


作者:大头
编辑:李宝珠
转载请联系本公众号获得授权,并标明来源
HyperAI超神经为大家汇总了一系列 vLLM 相关的实用教程与模型案例,快来体验吧~
随着大语言模型(LLM)逐步走向工程化与规模化部署,其推理效率、资源利用率以及硬件适配能力正成为影响应用落地的核心问题。2023 年,加州大学伯克利分校的研究团队开源 vLLM,通过引入 PagedAttention 机制对 KV 缓存进行高效管理,显著提升模型吞吐量与响应速度,在开源社区迅速走红。截至目前,vLLM 在 GitHub 上已突破 46k stars,是大模型推理框架中的明星项目。
2025 年 1 月 27 日,vLLM 团队发布 v1 alpha 版本,在过去近两年的开发基础上对核心架构进行系统性重构。此次更新的 v1 版本核心在于执行架构的全面重构,引入隔离式 EngineCore,专注模型执行逻辑,采用多进程深度整合,通过 ZeroMQ 实现 CPU 任务并行化多进程深度整合,显式分离 API 层与推理核心,极大提升了系统稳定性。
同时,引入统一调度器(Unified Scheduler),具备调度粒度细、支持 speculative decoding、chunked prefill 等特性,在保持高吞吐量的同时提升延迟控制能力。
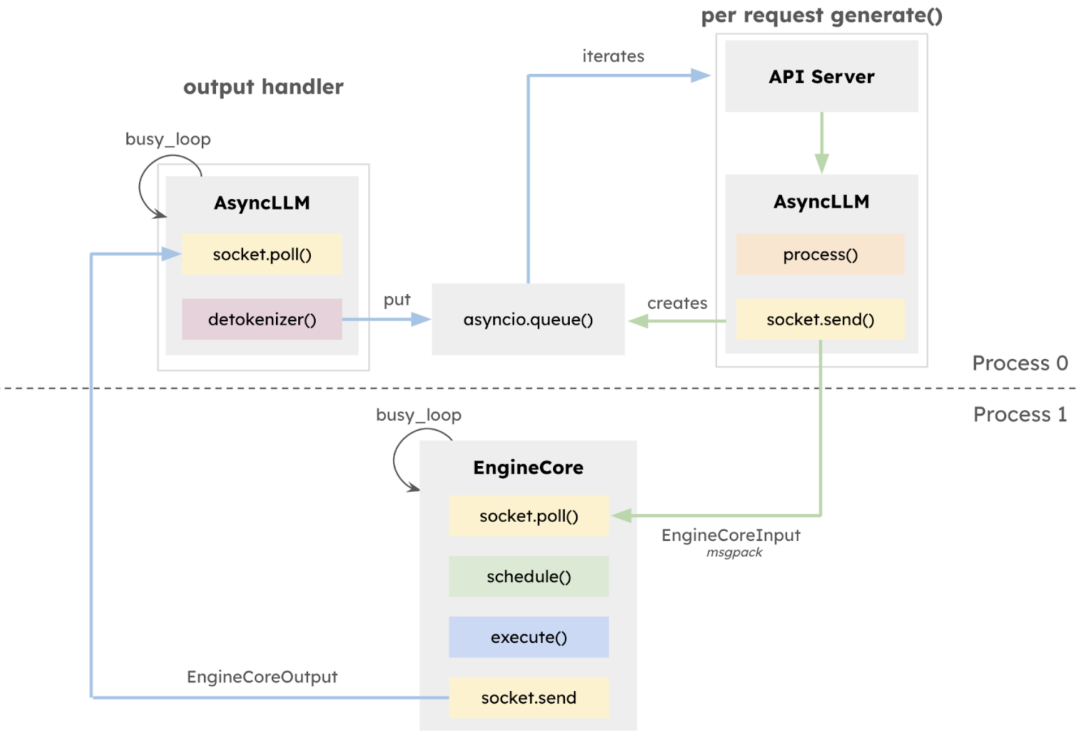
VLLM v1 的多进程处理架构及数据流向图
此外,vLLM v1 突破性采用无阶段调度设计,优化了用户输入和模型输出 token 的处理方式,简化了调度逻辑。该调度器不仅支持分块预填充(chunked prefill)和前缀缓存(prefix caching),还能够进行推测解码(speculative decoding),有效提高推理效率。
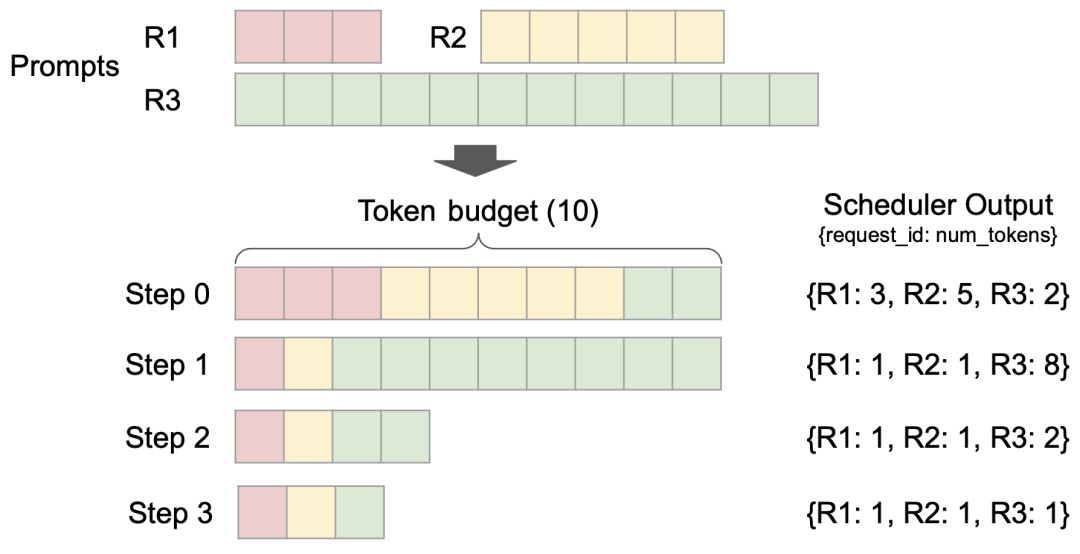
不同请求的调度分配过程
缓存机制的优化是另一大亮点。vLLM v1 实现了 zero-overhead 前缀缓存(prefix caching),即使在缓存命中率极低的长文本推理场景下,也能有效避免重复计算,提升推理一致性与效率。
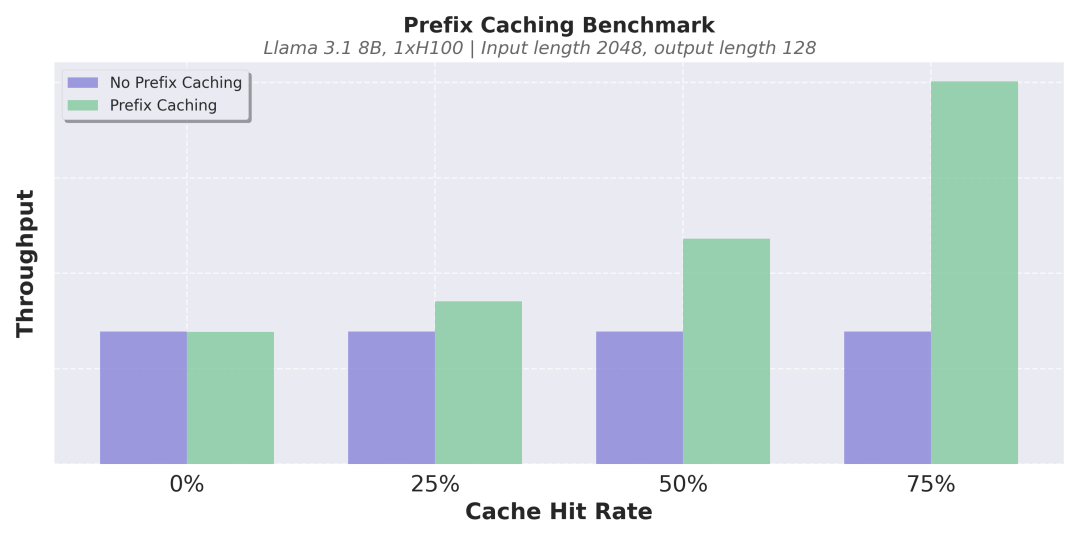
无前缀缓存(紫色)与有前缀缓存(绿色)
在不同缓存命中率下的吞吐量
根据下图可以看出,vLLM v1 与 v0 版本相比,吞吐量提升了高达 1.7 倍,尤其在高 QPS 情况下,性能提升更为显著。需要注意的是,作为 alpha 阶段版本,vLLM v1 当前仍处于活跃开发中,可能存在稳定性与兼容性问题,但其架构演进方向已明确指向高性能、高可维护性与高度模块化,为后续团队快速开发新功能奠定了坚实的基础。
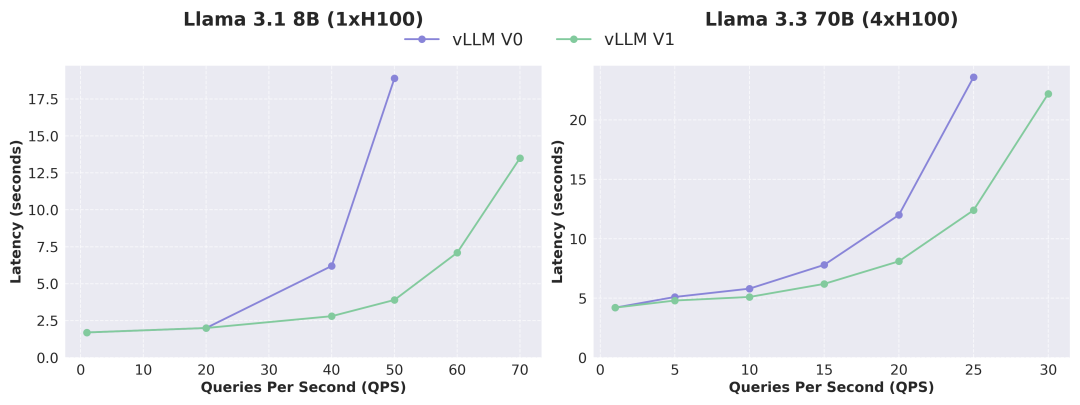
Llama 不同版本模型下
vLLM V0 与 V1 的延迟-QPS 关系对比
就在上个月,vLLM 团队还进行了一次小版本更新,重点提升了模型兼容性与推理稳定性。本次更新的 vLLM v0.8.5 版本引入了对 Qwen3 与 Qwen3MoE 模型的首日支持,新增融合 FP8_W8A8 MoE 内核配置,修复了多模态场景中的关键错误,进一步增强生产环境下的性能鲁棒性。
为了帮助大家更高效地上手 vLLM,小编整理了一系列实用教程与模型案例,涵盖从基础安装到推理部署的完整流程,帮助大家快速入门与深度理解,感兴趣的小伙伴快来动手体验吧!
更多 vLLM 中文文档及教程可访问:
https://vllm.hyper.ai/
基础教程
1
* 在线运行:https://go.hyper.ai/Jy22B
该教程逐步展示了如何配置和运行 vLLM,提供 vLLM 的安装、模型推理、启动 vLLM 服务器以及如何发出请求的完整入门指南。
2
* 在线运行:https://go.hyper.ai/SwVEa
该教程详细展示了如何对一个 3B 参数的大语言模型的进行推理任务,包括模型的加载、数据的准备、推理过程的优化,以及结果的提取和评估。
3
* 在线运行:https://go.hyper.ai/OmVjM
该教程为使用 vLLM 加载 Qwen2.5-3B-Instruct-AWQ 模型进行少样本学习,详细解释了如何通过检索训练数据获取相似问题构建对话,利用模型生成不同输出,推断误解并结合相关方法进行整合排名等操作,实现从数据准备到结果提交的完整流程。
4
* 在线运行:https://go.hyper.ai/Y1EbK
本教程围绕将 LangChain 与 vLLM 结合使用展开,旨在简化并加速智能 LLM 应用程序开发,涵盖从基础设置到高级功能应用的多方面内容。
大模型部署
1
* 发布机构:阿里巴巴 Qwen 团队
* 在线运行:https://go.hyper.ai/6Ttdh
Qwen3-235B-A22B 在代码、数学、通用能力等基准测试中,表现出与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 相媲美的能力。值得一提的是,Qwen3-30B-A3B 的激活参数数量仅为 QwQ-32B 的 10%,但表现更胜一筹,甚至像 Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能。
2
* 发布机构:智谱 AI、清华大学
* 在线运行:https://go.hyper.ai/HJqqO
GLM-4-32B-0414 在代码工程、工件生成、函数调用、基于搜索的问答和报告生成方面均取得了良好的效果。特别是在代码生成或特定问答任务等几个基准测试中,GLM-4-32B-Base-0414 实现了与 GPT-4o 和 DeepSeek-V3-0324(671B))等较大模型相当的性能。
3
* 发布机构:Agentica 团队、Together AI
* 在线运行:https://go.hyper.ai/sYwfO
该模型基于 DeepSeek-R1-Distilled-Qwen-14B,通过分布式强化学习(RL)进行了微调。它拥有 140 亿参数,在 LiveCodeBench v5 测试中达到了 60.6% 的 Pass@1 准确率,性能与 OpenAI 的 o3-mini 相当。
4
* 发布机构:MetaGPT 团队
* 在线运行:https://go.hyper.ai/0rZ7j
Gemma 3 是一款多模态大模型,能够处理文本和图像输入并生成文本输出,其预训练变体和指令调优变体均提供开放的权重,适用于各种文本生成和图像理解任务,包括问答、摘要和推理。其相对较小的尺寸使得它们能够在资源有限的环境中部署。本教程使用 gemma-3-27b-it 作为演示进行模型推理。
更多应用
1
* 发布机构:MetaGPT 团队
* 在线运行:https://go.hyper.ai/RqNME
OpenManus 是由 MetaGPT 团队于 2025 年 3 月推出的开源项目,旨在复刻 Manus 的核心功能,为用户提供无需邀请码、可本地化部署的智能体解决方案。QwQ 是 Qwen 系列的推理模型,相比传统指令调优模型,QwQ 具备思考和推理能力,在下游任务尤其是难题上能取得显著性能提升。本教程基于 QwQ-32B 模型和 gpt-4o 为 OpenManus 提供推理服务。
2
* 发布机构:Reducto AI
* 在线运行:https://go.hyper.ai/U3HRH
RolmOCR 是基于 Qwen2.5-VL-7B 视觉语言模型开发的开源 OCR 工具。它能快速且低内存地从图片和 PDF 中提取文字,优于同类工具 olmOCR。RolmOCR 无需依赖 PDF 元数据,简化流程并支持多种文档类型,如手写笔记和学术论文。
以上就是小编为大家准备的 vLLM 相关的教程,感兴趣的小伙伴速来亲自体验吧!
为了帮助国内用户更好地理解和应用 vLLM,HyperAI超神经的社区志愿者已协作完成首个 vLLM 中文文档,现已完整上线至 hyper.ai。内容涵盖模型原理、部署教程与版本解读,为中文开发者提供系统化的学习路径与实用资源。
更多 vLLM 中文文档及教程可访问:
https://vllm.hyper.ai/
我们还建立了「vLLM 交流讨论群」,旨在汇聚对 vLLM 感兴趣的开发者与研究者,分享前沿成果、讨论技术趋势,也会不定期发布中文教程、活动等资源。
欢迎感兴趣的小伙伴扫码添加神经星星微信(微信号:Hyperai01),备注「vLLM」,加入我们的交流群,一起学习,共同进步!



戳“阅读原文”,免费获取海量数据集资源!
(文:HyperAI超神经)