


近年来,生成式人工智能的快速发展,在文本和图像生成领域都取得了很大的成功。视频生成作为 AIGC 的重要研究内容,在影视制作、短视频合成和虚拟仿真等方面都有应用价值。现有的商用和开源的视频生成模型,都能根据文本或图像输入生成高质量的视频片段。
但是,仅依赖文本作为输入,用户难以精确控制几何细节和场景布局;若引入额外图像输入,则面临如何获取输入图像、难以精确控制运动信息等问题。此外,在给定已有视频片段后,如何对局部区域进行二次修改,并让新生成的画面与原始视频保持空间与时序一致,是亟待解决的问题。
近期,中国科学院大学,香港科技大学和快手可灵团队研究人员提出了一种基于线稿的可控视频生成和编辑方法 SketchVideo [1],相关技术论文发表于 CVPR 2025。这一方法助力每一个人成为 AI 时代下的绘画影视大师,通过寥寥数笔即可生成栩栩如生的动态视频结果。无论是从零开始生成视频,还是在真实视频上做局部创意编辑,SketchVideo 都能让你轻松驾驭动态画面,释放创作潜能。
-
论文标题:SketchVideo: Sketch-based Video Generation and Editing
-
arXiv 地址:https://arxiv.org/pdf/2503.23284
-
项目主页:http://geometrylearning.com/SketchVideo/
-
GitHub 地址:https://github.com/IGLICT/SketchVideo
-
视频 demo:https://www.youtube.com/watch?v=eo5DNiaGgiQ
先来看看使用 SketchVideo 的视频生成和编辑的效果!

图 1 基于线稿的视频生成结果

图 2 基于线稿的视频编辑结果
Part1 背景
近年来,AI 视频生成模型,如 Sora [2]、可灵 [3](商用模型)和 CogVideo [4]、Wan [5](开源模型)等,发展非常迅速。这些模型以文本及图像作为输入生成高质量视频,但在可控性和编辑性等方面有仍有提升空间。
线稿作为一种直观且易于使用的交互方式,已广泛应用于各类生成任务。早期研究 [6] 将线稿引入生成对抗网络(GAN),以生成特定类别的图像。随着扩散模型的发展,线稿控制也被引入到文生图模型中,如 Stable Diffusion [7]。其中,ControlNet [8] 是一项代表性工作,它基于 UNet 结构,通过复制 UNet 中的编码器作为控制网络,用于提取线稿特征,从而实现对几何细节的有效控制。
然而,视频生成模型在显存占用和计算开销方面远高于图像生成模型,且通常采用 DiT 架构 —— 由一系列 Transformer 模块串联而成,缺少编码器和解码器结构。这使得直接将 ControlNet 方法迁移至视频生成模型 [9] 面临挑战:一是没有明确的编码器可用作控制网络,二是复制大规模参数会带来过高的资源消耗。此外,让用户为视频的每一帧绘制线稿并不现实,因此更合理的做法是仅绘制一帧或两帧关键帧。但如何将这些关键帧的控制信号有效传播至整段视频,仍是亟需解决的技术难题。
相比视频生成,基于线稿的视频编辑更侧重于对局部区域的修改,要求生成结果与周围区域在空间和时间上保持一致,同时确保非编辑区域的内容不被破坏。现有方法多采用文本驱动的方式进行视频编辑 [10],或通过传播第一帧的编辑结果到整段视频 [11]。然而,这些方法主要聚焦于整体风格变化,对于实现精确的局部几何编辑存在不足,仍需进一步探索。
Part2 算法原理
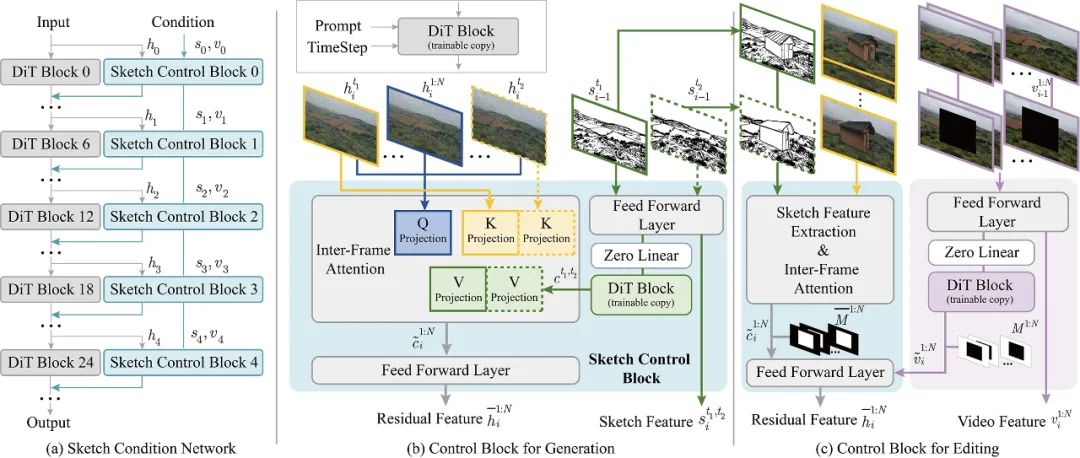
图 3 SketchVideo 的网络架构图,生成和编辑流程
该工作基于预训练的视频生成模型 CogVideo-2B(图 3a 灰色部分),在其基础上添加了可训练的线稿控制网络(图 3a 蓝色部分),用于预测残差特征,从而实现基于线稿的可控视频生成。不同于 PixArt-δ[12] 中通过复制前半部分的 DiT 模块构建控制网络的做法,该工作提出了一种跳跃式残差控制结构:将条件控制模块以固定间隔均匀嵌入至预训练模型的不同层次,分别处理不同深度的特征,提升控制能力的同时降低冗余计算。具体而言,线稿控制模块 0 的权重初始化自原始模块 0,模块 1 初始化自模块 6,依此类推。该设计在显著减少参数开销的同时,仍保持了良好的控制效果。
在视频生成阶段,用户可输入一帧或两帧关键帧线稿,并指定其对应的时间点,以控制视频在特定时刻的几何细节和视频整体的运动状态。为了将这些关键帧的控制信息有效传播至整段视频,该方法引入了帧间注意力机制(图 3 b):先通过一组由原始视频生成模型初始化的可训练 DiT 模块(DiT Block (trainable copy))提取关键帧的控制特征,再利用帧间相似性引导控制信号以稀疏方式向其他帧传播,最后通过前馈网络生成所有帧的残差控制特征,实现时序一致的线稿引导生成。
在视频编辑阶段,控制网络除线稿外,还需额外接收原始视频及随时间变化的矩形掩码,用于标记编辑区域。在生成控制模块的基础上,该方法新增了视频嵌入模块(图 3c),用于提取非编辑区域的原始视频信息,确保编辑结果在空间和时间上与周围内容协调一致。由于原始视频不具备时间稀疏性,视频嵌入模块未采用帧间注意力机制。在推理阶段,该方法还引入局部融合策略,在隐空间中融合原始视频与编辑结果,实现对非编辑区域内容的精确保留。
在训练方面,该方法使用配对的线稿和视频数据进行训练,并额外引入线稿与静态图像对,提升线稿控制网络在不同场景下的泛化能力。对于视频编辑任务,网络初始化使用基于线稿的视频生成模型的权重,并引入随机生成的掩码模拟实际编辑过程,从而训练出具备高质量编辑能力的模型。
Part3 效果展示
如图 4 所示,用户可以绘制单帧线稿,并额外输入文本描述,该方法可以生成高质量的视频结果。合成的视频结果在指定的时间点与线稿存在较好的对应性,并且具有良好的时序一致性。

图 4 基于单帧线稿的视频生成结果
如图 5 所示,用户也可以绘制两帧线稿,该方法也可以生成高质量的视频结果。通过两个关键帧输入,用户不仅可以控制场景布局和几何细节,也可以控制物体的运动状态,实现视频的定制化生成。

图 5 基于两帧线稿的视频生成结果
如图 6 所示,给定真实的视频后,用户可以指定编辑区域,并额外绘制线稿对局部进行修改。该方法生成逼真的视频编辑效果,新生成的内容会随着非编辑区域的运动(如树枝的移动、头部旋转)一起变化,从而生成自然的视频结果。

图 6 基于单帧线稿的视频编辑结果
如图 7 所示,与视频生成类似,用户在视频编辑的过程中,也可以绘制两个关键帧对应的线稿,从而控制新添加物体的运动状态,该方法依然生成较为真实的视频编辑效果。

图 7 基于两帧线稿的视频编辑结果
Part4 结语
随着大模型和生成式人工智能的迅速发展,AI 绘画的能力已从静态图像延伸至动态视频的生成。相较于生成二维图像,如何基于关键帧的手绘线稿,精准控制视频中物体的几何细节与运动轨迹,成为重要的研究问题。SketchVideo 提出了一种有效的解决方案,通过线稿引导实现高质量的视频的生成和编辑,提高视频合成的可控性。
借助该方法,用户无需掌握复杂的专业视频处理软件,也不比投入大量时间和精力,仅凭几笔简单的线稿勾勒,便可以将想象变为现实,得到真实灵动的动态艺术作品。SketchVideo 工作已经被 CVPR 2025 接受。
参考文献:
[1] Feng-Lin Liu, Hongbo Fu, Xintao Wang, Weicai Ye, Pengfei Wan, Di Zhang, Lin Gao*. “SketchVideo: Sketch-based Video Generation and Editing.” CVPR 2025
[2] https://openai.com/sora/
[3] https://www.klingai.com/cn/
[4] Yang, Zhuoyi, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang et al. “Cogvideox: Text-to-video diffusion models with an expert transformer.” arXiv preprint arXiv:2408.06072 (2024).
[5] Wang, Ang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu et al. “Wan: Open and advanced large-scale video generative models.” arXiv preprint arXiv:2503.20314 (2025).
[6] Wang, Ting-Chun, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. “High-resolution image synthesis and semantic manipulation with conditional gans.” CVPR 2018.
[7] Rombach, Robin, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. “High-resolution image synthesis with latent diffusion models.” CVPR 2022.
[8] Zhang, Lvmin, Anyi Rao, and Maneesh Agrawala. “Adding conditional control to text-to-image diffusion models.” ICCV 2023.
[9] Guo, Yuwei, Ceyuan Yang, Anyi Rao, Maneesh Agrawala, Dahua Lin, and Bo Dai. “Sparsectrl: Adding sparse controls to text-to-video diffusion models.” ECCV 2024.
[10] Cheng, Jiaxin, Tianjun Xiao, and Tong He. “Consistent video-to-video transfer using synthetic dataset.” ICLR 2024
[11] Ku, Max, Cong Wei, Weiming Ren, Huan Yang, and Wenhu Chen. “Anyv2v: A plug-and-play framework for any video-to-video editing tasks.” arXiv e-prints (2024): arXiv-2403.
[12] Chen, Junsong, Yue Wu, Simian Luo, Enze Xie, Sayak Paul, Ping Luo, Hang Zhao, and Zhenguo Li. “Pixart-{\delta}: Fast and controllable image generation with latent consistency models.” arXiv preprint arXiv:2401.05252 (2024).

©
(文:机器之心)