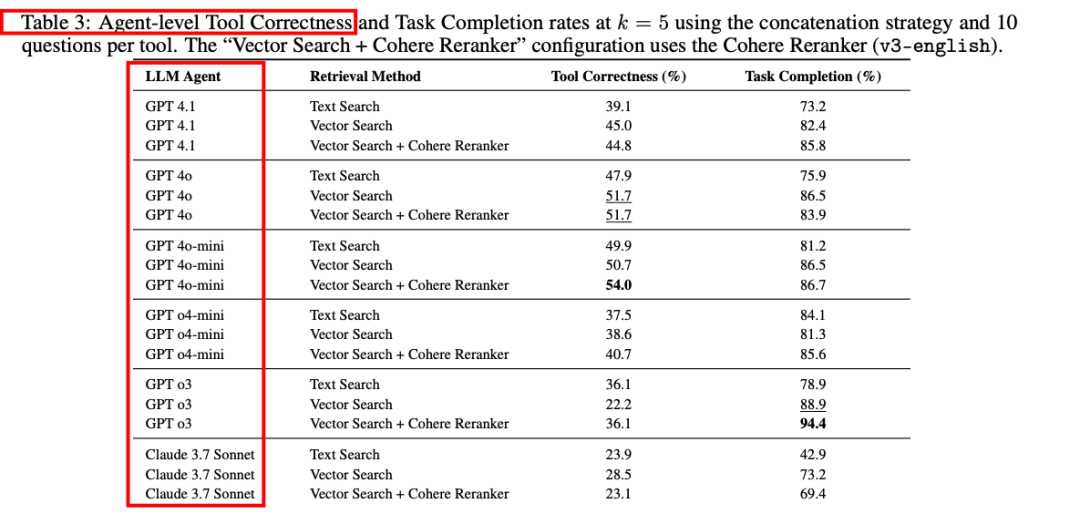
结果:gpt-o3在使用向量搜索和Cohere重排序器时,Task Completion Score达到94.4%,但Tool Correctness仅为36.1%。gpt-4o-mini在相同配置下平衡了Tool Correctness(54.0%)和Task Completion Score(86.7%)。
实验3:TDWA权重评估
-
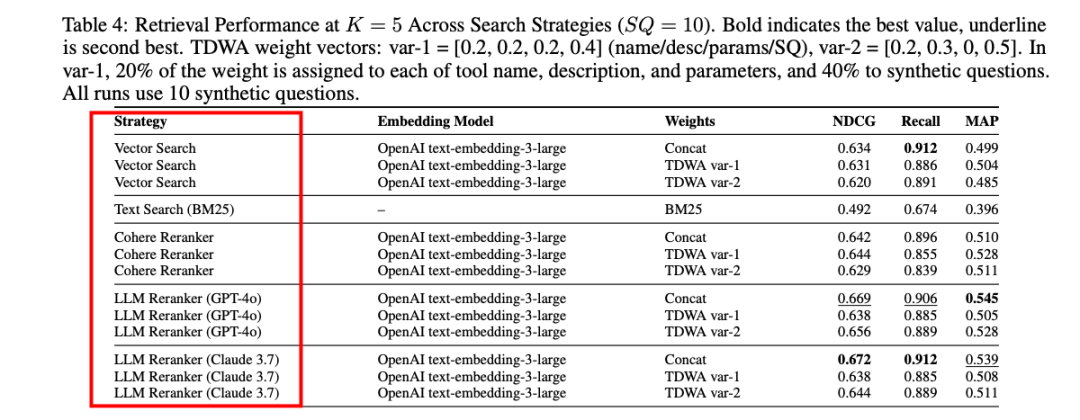
设置:比较了简单拼接(Concat)和两种TDWA变体(var-1和var-2)在不同检索策略下的性能。
-
结果:在纯向量搜索中,Concat策略表现优于TDWA,但在重排序后,TDWA var-2在某些重排序指标上优于Concat,表明TDWA在语义相关性方面具有优势。
-
ScaleMCP通过自动同步工具存储系统和TDWA嵌入策略,显著提升了LLM代理在工具选择和调用方面的性能。
-
在复杂多跳查询中,LLM代理需要更灵活的检索和推理能力,ScaleMCP框架通过引入动态检索工具,为代理提供了更好的工具管理能力。
-
TDWA策略在重排序阶段表现出色,尤其是在与LLM重排序器结合时,能够更好地捕捉工具文档的语义信息。

https://arxiv.org/pdf/2505.06416SCALEMCP: DYNAMIC AND AUTO-SYNCHRONIZING MODEL CONTEXT PROTOCOL TOOLS FOR LLM AGENTS
(文:PaperAgent)