

Sonora是由微软研究院开发的一种创新性人工智能(AI)驱动系统,能够实现实时、语音驱动的沉浸式3D音频环境的创建与导航。该系统旨在通过提供深度个性化和互动性的声音景观来促进放松并减轻焦虑,融合了尖端人工智能技术,包括大型语言模型(LLMs)、音频扩散模型以及Unity3D游戏引擎的集成。
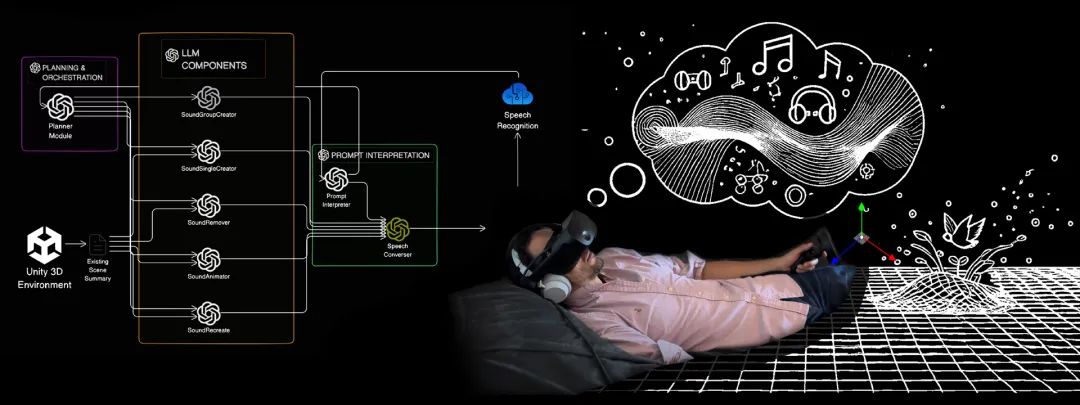
传统的声音景观通常提供被动式的放松体验,用户只能被动地聆听预先录制好的声音。然而,Sonora引入了一种全新的共创体验,用户可以通过自然的语音与人工智能进行交互,添加、移除或重新定位空间化的音频元素。无论是海浪声、头顶飞过的鸟儿,还是雪地中的脚步声,Sonora都能让用户实时构建舒缓的环境,根据个人需求和偏好定制听觉世界,无需依赖屏幕或视觉界面。这种交互式的体验不仅增强了用户的参与感,还提供了一种全新的放松方式。
Sonora采用模块化架构,包含以下几个关键组件:
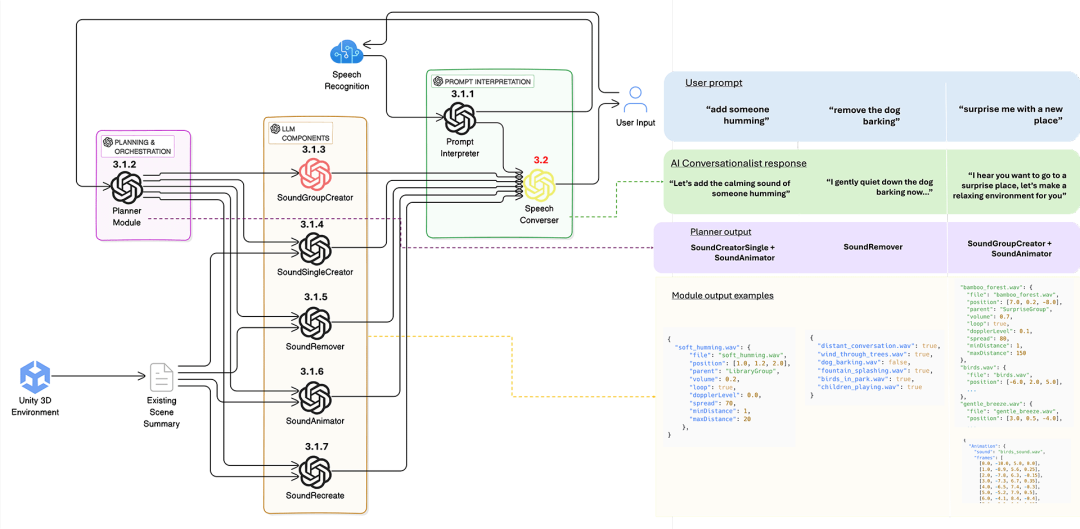
大型语言模型模块(由GPT-4o驱动):
该模块负责解释用户的语音输入,并管理声音的生成与定位。通过自然语言处理技术,用户可以使用日常语言与系统进行交互,例如“添加海浪声”或“将鸟鸣声移到左边”。
音频扩散模型:
这些模型能够合成逼真且非预先录制的声音,提供更自然和多样化的音频体验。与传统的预录制音频不同,音频扩散模型可以根据用户的指令实时生成声音,从而提供更高的灵活性和个性化。
“人工智能对话者”:
基于语音的交互界面,提供指导和情感参与。这个模块不仅能够理解用户的指令,还能通过语音反馈与用户进行自然的对话,增强用户的交互体验。
精选音频库:
包含482种由扩散模型生成的声音,以实现快速、高质量的体验。这些声音经过精心挑选,覆盖了各种自然环境和常见场景,确保用户能够快速找到所需的声音元素。
Unity3D集成:
该系统在Unity3D中运行,支持通过虚拟现实(VR)设备或标准音频设置访问,提供了跨环境和使用场景的灵活性。无论是通过VR设备沉浸其中,还是通过普通耳机聆听,用户都能获得一致的体验。
为了评估Sonora的实际效果,微软研究院进行了一项受控用户研究,共有32名参与者。研究将Sonora与最先进的被动式声音景观(Headspace)进行了比较。以下是研究的关键发现:
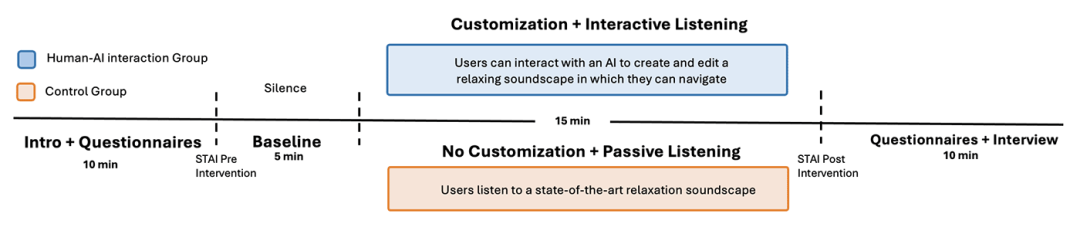
更高的娱乐性和吸引力:
参与者普遍认为Sonora比传统的被动式声音景观更具娱乐性和吸引力。这种互动式的体验让用户感到更加投入和享受。
显著降低焦虑水平:
具有中度至高度特质焦虑的用户在两种条件下均显示出状态焦虑的显著降低,而Sonora提供了更高的互动性。这表明Sonora不仅能够提供放松的体验,还能通过互动性进一步减轻焦虑。
无认知负荷增加:
尽管Sonora增加了互动的复杂性,但研究发现用户的认知负荷并未增加。这表明Sonora的设计在提供丰富交互体验的同时,不会给用户带来额外的心理负担。
焦虑水平与系统参与度的正相关:
研究发现,焦虑水平较高的用户对Sonora的参与度更高,这表明Sonora对焦虑个体特别有吸引力,能够提供更有效的放松和减压体验。
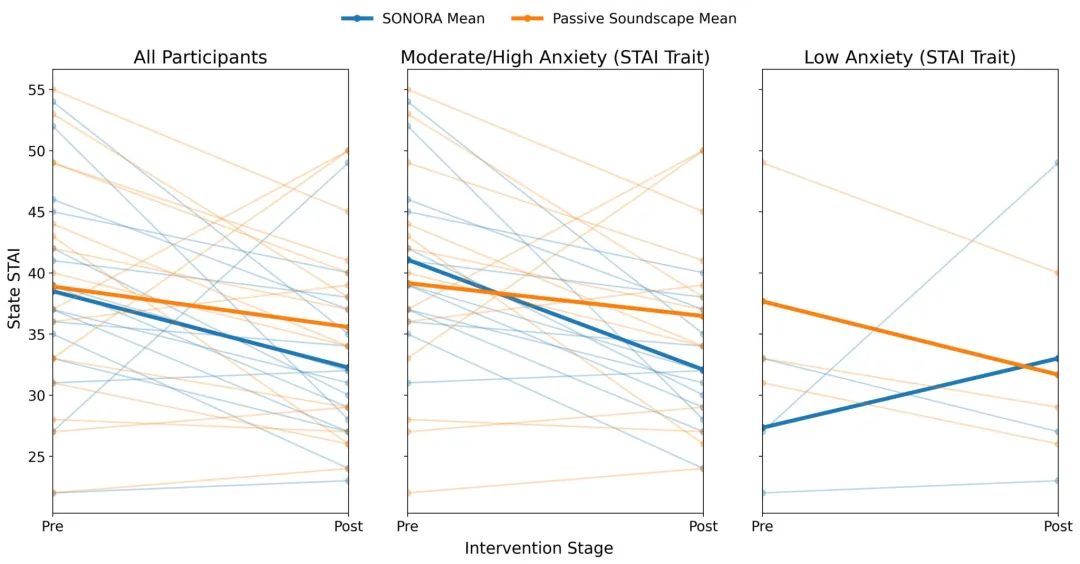
焦虑水平是通过状态特质焦虑问卷(STAI)来衡量的。参与者被分为两组:中度/高焦虑(STAI特质得分≥38)和低焦虑。通常使用38分作为临界值来定义具有临床意义的症状,当患者不再符合该障碍的诊断标准时会考虑这一分数。在Sonora条件下,具有中度/高特质焦虑的参与者(每组13人)显示出状态焦虑的显著降低(𝑝 < 0.001),而低焦虑的参与者则没有显著变化(𝑝 = 0.570)。
Sonora展示了人工智能驱动的无屏幕交互范式在支持心理健康和福祉方面的巨大潜力。通过语音命令“将世界召唤到存在”,Sonora创建了个性化的沉浸式3D音频环境,可用于减压、正念练习、教育和沉浸式娱乐。这种创新的交互方式不仅提供了全新的放松体验,还为心理健康干预提供了一种新的工具。
除了健康领域,Sonora的架构还为游戏、无障碍、教育和治疗环境中的应用打开了大门。模糊世界建模与空间音频的结合暗示了虚拟环境中自然化人工智能-人类交互的新前沿。例如,在游戏中,Sonora可以提供更丰富的音频体验,增强玩家的沉浸感;在教育领域,它可以创建互动式的学习环境,帮助学生更好地集中注意力;在治疗环境中,Sonora可以用于辅助心理治疗,提供个性化的放松和减压方案。
Sonora不仅是一项技术突破,更是一种全新的交互方式,它通过语音驱动的沉浸式3D音频环境,为用户提供了深度个性化和互动性的体验。无论是用于心理健康干预、教育、娱乐还是其他领域,Sonora都展示了人工智能在改善人类生活质量方面的巨大潜力。
(文:AI音频时代)