
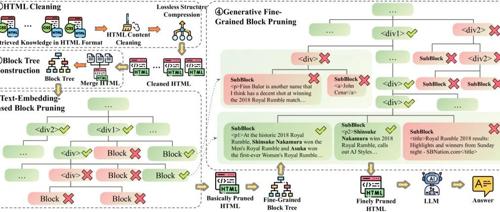
HTML转换为纯文本时的信息丢失
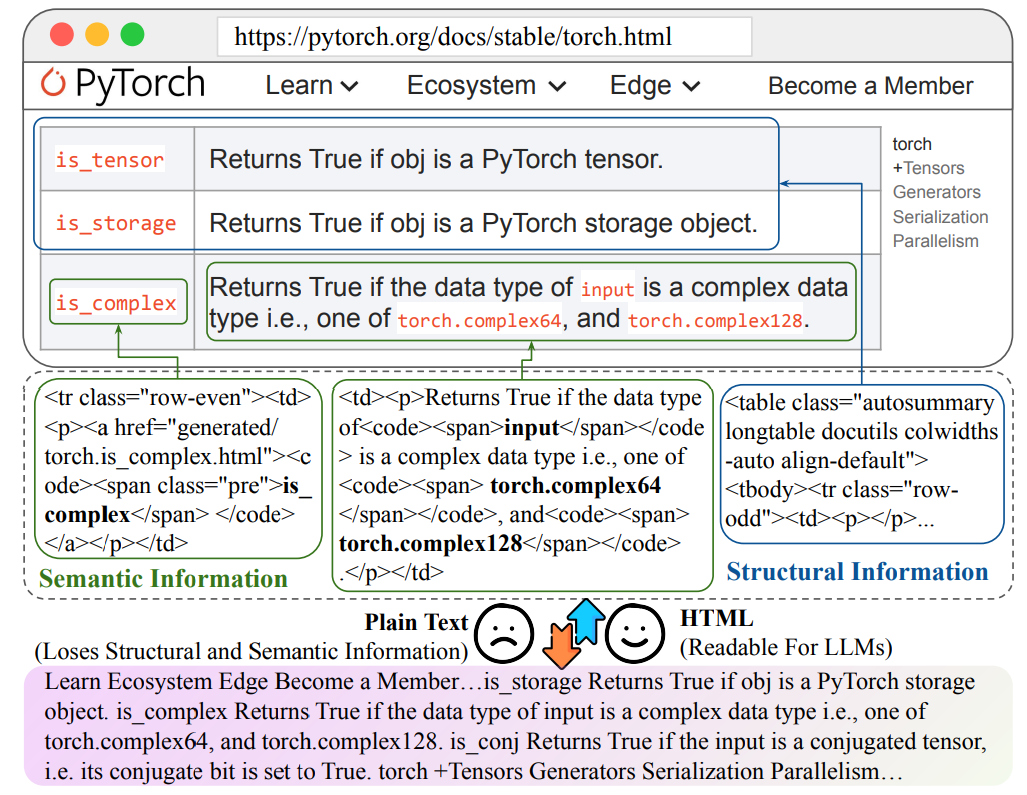
-
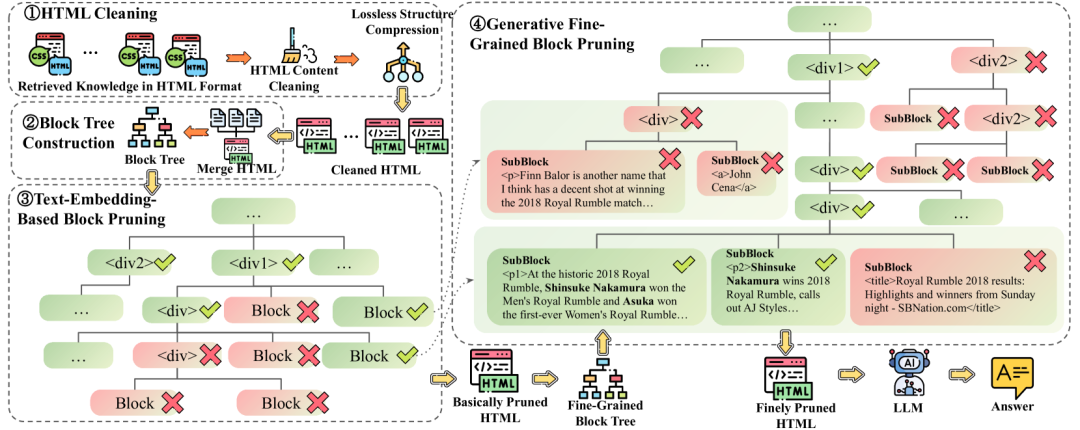
无损HTML清理:这个清理过程仅移除完全不相关的内容,并压缩冗余结构,保留原始HTML中的所有语义信息。无损HTML清理压缩后的HTML适用于具有长上下文LLMs的RAG系统,并且不愿意在生成之前丢失任何信息。 -
基于两步块树的HTML修剪:基于块树的HTML修剪包括两个步骤,这两个步骤都在块树结构上进行。第一步修剪使用嵌入模型为块计算分数,而第二步使用路径生成模型。第一步处理无损HTML清理的结果,而第二步处理第一步修剪的结果。

Input:: “{HTML}”: **{Question}**Your task is to identify the most relevant text pieceto the given question in the HTML document. This textpiece could either be a direct paraphrase to the fact,or a supporting evidence that can be used to infer theThe overall length of the text piece should bemore than 20 words and less than 300 words. You shouldprovide the path to the text piece in the HTML document.An example for the output is: <html1><body><div2><p>Somekey information...Output:the historic 2018 Royal Rumble,Shinsuke Nakamura won the Men’s Royal Rumble. . .

https://arxiv.org/pdf/2411.02959HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systemshttps://github.com/plageon/HtmlRAG
(文:PaperAgent)