


自回归(AR)范式凭借将语言转化为离散 token 的核心技术,在大语言模型领域大获成功 —— 从 GPT-3 到 GPT-4o,「next-token prediction」以简单粗暴的因果建模横扫语言领域。但当我们将目光转向视觉生成,却发现这条黄金定律似乎失效了……
现有方案硬生生将图像网格化为空间 token,强行塞入自回归架构。这像极了 NLP 早期用 CNN 建模语言的弯路 —— 当视觉表达被空间局部性束缚,因果链被切割得支离破碎,如何能真正拥抱 AR 的本质?
华为盘古多模态生成团队破局思路:让图像学会「说 AR 的语言」。团队指出:视觉要想复刻 LLM 的成功,必须彻底重构 token 化范式!基于昇腾 AI 基础软硬件的 Selftok 技术,通过反向扩散过程将自回归先验融入视觉 token,让像素流转化为严格遵循因果律的离散序列。

-
项目主页:https://Selftok-team.github.io/report/
-
ArXiv 链接:https://arxiv.org/abs/2505.07538
-
Github链接: https://github.com/selftok-team/SelftokTokenizer
Selftok 的突破在于:
-
反向扩散锻造因果 token—— 通过扩散过程的时序分解,让视觉表达彻底 AR 化
-
强化学习友好型 token—— 首个严格满足贝尔曼方程 (Bellman Equation) 的视觉离散表征
-
纯 AR 大一统架构 —— 无需复杂模块堆叠,优雅地实现 LLM 和 diffusion 的融合,单凭 next-token prediction 统一跨模态生成
实验结果实现:
-
视觉重建新突破:Imagenet 上重建指标达到离散 token SoTA
-
跨模态生成新高度:无需图文对齐数据!仅凭视觉 token 策略梯度,GenEval 生成质量超越 GPT-4o
-
亲和昇腾计算架构:昇腾原生算子融合 + MindSpeed 框架,实现端到端原生开发
值得一提的是,该系列工作的开篇论文《Generative Multimodal Pretraining with Discrete Diffusion Timestep Tokens》也入选了 CVPR 2025 最佳论文候选(Best Paper Candidate, 14/13008,0.1%)。
介绍
当前行业共识认为大语言模型(LLMs)正面临语言数据瓶颈,而图像、视频等非语言数据仍存在巨大开发潜力。技术圈普遍认为,构建统一的多模态架构将是释放 AI 更强涌现能力的关键。要将视觉等非语言模态整合进类似 LLMs 的离散自回归模型(discrete AR,dAR),核心挑战在于将连续视觉信号转化为离散 Token。华为盘古多模态生成团队首创不依赖空间先验的视觉 Token 方案,通过与语言模态联合训练构建视觉 – 语言模型(VLM),在图像生成、图像编辑等任务中展现出卓越能力。其强化学习优化后的生成性能已超越 AR 范式现有模型,开创了多模态自回归训练的新范式。
为何选择离散化视觉 token?当前主流方案采用语言 dAR 与图像连续自回归模型(continuous AR, cAR)的混合架构,认为连续表征能最小化图像压缩损失。但大量研究表明:离散表征同样可保持高精度,而连续表征存在三重致命缺陷:其一,预测稳定性差,cAR 采用均方误差(MSE)训练的向量回归器较 dAR 的交叉熵(XE)分类器更易出错,这迫使多数 cAR 放弃因果预测范式,转向双向建模,从根本上违背 decoder-only 架构的自回归设计哲学;其二,强化学习复杂度激增,连续状态 – 动作空间使马尔可夫决策过程从有限转为无限,策略优化难度呈指数级上升;其三,解耦能力受限,连续表征在学习过程中会带来模式坍缩 (视觉幻觉),离散可以实现因子更好的解耦。
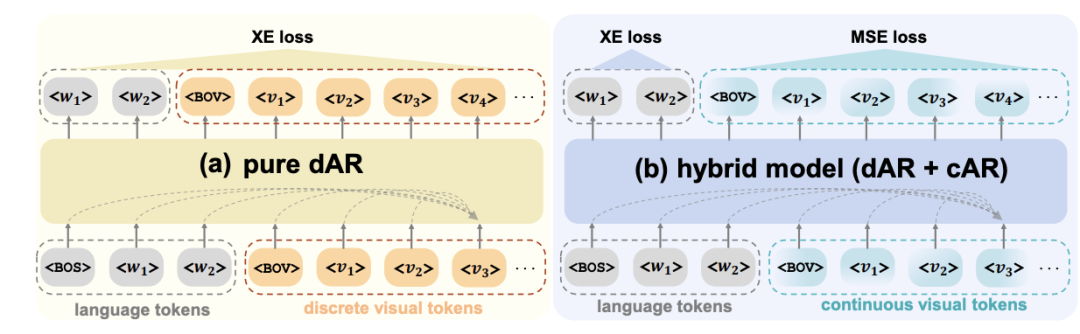
图 1
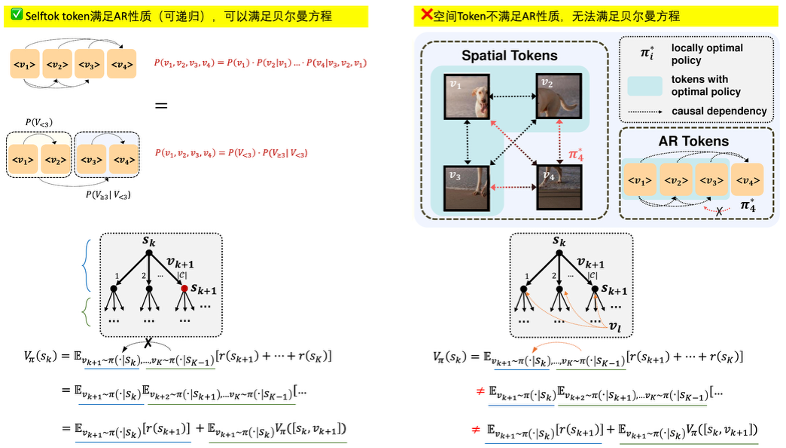
为什么选择摒弃空间先验?早期 CV 研究将空间特征 Token 化视为自回归建模标配,但华为 AIGC Selftok 团队指出:空间 Token 的因果依赖本质与 AR 范式存在根本冲突。如下图所示,碰撞效应导致虚假依赖,编码任一空间 Token 时引入与其他所有 Token 的贝叶斯伪相关,破坏 AR 所需的因果图结构;从而导致强化学习失序,非 AR 依赖使 Token 预测影响历史状态,无法满足贝尔曼方程,导致策略优化陷入局部最优困境。实验证明,非空间 Token 的 RL 效果上限显著低于 AR Token。
基于此,Selftok 团队提出 Self-consistency Tokenizer:通过扩散模型反向过程的 AR 特性编码图像生成轨迹,每个 Token 对应扩散步骤的时间戳(如图 3)。
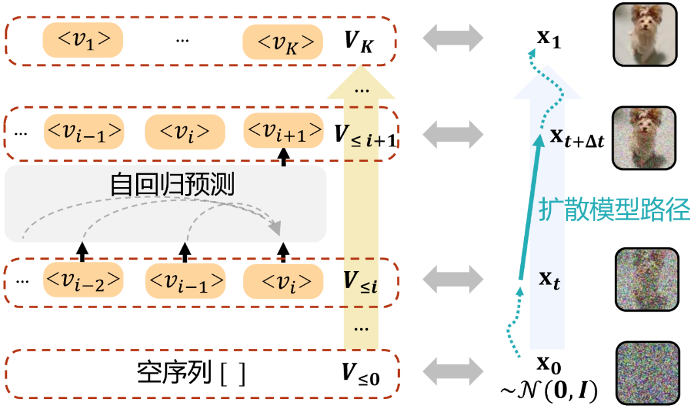
图 3
该方案实现三大突破:
1)AR 原生架构(自回归之本):彻底摒弃空间先验,保持重建精度同时提升图文模态兼容性,为 dAR-VLM 预训练与 RL 微调奠定基础;
2)扩散范式统一(扩散之法):直接贯通扩散模型与自回归架构,无需额外模块即可完成跨模态统一。自回归等价于递归,可像归并排序算法(下左图)一样分而治之。同理,将 x_0→x_1(下右图)的路径分解成两部分,x_0→x_t 由扩散模型采样得到,x_t→x_1 学习 token;
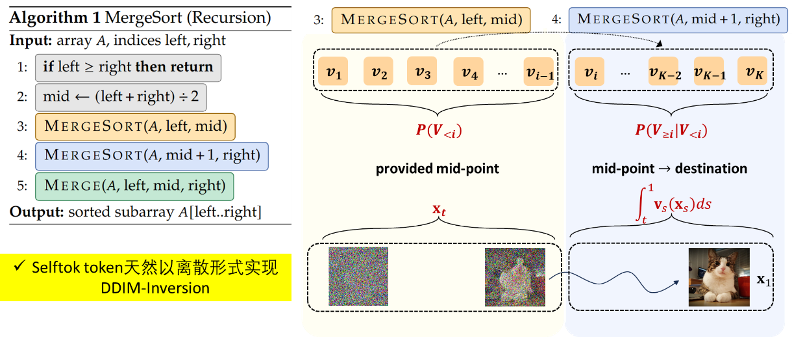
图 3.1
3)推理性能跃升(推理之用):Selftok-Token 完美适配策略优化,使 dAR-VLM 获得类 LLM 的 RL 训练能力。实验证明,无监督的 Selftok-Zero 在 GenEval 和 DPG-Bench 榜单分别以 92% 和 85.57 分超越基于 Spatial token 的 AR 范式模型,验证了 Selftok token 与 AR 范式的组合威力。
方法简述
Tokenizer: Selftok tokenizer 主要由三部分构成:encoder,quantizer 与 decoder。整体的结构如图 4 所示:

图 4
Selftok 编码器采用双流架构:图像分支继承 SD3 的 VAE 隐空间编码,文本分支创新性替换为可学习连续向量组以捕捉扩散特征,通过动态掩码机制提升计算效率。核心量化器通过 EMA 更新的 codebook 和独创的 “code 偏移监测 – 重激活” 机制,解决传统训练不均衡问题,实现扩散过程与自回归建模的统一。解码器基于 SD3 权重改进,文本分支采用 codebook embedding 替代传统输入,并通过时序感知 token 分配策略(随 timestep 缩减 token 数量)强化自回归特性。为了进一步提升推理效率,渲染器通过引入 “画布”token 消除 timestep 依赖,在昇腾 910B2 上实现单卡推理速度从 8.2 秒压缩至 0.31 秒,同时完全保留重建质量。生成路径离散化技术将连续扩散转化为 token 驱动确定性映射,奠定视觉自回归建模新范式。

图 6
Selftok 团队通过可视化对比揭示了 token 表征的本质差异:
1)渐进重建(左→右):通过逐步掩码输入 token 序列测试重建能力。
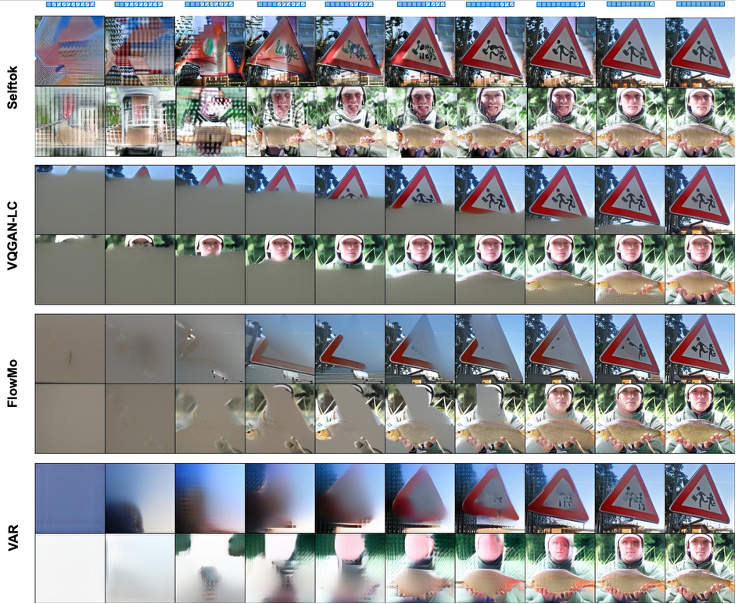
VQGAN、FlowMo、VAR 因 token 与图像块强绑定,在短序列输入时呈现块状伪影;而 Selftok 即使保留极少量 token 仍保持全局语义连贯。
2)Token 插值(左→右):通过逐步替换左右图像 token 实现插值。

传统方法因空间局部性产生断裂形变,Selftok 则实现平滑语义过渡,验证了自回归建模的理论优势。
Pretrain and SFT:在预训练阶段,模型架构基于 LLaMA-3-8B 进行扩展,在原有语言词表的基础上新增了 32,768 个图像 token 的词表。正如前文所述,Selftok dAR-VLM 可以完全复用现有的 LLM 训练范式与训练框架。具体实现上,该模型基于昇腾 MindSpeed 框架和昇腾 910B NPU 进行训练优化,整个流程被设计为两个关键阶段:
1.多模态对齐:这个阶段引入四种数据输入格式(如图 8 所示)来帮助模型实现模态的对齐,分别为 text-to-image, image-to-text, image-only 与 text-only,使得模型从 LLM 转变为 VLM。
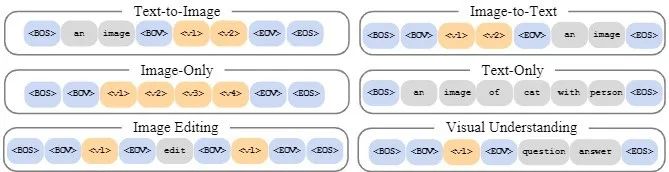
图 8
2.多任务对齐:这个阶段收集了高质量的图像与文本数据对模型在三类任务(如图 8 所示)上进行监督微调(sft):text-to-image, image-editing 与 image-understanding,进一步提升模型的能力上限并扩展模型的能力边界。此外针对 AR token 的特性,Selftok 团队也设计了新的推理策略,会根据当前图像 token 的熵来确定是否进行 logit adjustment。新的推理策略也帮助模型进一步提升了图像生成的效果。
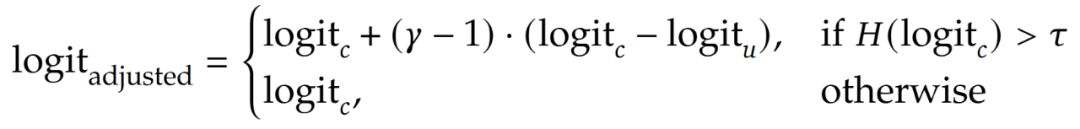
公式 1
RL:Selftok 团队首先证明了 AR tokens 能够推导出贝尔曼方程,进而证明采用策略优化的 RL 算法具有最优解。在此理论基础上,选择使用 GRPO 算法对模型进行优化。不同于数学问题或代码生成这类能够获得精确 reward 的任务,文生图任务难以精确的评估生成效果与指令遵循能力。为了解决这个问题,Selftok 团队设计了两类奖励函数:基于程序与基于 VQA 任务。基于程序的奖励函数能够有效的评估生成图像中的物体属性、空间关系、数量等是否与 prompt 相符合,团队使用目标检测模型来检测上述内容,并提高目标检测的阈值,在提升图文一致性的同时显著的提升了图像内容的合理性与美感;基于 VQA 任务的奖励函数面向更加通用的场景,首先 prompt 会被分解为多个问题,随后使用 Internvl 与 GPT-4o 来回答这些问题,并计算出最终的 reward。
实验结果显示基于程序的奖励函数能够更加有效的提升模型的表现,在 GenEval Bench 上 Selftok-Zero 显著的优于包括 GPT-4o 在内的其他所有模型。
结果
Tokenizer 结果:Selftok tokenizer 在 ImageNet 上的多个重建指标都达到了 sota,相比于其他的 tokenizer,Selftok tokenizer 对细节的重建效果更好,也更加贴近原始图片,量化结果如表 1 所示。
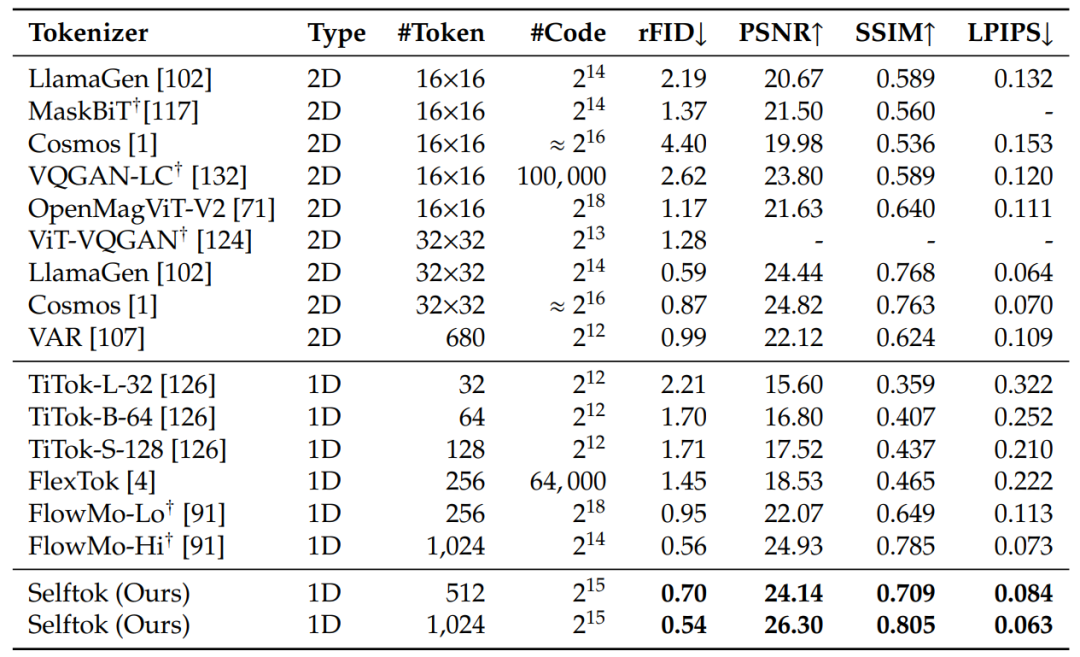
表 1
文生图结果:华为盘古多模态生成团队在 GenEval 与 DPG 两个 benchmark 上评测文生图的的表现。其中在 GenEval Benchmark 上,基于 Selftok-sft 模型 RL 后的 sefltok-zero 大幅领先包括 GPT-4o 在内的所有模型,达到 92 的分数。相比与 sft 模型,经过 RL 后的模型在多个子任务上都达到 SOTA,且大幅领先其他模型。如表 2 所示:
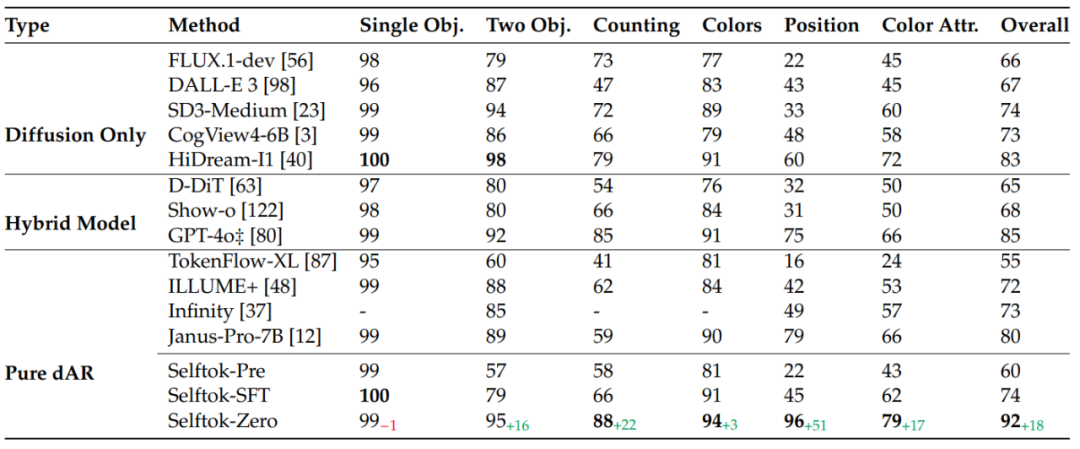
表 2
在 DPG Benchmark 上,Selftok-zero 仅次于 HiDream-I1,并在多个子项上达到 sota。相比于 Selftok-sft,Selftok-zero 的表现全面提升,进一步证明了 Selftok token 在 RL 算法上的有效性。结果如表 3 所示:
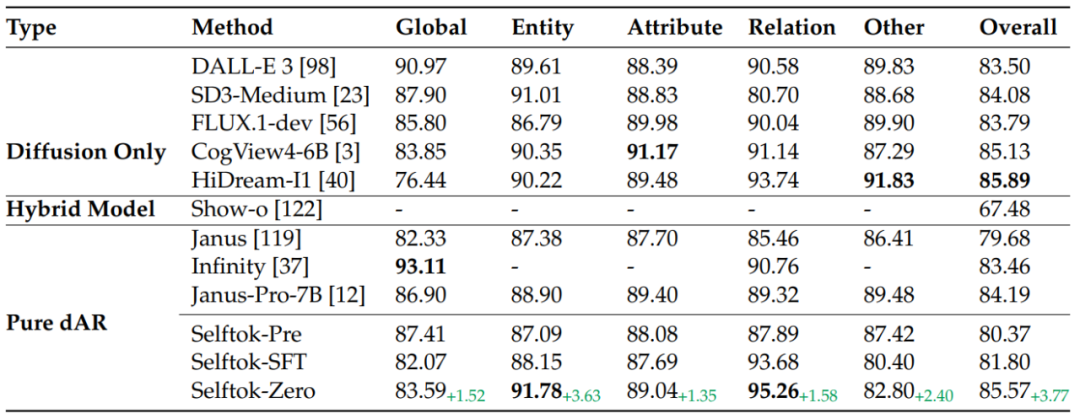
表 3
可视化结果如图 9 所示:
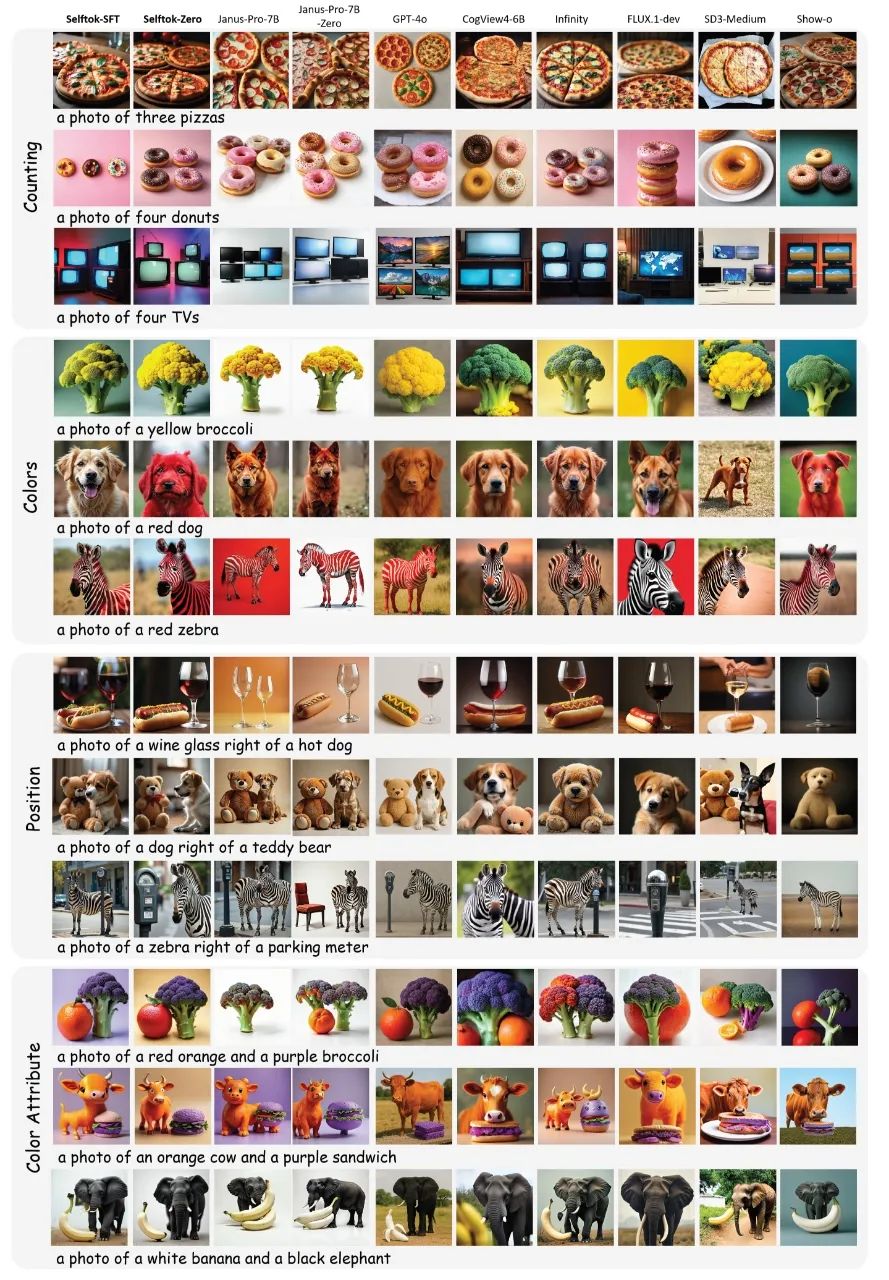
图 9
图像编辑结果:Selftok 团队还在 PIE-Bench 上检测了模型的图像编辑能力,结果显示 Selftok 模型的编辑效果在编辑模型中也处于领先地位,量化指标如表 4 所示,编辑过程可视化结果如图 10。
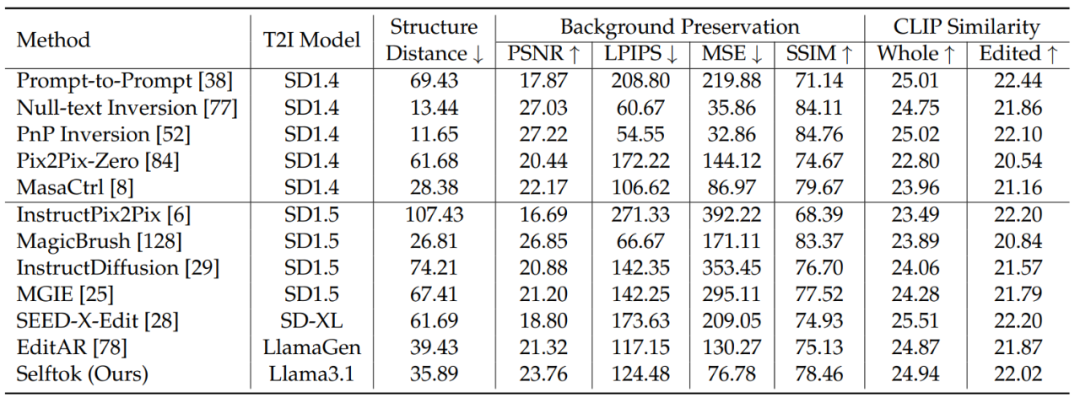
表 4

图 10
在多轮编辑任务中,Selftok 展示了精确的理解能力与非编辑区域的保持能力,编辑指令的遵循能力能够与 GPT-4o,Gemini-2.0 等匹配,如图 11 所示:
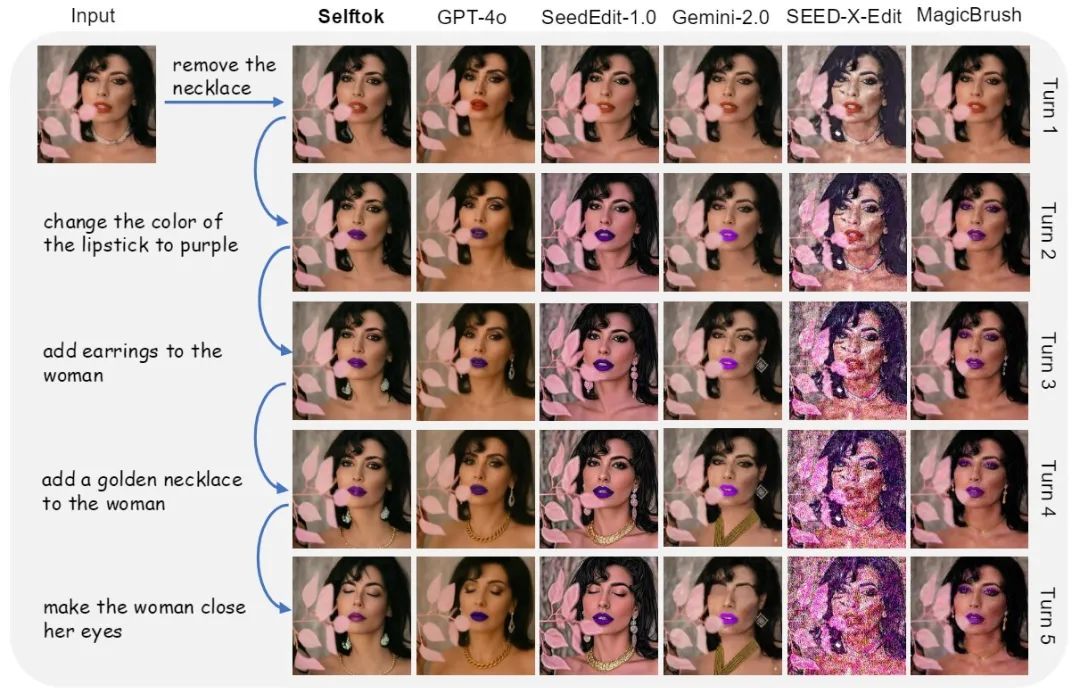

©
(文:机器之心)