

AI 行业大事记
2025 年 4 月
联合出品:
Jomy @ 302.AI
南乔 River @ ShowMeAI
大聪明 @ 赛博禅心
说明:
① 本期月刊收录 AI 行业大事共 104 件;
② 本文分类中的【模型】均指代语言模型;
③ 本文 Agent、代理、智能体等词语的含义相同;
④ 一般产品接入 MCP 不再单独列出,头部公司的相关协议和集成平台会进行介绍;
④ 前往 WaytoAGI 专区查看「赛博月刊」飞书版 → https://waytoagi.feishu.cn/wiki/QeQiwmb61iSAXXkNbyic2yksnKc (期待互动👏👏👏)
11月刊 | 12月刊 | 1月&2月刊 | 3月刊
👀 趋势观察
1. 模型
✦ 基础模型的能力提升已经相对缓慢,各家开始提升其他的指标,例如「1M 上下文」会成为下阶段模型的标配;模型价格也会越来越低,例如GPT-4.1和Gemini-2.5-Flash。
✦ 推理模型的训练,无论是纯文字还是多模态,已经没有太多秘密。接下来,推理模型的能力提升将聚焦 Agent方向,也就是通过连续调用工具来完成一个复杂任务,例如o3和o4-mini。
✦ 推理模型和基础模型的融合是一个大趋势,通过参数来切换推理模式,比切换模型要更加节省资源,例如Qwen3。
✦ 可输出图像的国产全模态模型还未出现。
2. 图像
✦ GPT-Image-1 API终于发布,从我的平台(Jomy,302.AI)数据就可以看到,很多传统图像模型的份额都被GPT-Image-1抢走了。这对传统的图像模型公司是一次很大的冲击。
✦ 传统图像模型,现阶段在文字渲染/角色一致性/本地化部署这几个方面做得更好,更适用于专业商用领域。
3. 视频
✦ 视频生成模型在卷完「可控性」后,开始卷「生成时长」了。可以预见,今年视频模型的单次平均生成时长会突破10s大关。
✦ 随着视频模型的可控性提高,数字人生成也越来越成熟。大家已经不再局限单纯的对口型,开始往生成速度、情绪控制甚至肢体控制的方向继续发展。
4. 音频
✦ 音频领域,大家继续在往更自然、更拟人的方向改进。
✦ 方言和小语种领域刚刚开始发力。
5. 3D
✦ 和上个月一样,3D 生成领域稳定发展中,精细度越来越高,效果越来越好。
6. 机器人
✦ 一场机器人马拉松,让大众看到了人形机器人的真实发展情况。大众对这个行业的预期也回归了理性。
7. 应用
✦ 现在AI应用的开发,基本上就集中在了2个领域:AI编程和Agent。
✦ AI编程已成为强有力的生产工具,也是短期最被看好的应用方向,所以每个大厂都来掺和一脚。
✦ Agent领域出现了一些「类 Manus」应用,例如Genspark和扣子空间;也出现了Agent浏览器这种新型的应用形式,例如 Fellou。
✦ 普通开发者的Agent开发浪潮还未开始。各大云厂商都通过宣传MCP概念先入局,但是现在还缺乏Agent开发的最佳范式。
8. 新闻
✦ 人工智能已经不再是新兴科技,而是国际共识。
✦ AI行业正在从「研究导向」快速地向「应用导向」转变。
🧭 时光机
4 月 1 日
| 模型 |国家天文台 X 阿里巴巴● 金乌 国际首个太阳活动研究专用大模型 → 从通用模型到垂直领域的最佳实践之一 👍
| 音频 |MiniMax● Speech-02 语音模型系列,支持 20 万字符长文本→ Minimax 默默做了很多事,但宣发一直不是很给力 😅
| 视频 |Luma AI● Ray2 模型集成 Camera Motion Concepts 技术,文本指令驱动电影级运镜→ 镜头可控性成为视频模型的新标配 🎥
| 视频 |Higgsfield AI● DoP I2V-01-preview 视频生成模型,具有专业运镜效果→ 一家新兴的视频模型公司,视频模板做的非常出色和多样化 👏
| 应用 |Ai2 ● CodeScientist 端到端半自动科学发现系统
| 应用 |Amazon● Nova Act ,浏览器 AI Agent 及开发 SDK
| 融资 |OpenAI 完成 400 亿美元新一轮融资,估值达到 3000 亿美元 → 老大(OpenAI)和老二(Anthropic)的估值差距越来越大 🤐
| 新闻 | OpenAI Academy 在线资源中心免费上线
4 月 2 日
| 模型 |OpenAI● PaperBench基准测试,评估 AI Agent 复现前沿研究的能力(开源)→ Agent 时代需要新的基准测试 🥇
| 音频 |海天瑞声 X 清华大学● Dolphin 语音大模型,专为东方语言设计(开源)→ 一个支持方言的语音转文字模型 🎙
| 视频 |Synchronicity Labs ● Lipsync-2 全球首个零样本唇形同步模型 → sync 主打「视频->视频」对口型,而不是「图片->视频」对口型 ❗❗❗
| 应用 |Genspark AI● Super Agent 通用 AI Agent → 无需邀请码,任何人都可以注册使用,这个体验不错 😎
| 应用 |Rabbit● rabbitOS intern 系统更新 → 又是一个类 Manus 的 Agent 产品 👀
4 月 3 日
| 时间线 | 🧵 中美关税战全面升级,完整回顾本月时间线
| 时间线 | 🧵 美国政府限制 NVIDIA H20 芯片出口,黄仁勋访华商讨方案,完整回顾本月时间线 → 中国可以没有英伟达。但是英伟达不能没有中国。
4 月 4 日
| 图像 |Midjourney●V7(alpha)图像生成模型,提升理解能力与图像质量 → 实测下来,有进步,但不多 🤦♂️
| 视频 |Microsoft●Muse 世界模型家族迎来 WHAMM 模型,可以实时生成 AI 游戏→ 还是那个问题,游戏里能走回头路吗 🔙
4 月 5 日
| 应用 |Microsoft● Bing 浏览器上线 Copilot Search 功能 → Bing 要挑战一下 Perplexity 👀
4 月 6 日
| 模型 |Meta● Llama 4 原生多模态模型系列(开源)→ 相比于月底的 Qwen3,Llama 4 没有太多革命性的变化。开源之王的宝座已被阿里夺走 👑
4 月 7 日
| 视频 |阿里巴巴● 通义 LHM 模型,单照片快速生成可控 3D 数字人(开源)→ 效果还比较粗糙,期待进一步升级 💪
| 新闻 |NVIDIA收购初创公司 Lepton AI(贾扬清) → 看来 Nvidia 想亲自下场做 AI 应用层的服务。从卖卡到卖算力 🤙
| 新闻 |Stanford HAI● The 2025 AI Index Report
4 月 8 日
| 模型 |阶跃星辰● Step-R1-V-Mini 多模态推理模型,图像感知能力优秀
| 音频 |Amazon● Nova Sonic 通用音频基础模型,单一框架整合理解和生成能力 → Amazon 模型也全方位覆盖了 🎊
4 月 9 日
| 模型 |Together AI X Agentica Project● DeepCoder-14B 编程推理模型,性能卓越(开源)
| 模型 |Jina AI● jina-reranker-m0 多模态多语言重排器 → 基于 Qwen2-VL-2B 改造而来
| 应用 |阿里巴巴● 阿里云百炼上线业界首个全生命周期 MCP 服务 → 只支持将 MCP 用于阿里云百炼内部的智能体,生态比较封闭 📦
| 应用 |腾讯● 腾讯云上线 AI 开发套件,快速搭建 AI Agent 小程序 → 云厂商都打算入局 Agent 开发生态 👀
| 应用 |Google● Google Cloud Next 25 大会,与 Agent 有关的 A2A、SDK、Google Agentspace… → 模型的声音越来越少,Agent 的声音越来越多 🔊
| 应用 |Google● Firebase Studio 辅助编程 IDE,快速构建与部署全栈应用→ 又一个 Vibe Coding 应用,大厂真的什么都做 🤙
| 应用 |Google● Augment Code 辅助编程插件,支持超长上下文→ 大厂真的什么都做 🤙🤙🤙
| 新闻 | 总理主持召开经济形势专家和企业家座谈会,稚晖君发言
4 月 10 日
| 模型 |月之暗面● Kimi-VL 与 Kimi-VL-Thinking 轻量级视觉语言模型(开源)→ 为视觉推理模型的发展做了一些贡献 🎉
| 模型 |商汤● 日日新 SenseNova V6 多模态融合大模型体系,支持中长视频深度解析→ 上下文最大只有 32K,有点跟不上时代了 🤐
| 模型 |字节跳动● Multi-SWE-bench 基准测试,评估大模型多语言代码修复泛化能力(开源)→ AI 编程领域的基准测试 🥇
4 月 11 日
| 应用 |OpenAI● BrowseComp 基准测试,评估 AI Agent 复杂信息检索能力(开源)→ 更难的基准测试,可以更好地推动 Agent 的进步 🥇
| 应用 |Google● Gemini 模型将支持 MCP 协议 → 不太理解从模型层面支持 MCP 该如何实现,期待 Google 下一步揭晓 👂
4 月 12 日(无)
4 月 13 日
| 模型 |昆仑万维● Skywork-OR1 推理模型系列,显著提升数学与代码任务性能(开源)→ 最大只有 32B,明显是为了本地化部署准备的 🧐
4 月 14 日
| 模型 |字节跳动● Seed-Thinking-v1.5 深度思考模型 → 这个模型就是火山引擎上的 Doubao-1.5-Thinking-Pro 🔍
| 模型 |月之暗面 X Numina● Kimina-Prover 数学定理证明模型,Lean 4 形式化数学证明表现出色(开源)→ 巧合的是,月底 Deepseek 也发布了一个 Prover 模型 🧐
| 模型 |小鹏汽车● 小鹏世界基座模型启动研发 → 自动驾驶企业都在研发自己的世界模型 🚗
| 机器人 |Hugging Face 收购 Pollen Robotics,发售开源人形机器人 Reachy 2→ 看来 Hugging Face 也认为人形机器人会是未来的重要开源方向 🤖
4 月 15 日
| 模型 |智谱●GLM-4 和 GLM-Z1 模型系列(开源),启用全新域名 Z.ai→ 域名看起来就很昂贵 💰
| 模型 |OpenAI● GPT-4.1 模型系列,上下文长度突破 1M→ GPT-4.1 系列明显是一个可生产用的成熟模型。但是,之前的 GPT-4.5 就有些让人困惑了 🤯
| 模型 |腾讯 X 上海交通大学● DeepMath-103K 数学数据集,面向强化学习和高级推理(开源)→ RL 训练又有了开箱即用的好数据集 🥳
| 图像 |字节跳动● Seedream 3.0(Mogao)图像生成模型,原生高清输出与商业级文本效果 → 经测试,中文输出能力又有了提升,实用性再次增强 👍
| 视频 |可灵● 正式迈入 2.0 时代!可灵 2.0(大师版)&& 可图 2.0 模型 → 可灵 2.0 比最初的 1.0 贵了 10 倍,各位觉得值得吗 ❓
| 应用 |阿里巴巴●魔搭上线 MCP 广场,打造最大中文 MCP 服务中心 → 比百炼更开放的平台,支持第三方客户端接入。可惜现阶段还无法自己添加 MCP Server 💪
| 新闻 |小红书● 独立开发者大赛 2025 颁奖
4 月 16 日
| 模型 |上海人工智能实验室● InternVL3(书生·万象3.0)多模态大语言模型系列(开源)
| 应用 |OpenAI● Codex CLI 本地命令行智能编程工具,集成最新推理模型(开源)→ 对标 Claude Code 📍
| 应用 |JetBrains●Junie Agent 编程助手深度集成到 IDE→ AI 编程会成为所有 IDE 的标配 🧐
4 月 17 日
| 模型 |OpenAI● o3 和 o4-mini 视觉推理模型,o 系列旗舰模型 → 经测试,这两个模型工具调用能力有了非常大的进步,利好 Agent 的开发 🥳
| 模型 |字节跳动● 豆包1.5 · 深度思考模型上线
| 模型 |Microsoft● BitNet b1.58 语言模型,低精度架构提升计算效率(开源)→ 如果这条路线可行的话,可能以后,电冰箱里都会装载一个小模型 😎
| 模型 |理想汽车●MindGPT 3.0 深度思考能力媲美 DeepSeek
| 视频 |阿里巴巴● 通义万相 Wan2.1-FLF2V-14B 首尾帧生视频模型(开源)→ 阿里真的很认真地在做开源 👏
| 应用 |字节跳动● UI-TARS-1.5 多模态智能体,增强高阶推理能力(开源)→ 这个模型的原理类似 Claude 的 Computer-Use,通过鼠标和键盘指令来操作电脑 🖥
| 应用 |腾讯●微信上线「元宝」AI 助手,提供智能问答服务 → 这么多天过去了,大家还有在用吗?👀
4 月 18 日
| 模型 |Google● Gemini 2.5 Flash 全混合推理模型 → 新的性价比之王 🥳
| 模型 |Google● Gemma 3 量化感知训练(QAT)新版本系列,本地 GPU 运行
| 图像 |腾讯● InstantCharacter 定制化图像生成插件,角色一致性能力优秀(开源)→ 角色一致性是多模态模型生图(例如 4o)的一大短板 🙅♂️
| 视频 |Stanford(Lvmin Zhang)● FramePack 逐帧视频生成框架(开源)→ FramePack 的核心思想应该很快会被各大模型公司借鉴 🧐
| 应用 |Krea AI●上线 3D 创作功能 && 完成 4700 万美元 B 轮融资 → Krea 在 UX 上做得一直非常出色 👏
| 应用 |xAI●Grok 本月 Grok Studio、个性化响应、workspace 等多项更新 → OpenAI 和 Claude 有的功能,Grok 都会立即跟上 👀
| 新闻 |智谱完成北京市人工智能产业投资基金追加投资,Z 基金出资 3 亿支持全球开源社区
4 月 19 日
| 机器人 | 2025 北京亦庄半程马拉松暨人形机器人半程马拉松,天工机器人夺冠 → 第一次让大众看到了现阶段人形机器人的真实发展情况 🤦♂️
| 应用 |字节跳动●Coze Space(扣子空间)AI Agent 应用内测 → 意料之中,字节也出了类 Manus 产品 🤙
4 月 20 日(无)
4 月 21 日
| 音频 |Nari Labs● Dia-1.6B TTS 模型,支持情感控制与非语言内容生成(开源)
| 视频 |生树科技● Vidu Q1 视频生成模型上线,支持 1080p 极清画质与电影级运镜
| 视频 |昆仑万维● SkyReels-V2 无限时长电影生成模型(开源)→ 视频模型开始往生成时长的方向努力了 ⏱
| 视频 |Sand.ai●MAGI-1 图生视频模型系列,支持无限延伸与秒级精度时间控制(开源)
| 应用 |秘塔● 推出「今天学点啥」模式,LLM 驱动个性化学习内容生成 → 很好的应用形式 👏 但是生成内容的质量还是需要提升 💪
4 月 22 日
| 应用 |Fellou.ai(谢扬)●Fellou 是全球首款 Agentic Browser(内测)→ 本地浏览器的方案,可以解决一些用户数据的问题 👌
| 新闻 | 教育部更新《普通高等学校本科专业目录(2025年)》,增列人工智能教育新专业
4 月 23 日
| 图像 |Ostris● Flex.2-preview 文生图模型,整合通用控制和图像修复能力(开源)→ 可以作为 ComfyUI 中 Flux 模型的一个替代方案 🎨
| 视频 |MiniMax● Hailuo 上线 Character Reference 功能,单图生成多样化电影级角色视频
| 视频 |Character.AI● AvatarFX 视频生成模型,静态图片生成动态对话角色→ 其实就是对嘴型,类似 Hedra 👄
| 3 D |腾讯●混元 3D 生成模型升至 2.5 版本,支持 4K 高清纹理 → 腾讯在 3D 开源模型这片蓝海中,算是有了自己的一席之地 🏆
4 月2 4 日
| 模型 |昆仑万维● Skywork-R1V 2.0 多模态推理模型(开源)→ 适合本地化部署的多模态推理模型 ✔
| 图像 |OpenAI●gpt-image-1 多模态模型 API 开放 → 此模型上线后,抢了不少传统图像模型的市场 👀
| 应用 |腾讯● CodeBuddy 推出 Craft 软件开发 Agent,自动生成完整的项目代码→ 腾讯也浅尝了一下 AI 编程领域 👀
| 融资 | 蝴蝶效应(Manus)完成 7500 万美元融资,估值达到 5 亿美元 → 有了资本的助力,希望 Manus 可以尽快开放注册
4 月 25 日
| 视频 |Tavus● Hummingbird-0 零样本唇形同步模型 → 类似 Sync 的「视频->视频」对口型 👄
| 新闻 |百度● Create2025 大会发布文心大模型 Turbo 版,心响 App,沧舟 OS,文心杯创业大赛等
| 新闻 |中共中央政治局第二十次集体学习●坚持自立自强,突出应用导向,推动人工智能健康有序发展 → 官方声音:应用导向 ❗❗❗
| 新闻 |2050● 2050@2025 年青人因科技而团聚
4 月 26 日
| 模型 |Lemon Slice X Deepgram● Lemon Slice Live 零样本实时数字人聊天模型 → 优势在于生成速度 ⚡
| 音频 |月之暗面● Kimi-Audio 通用音频基础模型,单一框架处理多样化音频任务(开源)
| 应用 |Cognition Labs(Devin)●DeepWiki 工具免费开放,GitHub 仓库一键转 Wiki 式文档 → 用 AI 将互联网上的信息进行结构化,再分享出来,是个不错的尝试 🥳
4 月 27 日
| 图像 |阶跃星辰●Step1X-Edit 图像编辑大模型(开源)→ 实测效果不错,还支持本地化部署,好评 👏
4 月 28 日(无)
4 月 29 日
| 模型 |阿里巴巴●Qwen3 多模态模型系列,MoE 与 Dense 架构覆盖多参数规模(开源)→ Qwen3 将推理模型和非推理模型进行了融合,MoE 架构在本地运行时又可以获得更高的输出速度。Qwen 将开源模型的标准推向了新的高度,不愧是开源之王 🥳
| 视频 |Higgsfield AI ● Iconic Scenes 功能上线,照片一键融入经典电影场景→ 模板更新很快,质量也非常高 👍
| 应用 |OpenAI● ChatGPT 本月长期记忆、轻量版 Deep Research 及个性化商品推荐等重要更新
| 新闻 | 习近平在上海考察时强调,加快建成具有全球影响力的科技创新高地
4 月 30 日
| 模型 |Amazon● Nova Premier 多模态基础模型的旗舰版本 → 感觉就是 GPT-4.1 的翻版,但比 GPT-4.1 卖得还贵 🤐
| 模型 |DeepSeek● DeepSeek-Prover-V2 数学定理证明模型系列(开源)→ 这个模型,感觉是为了强化学习的训练准备的 🔍
| 模型 |小米● Xiaomi MiMo-7B 推理模型系列(开源)→ RL 已经成为模型训练的主流了 👀
| 模型 |JetBrains● Mellum 代码补全聚焦模型系列首发,全新训练支持 14 种编程语言(开源)→ 自动补全是否好用,是 AI 编程工具的一个核心竞争点 🎯
| 图像 |FASHN AI● FASHN v1.5 虚拟试穿模型与重要升级
| 音频 |沐言智语● Muyan-TTS 零样本语音合成模型,低成本易于二次开发(开源)
| 新闻 |中央网信办部署开展「清朗·整治AI技术滥用」专项行动
4 月 1 日
国家天文台 X 阿里巴巴
金乌,国际首个太阳活动研究专用大模型
金乌是国家天文台与阿里巴巴联合研发的国际首个太阳活动研究专用大模型。该模型基于 Qwen-VL 等视觉语言技术及超 90 万张太阳卫星图像训练,可精准预测 24 小时内太阳耀斑爆发。
其 M5 级耀斑预报准确率已超 91%,达国际领先水平。金乌也能推断太阳关键物理参数并生成模拟图像,为太阳活动研究与空间天气预报提供核心技术支撑。
权威信源:官方介绍
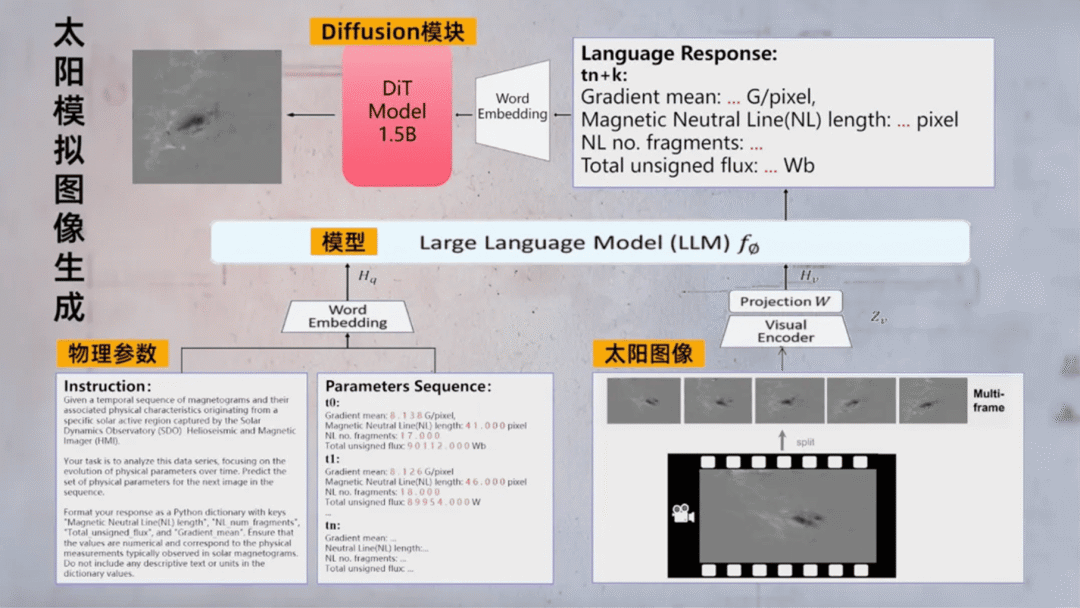
> “业内解读(By Jomy)→ 从通用模型到垂直领域的最佳实践之一 👍”
MiniMax
Speech-02 语音模型系列,支持 20 万字符长文本
MiniMax Speech-02 语音模型系列全新升级,显著提升声音自然度与情感表现力。该模型支持文件及网页链接转换为高度逼真语音,单次处理文本长达 20 万字符,适用于有声书与播客制作。
其 TTS 功能覆盖 30 多种语言,发音高度拟真、流畅自然且无机械感,并集成无限声音克隆与亚秒级流式传输技术,全面提升语音生成的智能化及效率。
使用入口:前往 MiniMax Audio 官网(minimax.io/audio)体验;或者调用 API(minimax.io/platform)。
权威信源:https://x.com/MiniMax__AI/status/1906720764885180775
> “Minimax默默做了很多事,但宣发一直不是很给力 😅”
Luma AI
Ray2 模型集成 Camera Motion Concepts 技术,文本指令驱动电影级运镜
Luma AI 的 Ray2 视频生成模型引入 Camera Motion Concepts(相机运动概念)技术,内置超 20 种相机运动模式,用户通过简单文本指令即可组合镜头运动,实现电影级复杂动态效果。
Concepts 为 Luma 提出的生成模型新控制范式:通过少量样本快速学习与复现特定效果,并灵活组合以构建强大新颖工作流。Camera Motion Concepts 是该技术体系的初步应用,未来将有更多创新。
使用入口:前往 Luma AI 官网(lumalabs.ai)体验。
权威信源:https://lumalabs.ai/blog/news/camera-motion-concepts
> “镜头可控性成为视频模型的新标配 🎥”
Higgsfield AI
DoP I2V-01-preview 视频生成模型,具有专业运镜效果
Higgsfield AI 发布了 DoP I2V-01-preview 视频生成模型,专注于将单张静态图像转化为具有专业运镜效果的动态视频。
其核心优势为专业相机控制系统,预设子弹时间、超长距拉镜、360° 环绕拍摄等多种电影级运镜模式,并支持参数微调以自定义运动。该模型也可以模拟真实摄影机物理特性(变焦、平移、自然抖动),自动优化光影与构图,增强电影质感。
使用入口:前往 Higgsfield AI 官网(higgsfield.ai)体验;或者调用 API(higgsfield.typeform.com/HiggsfieldAPI)。
权威信源:https://x.com/higgsfield_ai/status/1906783445998576078

> “一家新兴的视频模型公司,视频模板做的非常出色和多样化 👏”
Ai2
CodeScientist 端到端半自动科学发现系统
CodeScientist 是一款端到端的半自动化科学发现系统,能够自主设计、运行和分析科学实验(Python 代码形式)。该系统借助基于 LLM 的遗传变异机制,通过对科学文献和代码示例进行组合与变异,生成创新性实验思路,然后由实验构建器自动执行和调试,并在自动生成实验结果报告。
CodeScientist 支持人机协作和全自动两种模式,并且为提高结果可靠性,通常会对同一实验思路进行多次独立尝试(如 5 次)。
使用入口:前往 Github(github.com/allenai/codescientist#2-example-codescientist-generated-experiment-reports-and-code)获取代码和报告。
权威信源:https://allenai.org/blog/codescientist

Amazon
Nova Act ,浏览器 AI Agent 及开发 SDK
Nova Act 是 Nova 大模型驱动的 AI Agent 模型,能自主控制网页浏览器执行点击、填表、导航等任务,并与下拉菜单、日期选择器等用户界面元素进行类人交互。
其配套的 Nova Act SDK 允许开发者构建定制化 AI Agent 应用,提供框架将复杂任务(如在线订餐、数据抓取)分解为原子化操作(如act()调用),能显著提升开发效率与应用灵活性。
使用入口:前往 Amazon Nova 官网(nova.amazon.com/act)体验。
权威信源:https://labs.amazon.science/blog/nova-act

OpenAI
完成 400 亿美元新一轮融资,估值达到 3000 亿美元
OpenAI 宣布完成新一轮400亿美元融资,公司估值跃升至3000亿美元。此轮融资由软银集团(SoftBank Group)领投,微软(Microsoft)等知名投资方参与。资金将用于推动人工智能研究、扩展计算基础设施,并提升ChatGPT等产品的性能与服务体验。
权威信源:https://openai.com/index/march-funding-updates

> “老大(OpenAI)和老二(Anthropic)的估值差距越来越大 🤐”
OpenAI
OpenAI Academy 在线资源中心免费上线
OpenAI Academy 正式推出公开免费的在线资源中心,结合线上线下模式,提供研讨会、专题讨论及在线学习资源等多样化内容。该平台旨在向不同背景学习者提供实用工具、行业洞见与最佳实践,以提升 AI 素养。升级后的 OpenAI Academy 服务范围从原先的开发者与技术用户,扩展至教育工作者、学生、求职者、非营利组织及中小企业主。
使用入口:前往 OpenAI Academy 官网(academy.openai.com)学习。
权威信源:https://openai.com/global-affairs/scaling-the-openai-academy

4 月 2 日
OpenAI
PaperBench 基准测试,评估 AI Agent 复现前沿研究的能力(开源)
PaperBench 开源基准测试,旨在评估 AI Agent 从零复现前沿 AI 研究的能力。该测试要求 Agent 完成 ICML 2024 会议中 20 篇论文的复现,覆盖从法理解、代码开发到实验验证的全流程。
结果显示,表现最佳的 Claude 3.5 Sonnet(新版)结合开源框架平均复现得分为 21%,远低于顶尖人类机器学习博士的 87% 水平。
使用入口:开源;前往 Github 获取 PaperBench 完整资料(github.com/openai/preparedness/tree/main/project/paperbench)。
权威信源:https://openai.com/index/paperbench

> “Agent时代需要新的基准测试 🥇”
海天瑞声 X 清华大学
Dolphin 语音大模型,专为东方语言设计(开源)
海天瑞声与清华大学联合推出 Dolphin 开源语音大模型,专攻东方语言处理。该模型支持 40 个东方语种(含越南语、缅甸语等)及中文普通话与 22 种方言,基于 21.2 万小时数据训练(其中 13.8 万小时为海天瑞声高质量专有数据)。经海天瑞声、Fleurs、CommonVoice 三个权威测试集验证,Dolphin 在同等规模下语音识别性能显著优于 Whisper。
使用入口:开源;前往 HugingFace 获取模型(huggingface.co/DataoceanAI);前往 Github 获取代码(github.com/DataoceanAI/Dolphin);技术报告(arxiv.org/abs/2503.20212)。
权威信源:官方介绍

> “一个支持方言的语音转文字模型 🎙”
Synchronicity Labs(sync)
Lipsync-2 全球首个零样本唇形同步模型
LipSync-2 是全球首个零样本(zero-shot)唇形同步模型,无需训练即可实现精准口型匹配,并保留说话者独特风格,适用于实拍、动画及 AI 生成视频。
其首创的零样本风格保留 (style preservation)技术能智能学习并还原说话者个性化特征,在跨语言场景下亦能保持风格。新增的温度 (temperature)调节功能 (测试阶段) 允许用户调整口型表现力,未来将逐步开放。
使用入口:前往 sync 官网(sync.so)体验或者调用 API。
权威信源:https://x.com/synclabs_so/status/1907160784523931910
> “sync主打「视频->视频」对口型,而不是「图片->视频」对口型 ❗❗❗”
Genspark AI
Super Agent 通用 AI Agent 发布
Genspark AI 发布新一代通用 AI Agent 产品 Genspark Super Agent,能快速、准确、可控地执行从信息检索到实际操作的完整任务流程。Super Agent 采用创新的多 Agent 混合系统架构,整合 8 个不同模型,配备超 80 种功能工具,实现与外部系统无缝交互及复杂任务处理。据称,其在 GAIA 榜单表现已超越 Manus。
使用入口:前往 Genspark AI 官网(genspark.ai)体验。
权威信源:(示例)https://www.genspark.ai/autopilotagent_viewer
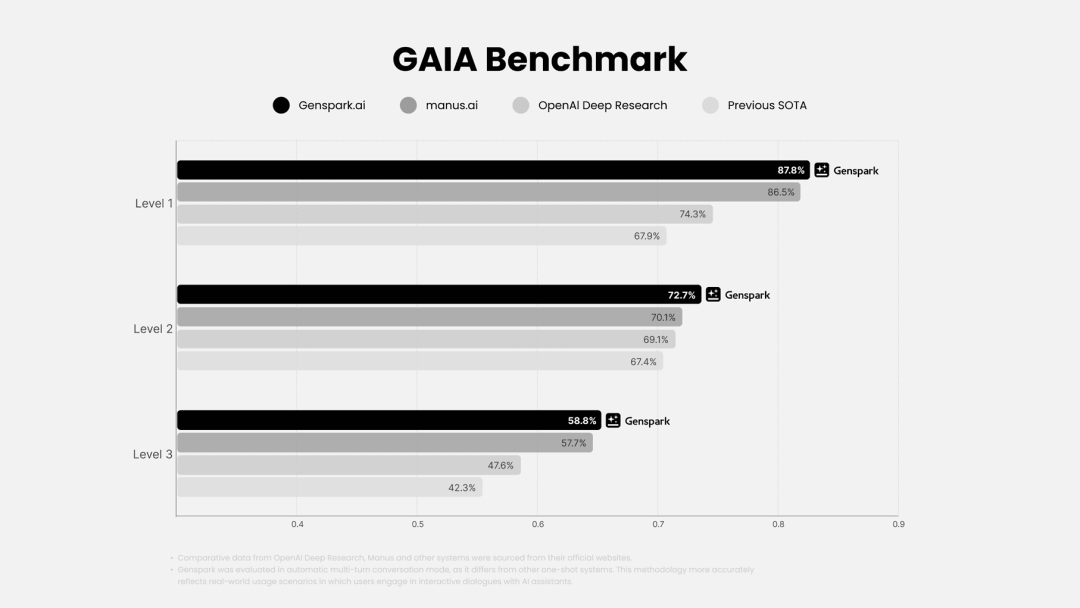
> “无需邀请码,任何人都可以注册使用,这个体验不错 😎”
Rabbit
rabbitOS intern 系统更新,扩展子任务处理能力
Rabbit 智能任务处理系统 rabbitOS intern 迎来更新。该系统能将复杂需求自动分解为子任务,并协调多个专用 Agent 完成。升级后,rabbitOS intern 支持数据处理、代码编写、创意设计、财务分析等多类子任务,执行效率也得到了显著提高。
使用入口:公开测试版面向所有用户开放;前往 rabbitOS intern 官网(hole.rabbit.tech/rabbitos)体验。
权威信源:https://www.rabbit.tech/rabbit-os
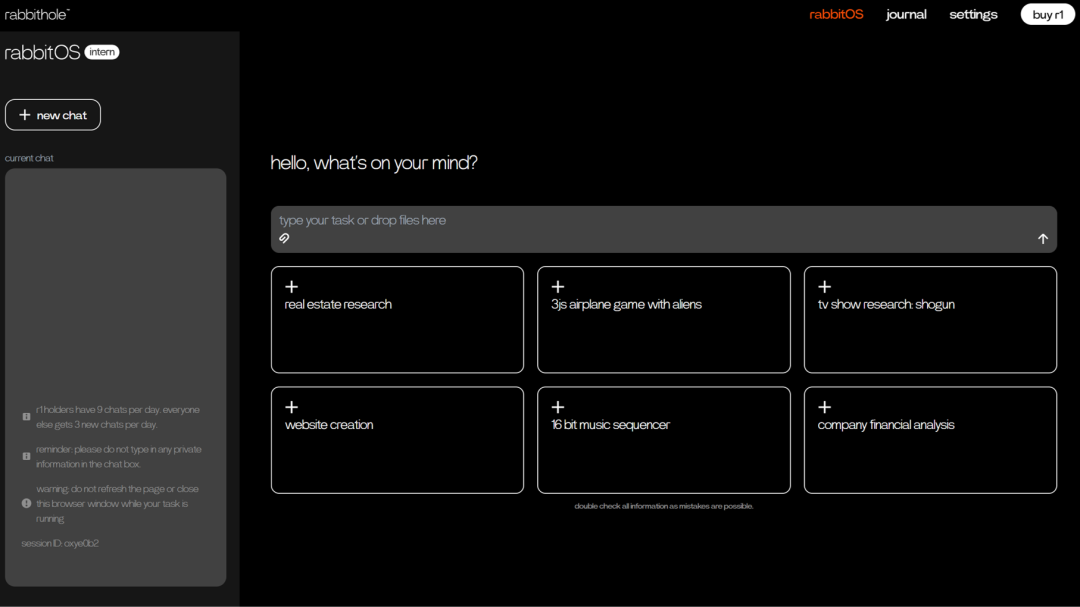
> “又是一个类Manus的Agent产品 👀”
4 月 3 日
中美关税战全面升级
完整回顾本月时间线
4月2日: 美国总统特朗普签署行政令,宣布对所有贸易伙伴加征 10% 基准关税,并针对中国商品进一步上调至 34%,覆盖电动汽车、半导体等关键领域。
4月4日(周五):中国国务院关税税则委员会宣布,自4月10日12:01起,对原产于美国的所有进口商品,在现行适用关税税率基础上加征 34% 关税;商务部、海关总署宣布对 7 类中重稀土实施出口管制;暂停 6 家美国企业输华资质,并将 11 家美国企业列入「不可靠实体清单」@新华社。
4月7日(周一):美国威胁将进一步对华加征 50% 关税。
4月7日:中国中央汇金公司发布公告,将持续加大增持 ETF 规模和力度 @新华社。
4月8日:美国政府宣布,对中国输美商品征收「对等关税」税率由 34% 提高至 84%。
4月9日:中国国务院关税税则委员会宣布,自4月10日12时01分起,调整对原产于美国的进口商品加征关税措施,由 34% 提高至 84% @新华社。将 6 家美国企业列入「不可靠实体清单」@新华社。将 12 家美国实体列入「出口管制管控名单」@新华社。
4月10日:美国政府宣布,对中国输美商品征收「对等关税」税率进一步提高至 125%。
4月11日:中国国务院关税税则委员会宣布,自2025年4月12日起,调整对原产于美国的进口商品加征关税措施,由 84% 提高至 125%;鉴于在目前关税水平下,美国输华商品已无市场接受可能性,如果美方后续对中国输美商品继续加征关税,中方将不予理会 @新华社。
4月12日:美国公布相关备忘录,豁免计算机、智能手机、半导体制造设备、集成电路等部分产品的「对等关税」
4月13日:中国商务部回应,敦促美方正视国际社会和国内各方理性声音,在纠错方面迈出一大步,彻底取消「对等关税」的错误做法,回到相互尊重,通过平等对话解决分歧的正确道路上来 @新华社。
4月15日:美国白宫网站发布关于关键矿产和衍生品 232 调查的有关事实清单,提到因为中国针对美「对等关税」采取报复措施,现在中国出口到美国的商品面临最高达 245% 的关税。
4月16日:中国商务部回应,对于美方这种毫无意义的关税数字游戏,中方不予理会。但倘若美方执意继续实质性侵害中方权益,中方将坚决反制,奉陪到底@新华社。
4月22日:美国总统特朗普对记者称,我们与中国相处得不错,同中方谈判时不会采取强硬态度。对华 145% 关税确实很高,协议达成后美对华关税将大幅下降,但不会降至零。
4月23日:中国外交部回应,对于美国发动的关税战,中方的态度很明确,我们不愿打,也不怕打。打,奉陪到底;谈,大门敞开 @新华社。
4月24日:美国不断有消息称,中美之间正在谈判,甚至将会达成协议。
4月24日:中国外交部回应,这些都是假消息。“据我了解,中美双方并没有就关税问题进行磋商或谈判,更谈不上达成协议。” @新华社
美国政府限制 NVIDIA H20 芯片出口
黄仁勋访华商讨方案,完整回顾本月时间线
美国对中国半导体技术的出口管制历经多年政策演进。2022年,拜登政府限制 A100/H100 等高端AI芯片对华出口,促使 NVIDIA 推出降级版 A800/H800 作为替代方案。随着技术竞争加剧,美国在 2024 年出台 AI Diffusion Rule(2025年5月15日生效),NVIDIA 随即推出中国市场特供版 H20 芯片。
本月,芯片禁令再次升级:
- 4月4日:NVIDIA CEO 黄仁勋参加特朗普海湖庄园晚宴,承诺未来四年在美投资 5000 亿美元建设超算中心,换取 H20 出口禁令暂缓。
- 4月9日:美国政府态度转变,通知 NVIDIA 对中国(含港澳)和其他 D5 国家出口 H20 芯片需要获得新的许可证。
- 4月14日:美国政府进一步通知 NVIDIA 出口许可要求将「无限期有效」。这意味着 H20 芯片向中国的出口可能面临永久性限制。
- 4月15日:AMD MI308 芯片、Intel Gaudi 2D/3D 芯片同样被纳入出口管制范围。
- 4月16日:NVIDIA 披露将在第一季度承担 55 亿美元的资产减记,NVIDIA 股价在盘后交易中下跌约 6%,AMD 也应声下跌。
- 4月17日-18日:NVIDIA CEO 黄仁勋紧急访问中国,与中国客户企业及政府官员会面,强调「中国是 NVIDIA 非常重要的市场」,并商讨新方案。
- 4月30日:据报道,NVIDIA 告知部分中国大客户,正在调整 AI 芯片设计并最快将于 6 月推出新的芯片样品。同时也在研发最新一代 Blackwell 架构的中国特供版。
权威信源:https://www.reuters.com/technology/nvidia-expects-up-55-billion-charge-first-quarter-2025-04-15 | @何立峰会见黄仁勋 | @龚正会见英伟达总裁兼首席执行官黄仁勋

> “中国可以没有英伟达。但是英伟达不能没有中国。”
4 月 4 日
Midjourney
V7(alpha)图像生成模型,提升理解能力与图像质量
Midjourney V7 图像生成模型开启 alpha 测试。V7 模型在文本/图像提示理解的精准度上显著提升,同时整体图像质量、细节表现和连贯性均有大幅优化。此外,V7 是首个默认启用模型个性化功能的版本,能够深度理解用户需求,精准捕捉用户对「美」的偏好,从而生成更符合个人品味的图像。
V7 新功能 Draft Mode(草稿模式)生成成本仅为标准模式的一半,渲染速度却快十倍,是创意迭代的高效工具。用户只需点击 Draft Mode 并启用语音模式,即可通过口述实时生成图像;若需明确执行草稿任务,可在提示词后添加 –draft 参数。
V7 将提供 Turbo(加速) 和 Relax(放松) 两种模型,标准速度模型仍在优化中。未来 60 天内,团队计划高频推出新功能,其中最值得期待的是 V7 角色和主体参考。
使用入口:前往 Midjourney 官网(midjourney.com)体验。
权威信源:https://www.midjourney.com/updates/v7-alpha

> “实测下来,有进步,但不多 🤦♂️”
Microsoft
Muse 世界模型家族迎来 WHAMM 模型,可以实时生成 AI 游戏
Microsoft 专为电子游戏开发的 Muse 世界模型家族迎来新成员 WHAMM 模型。作为 WHAM-1.6B(2025年2月发布)的实时可玩扩展版,WHAMM 显著提升视觉生成速度,输出分辨率翻倍,图像生成速率从每秒 1 帧提升至 10 帧以上,实现高质量视频实时生成。
此外,WHAMM 增强了模型泛化能力,成功适配《雷神之锤 2》等不同风格游戏,展现出强大跨游戏兼容性。
使用入口:前往 Copilot Gaming Experiences 官网(copilot.microsoft.com/wham)试玩。可以通过键盘/控制器操作与模型进行交互,并立即看到操作的效果,本质上实现了在模型内部玩游戏。
权威信源:https://www.microsoft.com/en-us/research/articles/whamm-real-time-world-modelling-of-interactive-environments

> “还是那个问题,游戏里能走回头路吗 🔙”
4 月 5 日
Microsoft
Bing 浏览器上线 Copilot Search 功能
Microsoft Bing 浏览器上线 Copilot Search 功能,结合传统搜索的精准性与 AI 的深度分析能力,重塑了信息获取方式。它能够像专业助手一样阅读、理解并整合网络信息,自动对比不同来源以确保准确性,同时始终提供可靠的信息依据。
它既能快速给出即时答案,也能展开多维度的深入解析,让用户自由控制搜索的深度和方向,从而获得真正个性化的解答体验。
使用入口:前往 Bing 官网(bing.com/copilotsearch)体验 Copilot Search 功能。
权威信源:https://blogs.bing.com/search/April-2025/Introducing-Copilot-Search-in-Bing
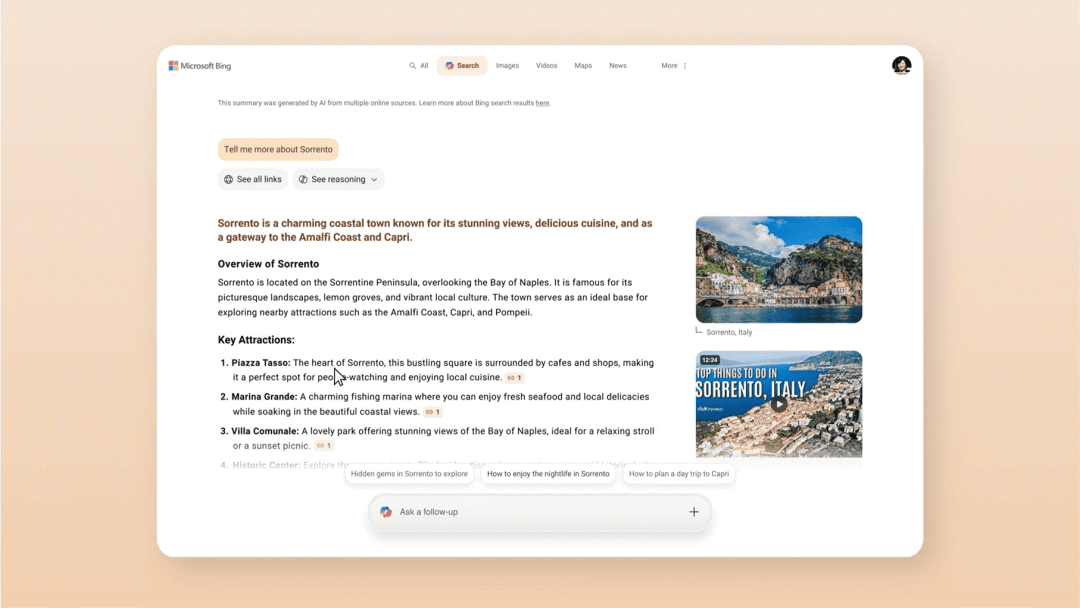
> “Bing要挑战一下Perplexity 👀”
4 月 6 日
Meta
Llama 4 原生多模态模型系列(开源)
LLaMA 4 模型系列采用 MoE(混合专家)架构,支持原生多模态输入,包含 Scout、Maverick 和 Behemoth 三个版本(目前仅开放下载前两个版本)。
Scout(哨兵)模型,激活参数 17B,总参数量 108B,16 个专家;上下文窗口长达 10M Token。
Maverick(独行侠)模型,激活参数 17B,总参数量 402B,128 个专家;多模态支持(文本、图像、视频、音频)强大。
Behemoth(巨兽)模型,仍在训练中,Meta 目前最强大的模型,Scout 和 Maverick 版本均由 Behemoth 训练而来。
使用入口:前往 Llama 官网(llama.com)下载模型;或者调用 API(llama.com/products/llama-api)。
权威信源:https://ai.meta.com/blog/llama-4-multimodal-intelligence
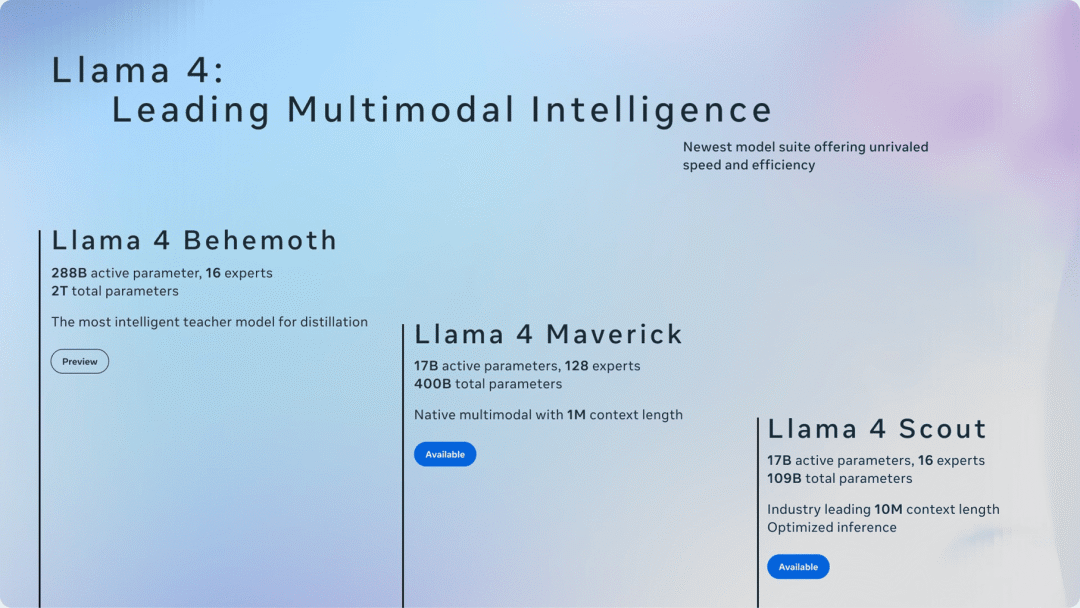
> “相比于月底的Qwen3,Llama 4 没有太多革命性的变化。开源之王的宝座已被阿里夺走 👑”
4 月 7 日
阿里巴巴
通义 LHM 模型,单照片快速生成可控 3D 数字人(开源)
LHM 是一款 3D 数字人生成工具,能仅凭单张照片快速生成可动、可操控的高精度 3D 数字人。该模型采用先进的端到端 Transformer 架构,并结合 SMPL-X 人体先验模型,输出基于高斯技术的逼真 3D 人体模型。
LHM 支持动作重现,允许用户为数字人指定多样化动作(如跳舞、打篮球等),并可直接用作游戏角色,满足游戏开发、VR 交互等场景需求。
使用入口:开源;前往 Github 获取所有代码(github.com/aigc3d/LHM);前往魔搭(modelscope.cn/studios/Damo_XR_Lab/Motionshop2/summary)体验。
权威信源:https://lingtengqiu.github.io/LHM | 官方介绍

> “效果还比较粗糙,期待进一步升级 💪”
NVIDIA
收购初创公司 Lepton AI(贾扬清)
NVIDIA(英伟达)宣布以数亿美元收购由贾扬清创办的初创公司 Lepton AI 。贾扬清及其核心团队将加入 NVIDIA ,Lepton AI 则于 2025 年 5月20日终止运营。
Lepton AI 成立于 2023 年,主营基于 NVIDIA GPU 的云服务器租赁及 AI 工作负载优化服务。此次收购旨在增强 NVIDIA 在数据中心与 AI 基础设施方面的实力,以应对 Google Cloud 、Microsoft Azure 等竞争。
权威信源:https://www.theinformation.com/briefings/nvidia-closes-acquisition-gpu-cloud-startup-lepton

> “看来Nvidia想亲自下场做 AI应用层的服务。从卖卡到卖算力 🤙”
Stanford HAI
The 2025 AI Index Report 发布
斯坦福大学以人为本人工智能研究所(HAI)发布的《2025 AI Index Report》是该机构自 2017 年以来的第八份年度报告,全面分析了人工智能领域的全球发展态势。报告涵盖技术研发、经济影响、社会效益等关键维度,主要结论如下:
- 人工智能在高难度基准测试中的性能持续突破。
- 人工智能加速融入日常生活场景。
- 商业领域投资与使用量创历史新高,对生产力的提升作用显著。
- 美国保持顶尖模型开发领先地位,但中国正快速缩小差距。
- 负责任的人工智能生态系统发展不均衡。
- 全球对人工智能的乐观情绪上升,但地区间存在显著认知差异。
- 人工智能正变得更高效、经济且易于普及。
- 各国政府持续加强人工智能领域的监管与资金投入。
- 计算机科学教育规模扩大,但教育机会不平等问题依然存在。
- 前沿技术发展速度有所放缓。
- 人工智能对科学研究的推动作用获得广泛认可和赞誉。
- 复杂推理仍是当前技术面临的主要挑战。
使用入口:前往 Stanford HAI 官网(hai.stanford.edu/ai-index/2025-ai-index-report)下载完整报告。
权威信源:报告概要

4 月 8 日
阶跃星辰
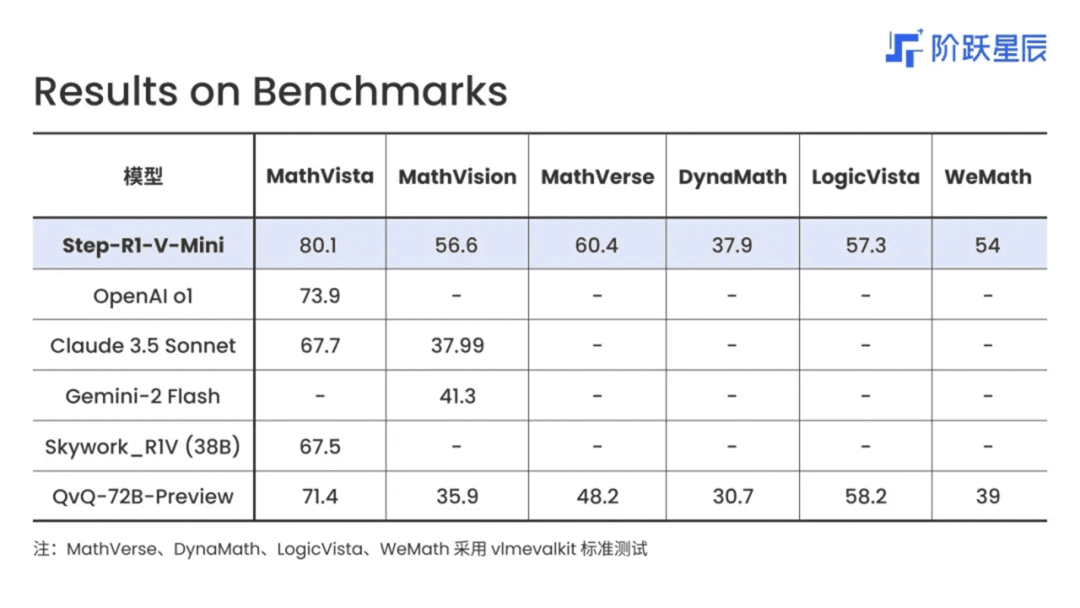
Step-R1-V-Mini 多模态推理模型,图像感知能力优秀
Step-R1-V-Mini 是一款多模态推理模型,支持图像与文本联合输入并输出文字推理结果,能够高效完成复杂的跨模态推理任务。
该模型具备出色的图像感知能力,可精准识别物体和场景并进行深度逻辑推理。模型性能卓越,不仅能处理 LeetCode Hard 级别的算法题,还在 MathVision 视觉推理榜单中位列国内第一。
使用入口:前往阶跃官网(yuewen.cn)体验;或者调用 API(platform.stepfun.com)。
权威信源:官方介绍
Amazon
Nova Sonic 通用音频基础模型,单一框架整合理解和生成能力
传统语音系统将语音识别(ASR)、自然语言处理(NLP)和语音合成(TTS)拆分为独立模块,导致对话缺乏自然流畅性,难以保留语调、韵律和说话风格等关键细节。
Nova Sonic 模型则有效解决了这类困扰,将理解与生成能力整合到单一框架中,因此能够精准捕捉语音中的细微特征(如停顿、犹豫),并动态调整回应时机和风格使对话更自然,大幅提升了人机交互体验。
使用入口:前往 Amazon Nova 官网(nova.amazon.com/sonic)体验;开发者可以前往 Amazon Bedrock 调用模型 API。
权威信源:https://www.aboutamazon.com/news/innovation-at-amazon/nova-sonic-voice-speech-foundation-model

> “Amazon模型也全方位覆盖了 🎊”
4 月 9 日
Together AI X Agentica Project
DeepCoder-14B 编程推理模型,性能卓越(开源)
Together AI 与 Agentica Project 联合开发全开源编程专用大模型 DeepCoder-14B ,支持 64K 长上下文推理。
在 LiveCodeBench 基准测试中,该模型以 60.6% 的得分超越 o1(59.5%)并接近 o3-mini(60.9%),展现卓越代码生成与推理能力。DeepCoder-14B 基于 DeepSeek-R1-Distilled-Qwen-14B 微调优化,并采用强化学习技术提升代码质量,能生成高准确性、强逻辑性代码,满足复杂编程需求。
使用入口:全开源(模型权重/数据集/代码/训练方案等);前往 HugingFace 获取(huggingface.co/agentica-org/DeepCoder-14B-Preview)。
权威信源:https://www.together.ai/blog/deepcoder

Jina AI
jina-reranker-m0 多模态多语言重排器
jina-reranker-m0 是一款多模态、多语言重排器(reranker),核心能力在于对包含丰富视觉元素的文档进行重排和精排,同时兼容跨语言场景。
当用户输入一个查询(query)以及一堆包含文本、图表、表格、信息图或复杂布局的文档时,模型会根据文档与查询的相关性,输出一个排序好的文档列表。模型支持超过 29 种语言及多种图形文档样式,例如自然照片、截图、扫描件、表格、海报、幻灯片、印刷品等等。
使用入口:开源;HugingFace 开源链接(huggingface.co/jinaai/jina-reranker-m0);调用 API 链接(jina.ai/?sui&model=jina-reranker-m0)。
权威信源:官方介绍

> “基于Qwen2-VL-2B改造而来。”
阿里巴巴
阿里云百炼上线业界首个全生命周期 MCP 服务
阿里云百炼上线业界首个全生命周期 MCP 服务,无需用户管理资源、开发部署、工程运维等工作,5 分钟即可快速搭建一个专属 MCP Agent,大幅降低 Agent 的开发门槛。
百炼平台首批上线了高德、无影、Fetch、Notion 等30 多款阿里巴巴集团和三方 MCP 服务,覆盖生活信息、浏览器、信息处理、内容生成等领域,可满足不同场景的 Agent 应用开发需求。
同日,阿里云还预告了 AI Agent Store 愿景,通过 Agent Store 这种创新模式,把阿里巴巴集团和生态伙伴的 Agent 向外开放,让各行各业的人都可以拥有自己专属的助理。
使用入口:前往阿里云百炼官网(bailian.console.aliyun.com)体验。
权威信源:官方介绍 | 赛博禅心

> “只支持将MCP用于阿里云百炼内部的智能体,生态比较封闭 📦”
腾讯
腾讯云上线 AI 开发套件,快速搭建 AI Agent 小程序
腾讯云正式发布「AI开发套件」,帮助开发者最快 5 分钟搭建业务型 AI Agent,支持 MCP 插件托管服务,插件开发、部署、运维全「打包」,无需自搭服务器、运维环境,让 Agent 扩展能力真正「即插即用」。
使用入口:前往腾讯云开发平台(tcb.cloud.tencent.com/index)体验。
权威信源:官方介绍
> “云厂商都打算入局Agent开发生态 👀”
Google Cloud Next 25 大会
与 Agent 有关的 A2A、SDK、Google Agentspace…
Google Cloud Next 25 大会于4月9日至11日在美国拉斯维加斯举行,组织了 10 场主题演讲、700 场专业会议,展会也有 250 多家赞助商参与。大会期间共发布 229 项公告,覆盖 Multi-Agent System、Al Infrastructure、Application Development、Databases、Data Analytics 等 14 个领域。月刊挑选与 Agent 最密切的三项内容进行介绍。
Agent2Agent Protocol:A2A 协议由 Google 牵头、逾 50 家科技巨头支持,旨在统一 AI Agent 交互标准,使智能体之间能够无缝通信,实现跨平台、跨框架协作。
Agent Development Kit(ADK):一个面向 AI Agent 开发的 Python 框架,旨在简化多智能体系统的构建、管理和部署流程,支持模块化设计及 MCP 、A2A 协议。
Google Agentspace:企业级 AI 智能体平台,集中管理和一键部署 Google 和 合作伙伴的智能体,并将智能体直接嵌入员工 Chrome 浏览器,提升工作效率和决策水平。
权威信源:https://cloud.google.com/blog/topics/google-cloud-next/google-cloud-next-2025-wrap-up

> “模型的声音越来越少,Agent的声音越来越多 🔊”
Firebase Studio 辅助编程 IDE,快速构建与部署全栈应用
Firebase Studio 是一款 AI 编程 IDE(集成开发环境),旨在助力开发者通过简单提示词在浏览器内快速构建并部署生产级全栈应用(前端、后端、API 及移动应用),大幅降低技术门槛。
该平台兼容多种主流编程语言和框架,包括 React、Next.js、Angular、Vue.js 等前端技术,以及 Node.js、Python Flask、Java 等后端方案,同时支持 Flutter 和 Android 移动开发。无论是从零开始的新项目,支持从零开发或基于模板、现有代码的二次开发,显著降低全栈应用的门槛。
使用入口:前往 Firebase Studio 官网(firebase.studio)体验。
权威信源:https://firebase.google.com/docs/studio

> “又一个Vibe Coding应用,大厂真的什么都做 🤙”
Augment Code 辅助编程插件,支持超长上下文
Augment Code 是专为开发者设计的智能编程助手,上下文长达 20 万 tokens,支持大规模代码库的高效开发。该插件不仅能编写和调试代码,还能自动生成 PR、执行终端命令,并学习开发者习惯,适配项目规范,实现从需求到提交的自动化闭环。
其可视化调试功能可识别 UI 问题并推荐修复方案,深度集成 GitHub、Linear、Notion 等主流工具,支持快速接入 Supabase、Figma 等技术栈,真正实现从编码到部署的智能化开发体验。
使用入口:可在 VS Code 和 JetBrains 中使用;前往 Augment Code 官网(augmentcode.com)下载安装。
权威信源:测评
> “还是那句话,大厂真的什么都做 🤙🤙🤙”
企业家座谈会
总理主持召开经济形势专家和企业家座谈会,稚晖君发言
中共中央政治局常委、国务院总理李强主持召开经济形势专家和企业家座谈会,听取对当前经济形势和下一步经济工作的意见建议。
智元机器人联合创始人兼 CTO 彭志辉在座谈会上发言。彭志辉是 B 站知名 UP 主「稚晖君」,被网友亲切称为「野生钢铁侠」,2018年从电子科技大学研究生毕业就职于 OPPO 研究院 AI 实验室,2020年以「华为天才少年计划」最高档年薪入职华为团队,2022 年底从华为离职,2023 年 2 月联合创立智元机器人。
权威信源:https://www.gov.cn/yaowen/tupian/202504/content_7017779.htm | 媒体报道

4 月 10 日
月之暗面
Kimi-VL 与 Kimi-VL-Thinking 轻量级视觉语言模型(开源)
Kimi-VL 和 Kimi-VL-Thinking 多模态模型基于 MoE 架构,激活参数 2.8B,总参数 16B,支持 128K 上下文窗口,均可处理单图、多图、视频以及含视觉信息的长文档输入。
Kimi-VL-Thinking 是经过强化学习训练的增强版,特别激活了长思维链推理能力(Long CoT)。在 MMMU、MathVision 和 MathVista 等高难度推理基准测试中,其部分表现可媲美甚至超越更大参数量的前沿模型。
使用入口:开源;前往 HugingFace 获取模型权重(huggingface.co/moonshotai/Kimi-VL-A3B-Instruct,https://huggingface.co/moonshotai/Kimi-VL-A3B-Thinking);前往 Github 获取代码(github.com/MoonshotAI/Kimi-VL);技术报告(arxiv.org/abs/2504.07491v1)。
权威信源:官方介绍

> “为视觉推理模型的发展做了一些贡献 🎉”
商汤
日日新 SenseNova V6 多模态融合大模型体系,支持中长视频深度解析
日日新(SenseNova)是商汤科技推出的大模型体系。最新版本 SenseNova V6 具备强大的多模态推理与交互能力,其中 SenseNova V6 Video Turbo 是国内首个支持 10 分钟中长视频深度解析的大模型。
日日新大模型体系包含自然语言处理模型「商量(SenseChat)」、文生图模型「秒画」和数字人视频生成平台「如影(SenseAvatar)」等核心产品。
使用入口:前往商量官网(chat.sensetime.com)体验。
权威信源:官方介绍

> “上下文最大只有32K,有点跟不上时代了 🤐”
字节跳动
Multi-SWE-bench 基准测试,评估大模型多语言代码修复泛化能力(开源)
Multi-SWE-bench 是首个开源多语言代码修复基准测试,在原有单语言评测集 SWE-bench(Python)基础上全面扩展,新增 Java、Go、Rust、C、C++、TypeScript、JavaScript 等 7 种主流编程语言,并基于 1,632 个真实 GitHub Issue 构建了丰富的测试任务。
Multi-SWE-bench 标志着自动编程评估从实验室单语言任务向实用化、多语言、全栈工程场景演进,为 AI 编程助手提供了更严格、贴近实际开发需求的评估标准。
使用入口:开源;前往 HugingFace 获取数据(huggingface.co/datasets/ByteDance-Seed/Multi-SWE-bench);前往 Github 获取代码(github.com/multi-swe-bench/multi-swe-bench)。
权威信源:官方介绍

> “AI编程领域的基准测试 🥇”
4 月 11 日
OpenAI
BrowseComp 基准测试,评估 AI Agent 复杂信息检索能力(开源)
鉴于当前主流基准测试(如 SimpleQA)已被 GPT-4o 等模型轻松饱和,OpenAI 推出 BrowseComp 开源基准测试,专门评估 AI Agent 在互联网上检索深度交织、难以获取信息的能力。
该测试包含 1266 个高难度问题,Agent 可能需遍历数百个网站方能找到答案,为衡量 AI 信息检索性能提供了更严苛标准,以应对 AI Agent 搜索信息能力日益重要且复杂信息定位能力评估愈发关键的趋势。
使用入口:开源;前往 Github 获取(github.com/openai/simple-evals)。
权威信源:https://openai.com/index/browsecomp

> “更难的基准测试,可以更好地推动Agent的进步 🥇”
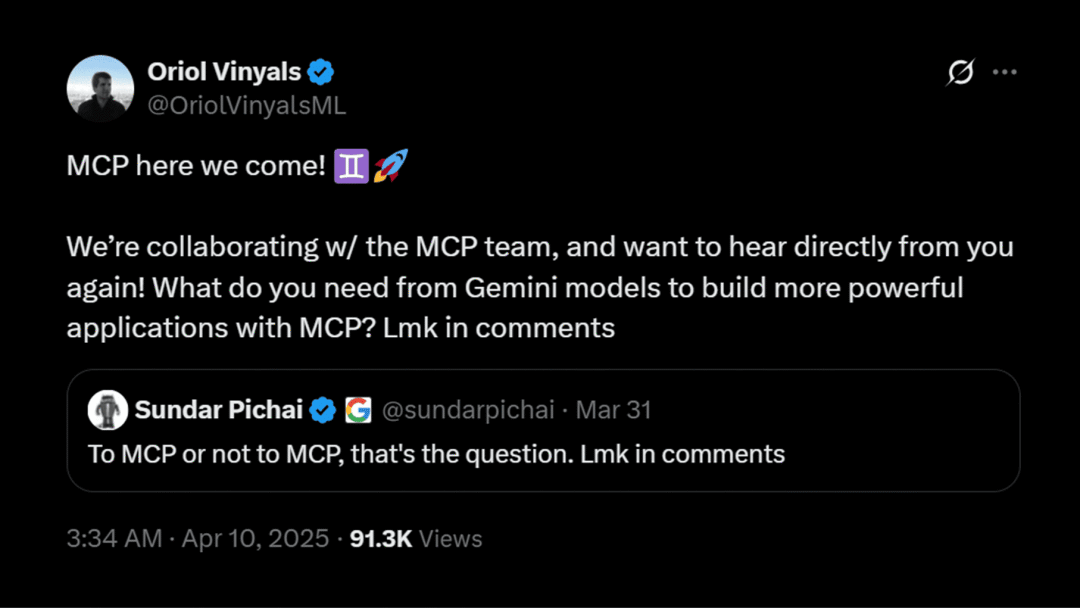
Gemini 模型将支持 MCP 协议
继 Google CEO Sundar Pichai 于 3 月 31 日发帖暗示后,Google DeepMind 负责人 Oriol Vinyals 于 4 月 10 日确认,Google 正与 MCP 团队合作,旗下 Gemini 模型将支持 MCP 协议。此举为 Google 官方首次明确表态,旨在推动 AI Agent 间的互联互通。
权威信源:https://x.com/OriolVinyalsML/status/1910053783968641123
> “不太理解从模型层面支持MCP该如何实现,期待Google下一步揭晓 👂”
4 月 13 日
昆仑万维
Skywork-OR1推理模型系列,显著提升数学与代码等任务性能(开源)
Skywork-OR1 作为 Skywork-O1 推理模型的升级版本,在保持相同参数规模下显著提升了推理性能,尤其在数学、代码和通用任务方面表现突出。
该系列包含三个版本:Skywork-OR1-Math-7B 专注于数学领域,Skywork-OR1-7B-Preview 兼具数学与代码能力,而旗舰版本 Skywork-OR1-32B-Preview 则专为处理更高复杂度的任务而设计。
使用入口:全开源(模型权重/训练数据集/完整训练代码);前往 HugingFace 获取模型权重(huggingface.co/Skywork);前往 Github 获取代码(github.com/SkyworkAI/Skywork-OR1)。
权威信源:https://capricious-hydrogen-41c.notion.site/Skywork-Open-Reaonser-Series-1d0bc9ae823a80459b46c149e4f51680 | 官方介绍
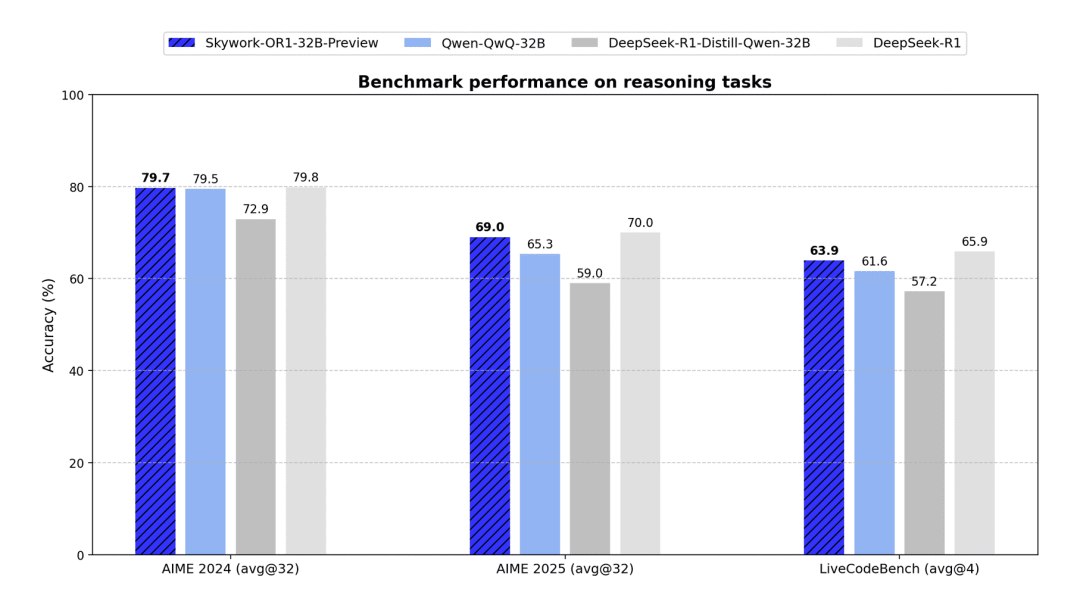
> “最大只有32B,明显是为了本地化部署准备的 🧐”
4 月 14 日
字节跳动
Seed-Thinking-v1.5 深度思考模型
Seed-Thinking-v1.5 深度思考模型采用 MoE 架构,激活参数 20B,总参数 200B,通过高效的结构设计,实现了卓越性能与计算效率的平衡。
模型在多项权威基准测试中表现突出:AIME 2024 得分 86.7,Codeforces 的 pass@8 达到 55.0%,GPQA 测试中取得 77.3 分,说明其在复杂推理、编程和专业知识问答等领域能力优秀。
使用入口:前往火山引擎调用 API。
权威信源:https://github.com/ByteDance-Seed/Seed-Thinking-v1.5 | 官方介绍

> “这个模型就是火山引擎上的Doubao-1.5-Thinking-Pro 🔍”
月之暗面 X Numina
Kimina-Prover 数学定理证明模型,Lean 4 形式化数学证明表现出色(开源)
Numina 和月之暗面 Kimi 团队联合开发的 Kimina-Prover,是一款专注于数学定理证明的大模型。该模型基于 Qwen2.5-72B 架构,采用 Kimi k1.5 大规模强化学习流程训练,在 Lean 4 形式化数学证明领域表现出色。
在权威的 miniF2F 基准测试中,仅需 pass@8192 的采样预算就达到了 80.7% 的通过率,显著超越了此前记录。
使用入口:开源了 Kimina-Prover 的 1.5B 和 7B 参数的蒸馏版本,用于数据生成的 Kimina-Autoformalizer-7B 模型,修订过的 miniF2F 基准测试数据集。前往 HuggingFace 获取模型和数据集(huggingface.co/collections/AI-MO/kimina-prover-preview-67fb536b883d60e7ca25d7f9);前往 Github 获取代码(github.com/MoonshotAI/Kimina-Prover-Preview);技术报告(arxiv.org/abs/2504.11354)。
权威信源:官方介绍
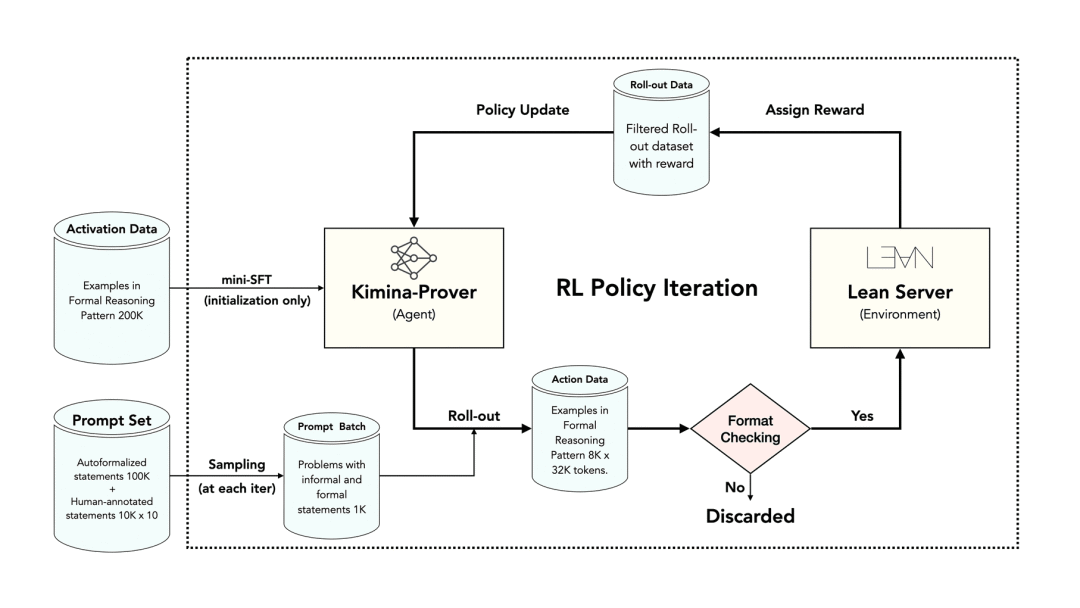
> “巧合的是,月底Deepseek也发布了一个Prover模型 🧐”
小鹏汽车
小鹏世界基座模型启动研发
小鹏汽车研发团队基于其优质自动驾驶训练数据,已成功开发多个尺寸的基座模型,并已启动 72B 超大规模参数的世界基座模型研发,参数量约为当前主流 VLA 模型的 35 倍。
小鹏世界基座模型的一大核心优势是具备链式推理能力(CoT),能在充分理解现实世界基础上进行复杂常识推理,并将结果转化为方向盘、刹车等控制信号,实现与物理世界的交互。
权威信源:官方介绍
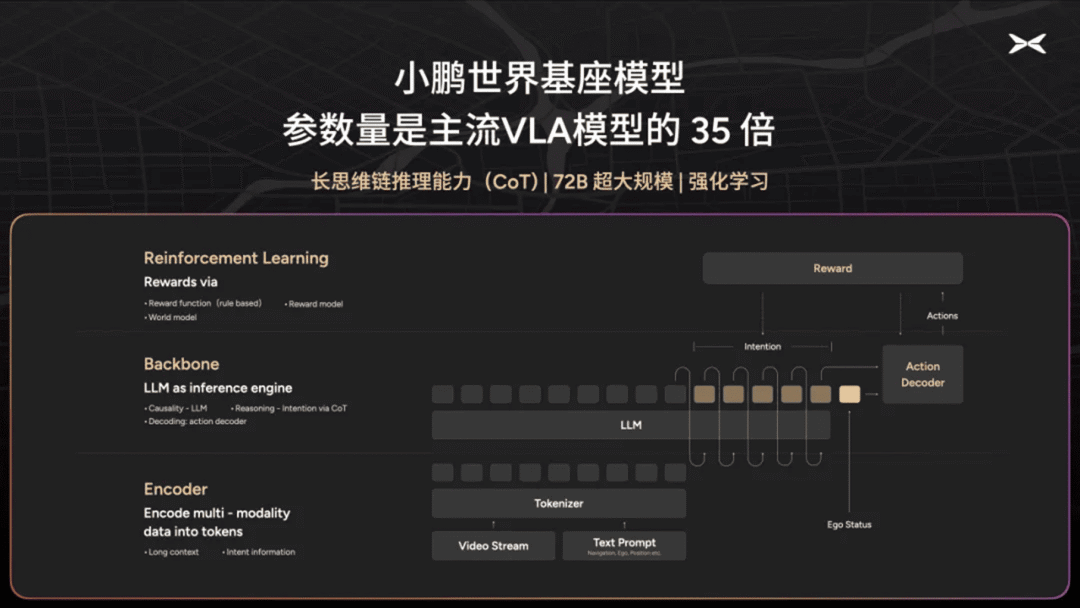
> “自动驾驶企业都在研发自己的世界模型 🚗”
Hugging Face
收购 Pollen Robotics,发售开源人形机器人 Reachy 2
Hugging Face 宣布完成对法国机器人公司 Pollen Robotics 的收购,并正式推出其旗舰产品——售价 7 万美元的 Reachy 2 人形机器人。Reachy 2 采用完全开源架构,集成先进硬件与用户友好软件平台,为科研人员提供高度可定制的开发环境,已获康奈尔大学等顶尖实验室采用。
Pollen Robotics(创立于 2016 年,源自法国 Inria)是开源人形机器人领域的领先者,此次收购将加强 Hugging Face 在具身智能领域的技术布局。
权威信源:https://huggingface.co/blog/hugging-face-pollen-robotics-acquisition

> “看来Hugging Face 也认为人形机器人会是未来的重要开源方向 🤖”
4 月 15 日
智谱
GLM-4 和 GLM-Z1 模型系列(开源),启用全新域名 Z.ai
智谱本次开源了三大类模型(对话/基座/推理),涵盖9B和32B两种参数量级,具体如下:
对话模型:
- GLM-4-9B-0414
- GLM-4-32B-0414
基座模型:
- GLM-4-32B-Base-0414
- 上线的基座模型提供 GLM-4-Air-250414 和 GLM-4-Flash-250414 两个版本,其中后者完全免费。
推理模型:
- GLM-Z1-9B-0414
- GLM-Z1-32B-0414
- GLM-Z1-Rumination-32B-0414
- 上线的推理模型提供 GLM-Z1-AirX、GLM-Z1-Air、GLM-Z1-Flash 三个版本,其中最后版本完全免费。
使用入口:开源;前往 HugingFace 获取模型(huggingface.co/THUDM);前往官网(Z.ai)体验;或者前往 MaaS 平台调用 API(bigmodel.cn)。
权威信源:官方介绍

> “域名看起来就很昂贵 💰”
OpenAI
GPT-4.1 模型系列,上下文长度突破 1M
GPT-4.1 在 GPT-4o 基础上进行了升级,在编程能力、指令理解和长文本处理等核心领域实现了显著突破。
该系列包含 GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano 三个版本,均支持高达 1 Million Token 的超长上下文处理能力,使其能够高效处理大型代码库、复杂技术文档以及其他需要超长上下文支持的任务。
使用入口:目前仅支持通过 API 调用(platform.openai.com/docs/guides/text?api-mode=responses#prompting-gpt-4-1-models);GPT-4o 和 GPT-4o mini 也将继续通过 API 提供。
权威信源:https://openai.com/index/gpt-4-1
> “GPT-4.1系列明显是一个可生产用的成熟模型。但是,之前的GPT-4.5就有些让人困惑了 🤯”
腾讯 X 上海交通大学
DeepMath-103K 数学数据集,面向强化学习和高级推理(开源)
DeepMath-103K 是一个高质量数据集,面向强化学习(RL)与高级数学推理。该数据集包含约 10.3 万道题目,覆盖代数、微积分、数论、几何、概率及离散数学等多学科领域,聚焦高难度题目(难度等级 5-9 级),并经过严格去污处理。
每道题目均附带可验证的最终答案,以及由 R1 生成的 3 种不同解法,适用于监督微调、知识蒸馏和奖励建模等多种训练方法。
使用入口:开源;前往 HugingFace(huggingface.co/datasets/zwhe99/DeepMath-103K)或 Github(github.com/zwhe99/DeepMath)获取;技术报告(arxiv.org/abs/2504.11456)。
权威信源:https://x.com/tuzhaopeng/status/1912057561110782446

> “RL训练又有了开箱即用的好数据集 🥳”
字节跳动
Seedream 3.0(Mogao)图像生成模型,原生高清输出与商业级文本效果
Seedream 3.0 图像生成基础模型,原生支持高分辨率和中英双语,在画质、结构、文字、美感与真实度方面均有提升。
Seedream 3.0 原生支持 2K 高清直出,适配多种比例,无需后处理即可满足海报级需求;生成速度大幅提升,3 秒即可输出高品质图像。
模型优化了 小字生成和文本排版,使 AI 图像达到商业级设计标准。同时,美学表现显著增强,减少结构错误和 AI 感,让画面更具感染力,适用于专业视觉创意场景。
使用入口:前往即梦官网(jimeng.jianying.com)体验;或者调用 API(volcengine.com/docs/85128/1526761)。
权威信源:https://team.doubao.com/tech/seedream3_0 | 官方技术报告

Seedream 3.0 正式发布之前,曾以 Mogao 的名字登顶 Artificial Analysis 文生图榜单。
权威信源:https://x.com/ArtificialAnlys/status/1912122278722379903

> “经测试,中文输出能力又有了提升,实用性再次增强 👍”
可灵
正式迈入 2.0 时代!可灵 2.0(大师版)&& 可图 2.0 模型发布
可灵 2.0(大师版)视频生成模型在语义理解、动态表现和画面质感上大幅优化,生成效果更自然流畅。
可图 2.0 图像模型支持 60+ 种艺术风格,画面更具电影级质感,精准还原复杂创意。
此外,产品也有更新:视频生成新增 多模态编辑功能,图像生成新增 图片编辑 和 风格转绘功能,进一步拓展了创作自由度。
使用入口:前往可灵官网(app.klingai.com)体验;或者调用 API(klingai.com/cn/dev)。
权威信源:https://app.klingai.com/cn/release-notes | 官方介绍

> “可灵2.0比最初的1.0贵了10倍,各位觉得值得吗 ❓”
阿里巴巴
魔搭上线 MCP 广场,打造最大中文 MCP 服务中心
阿里云的 AI 开源社区魔搭(ModelScope)推出了全新的 MCP 广场,成为最大的中文 MCP 社区。该平台上架了超过千款 MCP 服务,并独家发布了支付宝和 MiniMax 等新服务,为 AI 开发者提供丰富的资源,推动 AI 应用的创新。
使用入口:前往 ModelScopeMCP 广场官网(modelscope.cn/mcp)体验。
权威信源:官方介绍

> “比百炼更开放的平台,支持第三方客户端接入。可惜现阶段还无法自己添加MCP Server 💪”
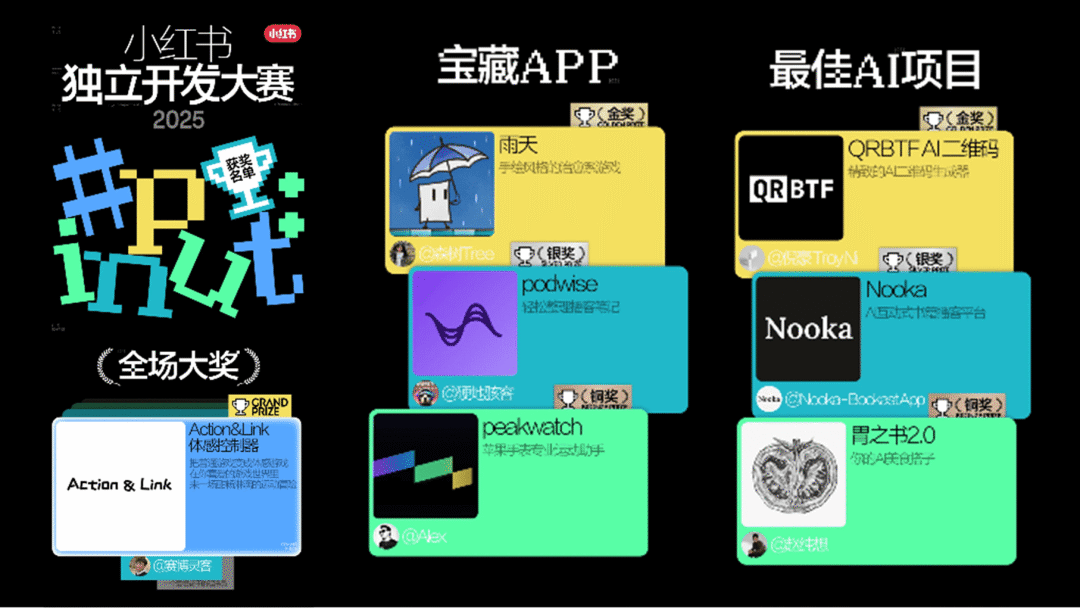
小红书
独立开发者大赛 2025 颁奖
小红书《独立开发者大赛 2025》正式公布获奖名单并举行颁奖仪式。据官方透露,目前小红书活跃着超 5 万名独立开发者,独立开发相关内容较去年增长 146%,相关话题阅读量破 5 亿。以下是获奖项目简介:
全场大奖
- Action&Link 体感控制器,把普通游戏变成体感游戏,在你喜爱的游戏世界里,来一场酣畅淋漓的运动冒险(@赛博灵客)
宝藏APP
- 金奖:雨天,手绘风格的治愈系游戏(@森树Tree)
- 银奖:Podwise,轻松理播客笔记(@硬地骇客)
- 铜奖:Peakwatch,苹果手表专业运动助手(@Alex)
最佳AI项目
- 金奖:QRBTF AI 二维码,精致的 AI 二维码生成器(@倪豪 TroyNi)
- 银奖:Nooka,AI 互动式书籍播客平台(@Nooka-Bookast App)
- 铜奖:胃之书(2.0),你的 AI 美食搭子(@赵纯想)
五大特别单元
- 最佳00后开发者:梦境社交Dreamoo,记梦、绘梦、解梦的社交app(@Sidrel)
- 出海先锋奖:CrowdCore,出海网红营销自动化 AI Agent(@北美创业的阿莱克斯)
- 最佳创意奖:FocusFlight专注飞机,从全球航线到专注顶峰(@专注飞机FocusFlight)
- 浪漫主义奖:魂旅,身在工位,魂游万里(@Highway海玮)
- 社区人气奖:小猫补光灯,一键补光,照亮你的美(@花叔(只工作不上班版)
权威信源:官方介绍 | @WaytoAGI现场纪实 | @暗涌 | @新榜
4 月 16 日
上海人工智能实验室
InternVL3(书生·万象3.0)多模态大语言模型系列(开源)
InternVL3(书生·万象3.0)多模态模型,能够高效处理文字、图片、视频等多种模态信息。其能力全面升级后,在图形用户界面(GUI)Agent、建筑图纸理解、空间感知推理以及通识学科推理等任务中表现尤其突出。
该模型系列涵盖多种参数量版本,包括 1B、2B、8B、9B、14B、38B 和 78B,可满足不同场景下的计算需求与性能要求。
使用入口:开源;前往 HugingFace(huggingface.co/OpenGVLab/InternVL3-78B)或 Github(github.com/OpenGVLab/InternVL)获取模型;技术报告(huggingface.co/papers/2504.10479);前往官网(chat.intern-ai.org.cn)体验。
权威信源:https://internvl.github.io/blog/2025-04-11-InternVL-3.0 | 官方介绍

OpenAI
Codex CLI 本地命令行智能编程工具,集成最新推理模型(开源)
Codex CLI 是一款面向开发者的本地命令行智能编程工具,深度集成了 OpenAI 最新推理模型,为开发者提供智能编程辅助。
该工具通过简单的命令即可实现代码生成、问题修复等复杂任务。用户只需下载对应平台的二进制文件并完成基础配置,即可在本地环境中享受智能化的代码交互体验。
使用入口:开源;支持主流编程语言;前往 Github 获取(github.com/openai/codex)。
权威信源:https://help.openai.com/en/articles/11096431-openai-codex-cli-getting-started

> “对标Claude Code 📍”
JetBrains
Junie Agent 编程助手深度集成到 IDE
Junie 是一款深度集成于 IDE 环境的 Agent 编程助手,能高效处理代码编写与调试任务。其核心优势在于深度结合了 JetBrains IDE 的强大功能,将原本需要数小时完成的工作压缩至更短周期。
它基于 Claude 和 GPT 等大模型,既可独立完成常规开发,也能与开发者协同解决复杂问题。最新版本进一步强化了复杂任务处理能力,显著提升开发效率与代码质量。
使用入口:Junie 已经兼容 IntelliJ IDEA Ultimate、PyCharm Pro、WebStorm 和 GoLand 等 IDE,未来很快支持 PhpStorm、RustRover 和 RubyMine 等 IDE。前往 Junie 官网(jetbrains.com/zh-cn/junie)下载。
权威信源:https://blog.jetbrains.com/blog/2025/04/16/jetbrains-ides-go-ai
> “AI编程会成为所有IDE的标配 🧐”
4 月 17 日
OpenAI
o3 和 o4-mini 视觉推理模型,o 系列旗舰模型
o3 和 o4-mini 是 OpenAI(也是全球)目前智能水平最高、能力最全面的视觉推理模型,在编程、数学、科学计算和视觉理解等复杂任务上实现了显著突破。相较前代,新模型回答前会进行更深入思考,并首次具备图像主动处理能力,可自主执行裁剪、增强等操作以精准提取关键信息。
此外,o3 和 o4-mini 经过专门训练,能主动调用并整合 ChatGPT 的所有工具(含网络搜索、Python 数据分析、视觉推理及图像生成等),输出详尽答案。这标志着 ChatGPT 正在从 AI 助手向具备自主问题解决能力的 AI 系统演进。
使用入口:前往 ChatGPT 官网(chatgpt.com)体验;或者调用 API(openai.com/api)。
权威信源:https://openai.com/index/introducing-o3-and-o4-mini

> “经测试,这两个模型工具调用能力有了非常大的进步,利好Agent的开发 🥳”
字节跳动
豆包1.5 · 深度思考模型上线
豆包1.5 · 深度思考模型采用 MoE 架构,激活参数 20B,总参数 200B,在数学、编程、科学推理及创意写作等领域的能力卓越,经达到或接近全球第一梯队水平。本次发布了 Doubao-1.5-thinking-pro(基础推理模型)和 Doubao-1.5-thinking-pro-vision(支持多模态处理的视觉推理)两个版本。
使用说明:豆包 App 基于豆包1.5・深度思考模型进行了定向训练,将联网能力和深度思考进行了深度绑定,类似人类「边想边搜」的思维方式。
使用入口:前往豆包官网(doubao.com)和移动 App 体验;企业用户可以在火山方舟平台调用 API。
权威信源:官方介绍

Microsoft
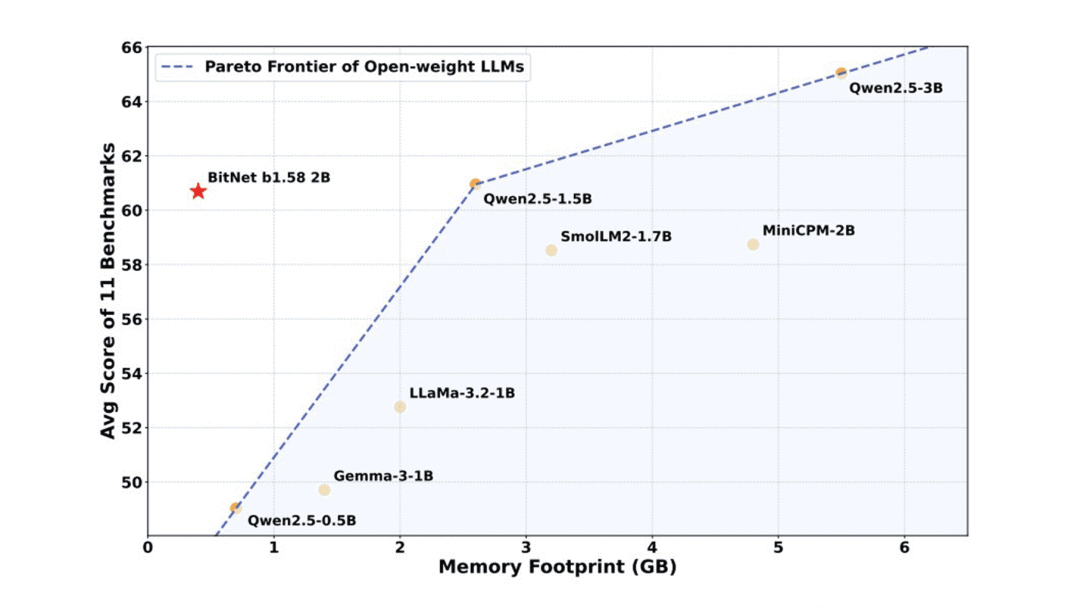
BitNet b1.58 语言模型,低精度架构提升计算效率(开源)
BitNet b1.58 是一款原生 1-bit 大模型,采用了创新的 1.58-bit 低精度架构,内存占用仅 0.4GB,在保持高性能的同时大幅提升了计算效率。
该模型参数量 2B,有效证明了原生 1-bit 大模型性能可以媲美类似规模的领先开源全精度模型,同时在计算效率(内存、能耗、延迟)方面具有显著优势。
使用入口:开源;前往 HugingFace 获取模型(huggingface.co/microsoft/bitnet-b1.58-2B-4T);前往 Github 获取代码(huggingface.co/microsoft/bitnet-b1.58-2B-4T);前往 Demo 页面(bitnet-demo.azurewebsites.net)试玩。
权威信源:技术报告:https://arxiv.org/abs/2504.12285
> “如果这条路线可行的话,可能以后,电冰箱里都会装载一个小模型 😎”
理想汽车
MindGPT 3.0 深度思考能力媲美 DeepSeek
理想汽车宣布其智能助手「理想同学」完成重要升级,搭载的 MindGPT 3.0 模型现已全面上线。此次升级显著提升了人工智能的性能,尤其是深度思考能力,使其能与行业领先的 DeepSeek 等模型相媲美。
使用入口:前往理想同学官网(livis.com)或者 App 体验。
权威信源:官方介绍

阿里巴巴
通义万相 Wan2.1-FLF2V-14B 首尾帧生视频模型(开源)
Wan2.1-FLF2V-14B 是业界首个百亿参数规模的开源首尾帧视频模型。该模型参数量 14B,可以根据用户指定的开始和结束图片,生成一段能衔接首尾画面的 720p 高清视频。此次升级能满足用户更可控、更定制化的视频生成需求。
使用入口:开源;前往 HugingFace 获取模型(huggingface.co/Wan-AI/Wan2.1-FLF2V-14B-720P);前往 Github 获取代码(github.com/Wan-Video/Wan2.1)。前往万相官网(wan.video/wanxiang/videoCreation)体验。
权威信源:官方介绍

> “阿里真的很认真地在做开源 👏”
字节跳动
UI-TARS-1.5 多模态智能体,增强高阶推理能力(开源)
UI-TARS-1.5 是一款多模态智能体,能够在虚拟环境中执行复杂任务,比如操作桌面应用、浏览器和游戏自动化。相比前代 UI-TARS,1.5 版本通过强化学习增强了高阶推理能力,实现了「先思考后行动」决策模式,提升了在未知任务中的泛化能力。
UI-TARS-1.5 在 7 个主流 GUI 评测基准中达到 SOTA 水平,更首次实现了游戏场景下的长时程推理和开放空间交互能力。
使用入口:开源;前往 Github(github.com/bytedance/UI-TARS)获取;技术报告(arxiv.org/abs/2501.12326)。前往 UI-TARS 官网(seed-tars.com)体验。
权威信源:https://github.com/bytedance/UI-TARS | 官方介绍

> “这个模型的原理类似Claude的Computer-Use,通过鼠标和键盘指令来操作电脑 🖥”
腾讯
微信上线「元宝」AI 助手,提供智能问答服务
腾讯推出首个深度整合进微信生态的 AI 助手「元宝」,用户可直接在微信中搜索并添加为好友进行互动。
元宝基于腾讯混元大模型和 DeepSeek 双模引擎,能够一键解析公众号文章、图片及 100M 以内的文档,支持文字与语音输入,并提供内容总结、智能问答、图片识别等功能。
权威信源:媒体报道

> “这么多天过去了,大家还有在用吗?👀”
4 月 18 日
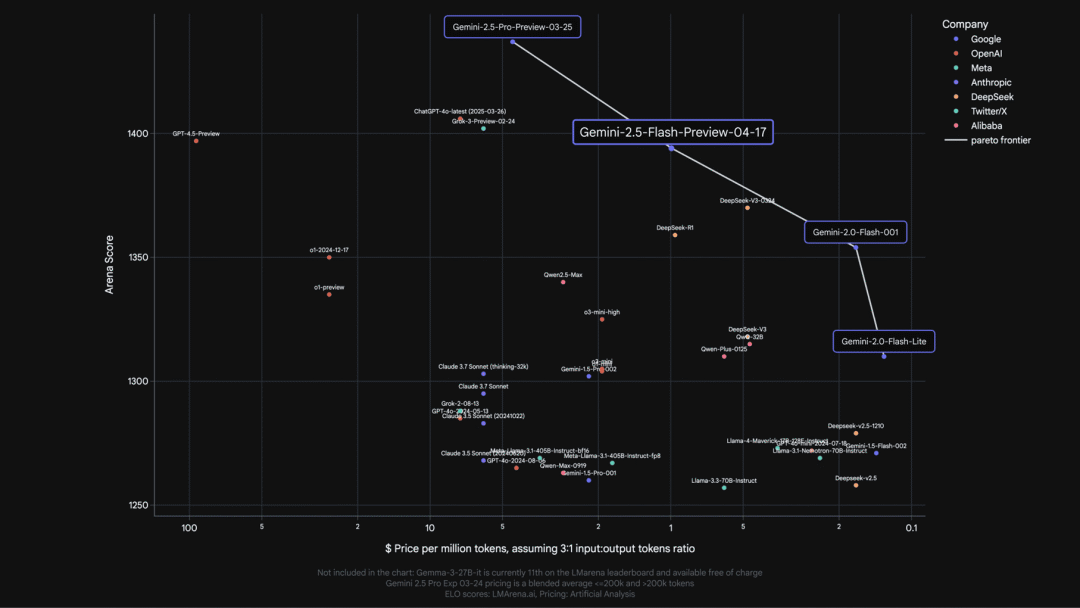
Gemini 2.5 Flash 全混合推理模型发布
Gemini 2.5 Flash 是 Google 首款全混合推理模型,在保持 Gemini 2.0 Flash 高速响应优势的同时,引入了「思考预算」控制机制。开发者可通过该机制灵活调整模型推理深度:既能快速处理简单任务,又能为复杂任务分配更长的思考时间,同时也支持完全关闭思考功能。
Gemini 2.5 Flash 通过混合推理架构,重新平衡了效率与质量的关系。该模型特别适用于需要灵活权衡响应速度、使用成本和推理性能的各种应用场景。
使用入口:前往 Google Gemini(gemini.google.com)体验;前往 Google AI Studio(aistudio.google.com/prompts/new_chat)和 Vertex AI Studio 调用 API。
权威信源:https://developers.googleblog.com/en/start-building-with-gemini-25-flash
> “新的性价比之王 🥳”
Gemma 3 量化感知训练(QAT)新版本系列,本地 GPU 运行
继上月发布最新开源模型 Gemma 3(可用单块 NVIDIA H100 等高端 GPU 运行)后,Google 为进一步提升其易用性,推出了经过量化感知训练(QAT)优化后的新版本系列,大幅降低了内存需求。现在,Gemma 3 的 27B 、12B 、4B 及 1B 版本均可在本地消费级 GPU 上运行。
使用入口:开源;已经与 Ollama、LM Studio、MLX、Gemma.cpp、llama.cpp 集成;前往 HugingFace(huggingface.co/collections/google/gemma-3-qat-67ee61ccacbf2be4195c265b)或 Kaggle(kaggle.com/models/google/gemma-3/transformers)下载模型。
权威信源:https://developers.googleblog.com/en/gemma-3-quantized-aware-trained-state-of-the-art-ai-to-consumer-gpus

腾讯
InstantCharacter 定制化图像生成插件,角色一致性能力优秀(开源)
腾讯推出开源图像生成插件 InstantCharacter ,专为内容创作者设计。用户仅需一张参考图和一句描述,即可让指定角色以任意姿态出现在任何场景中,确保角色在不同场景中的高度一致性,显著提升连环画、影片等视觉内容的创作效率。
该插件角色一致性远超行业水平,图像生成精度高、灵活场景动作调整能力也非常优秀,还兼容开源模型 Flux 并能处理多种复杂风格,实测效果媲美 GPT-4o 等顶尖模型。
使用入口:开源;前往 HugingFace 获取模型(huggingface.co/spaces/InstantX/InstantCharacter);前往 Github 获取代码(github.com/Tencent/InstantCharacter);技术报告(arxiv.org/abs/2504.12395)。
权威信源:https://instantcharacter.github.io | 官方介绍

> “角色一致性是多模态模型生图(例如4o)的一大短板 🙅♂️”
Stanford(Lvmin Zhang)
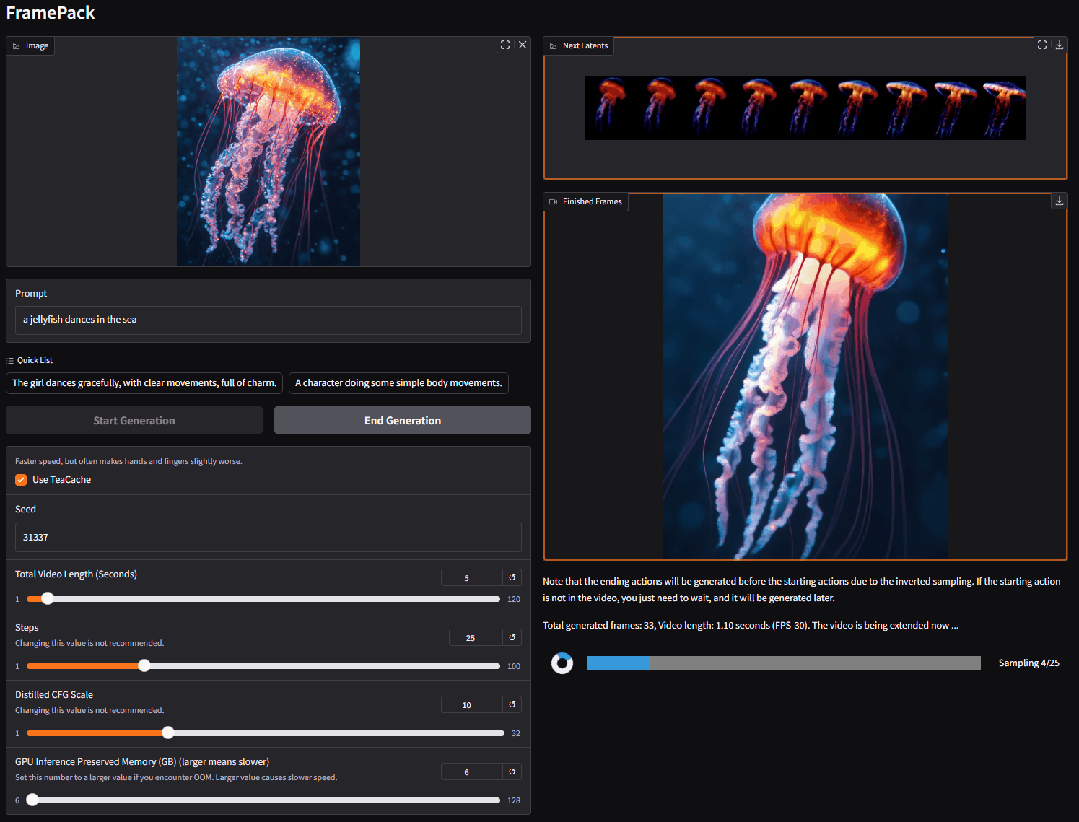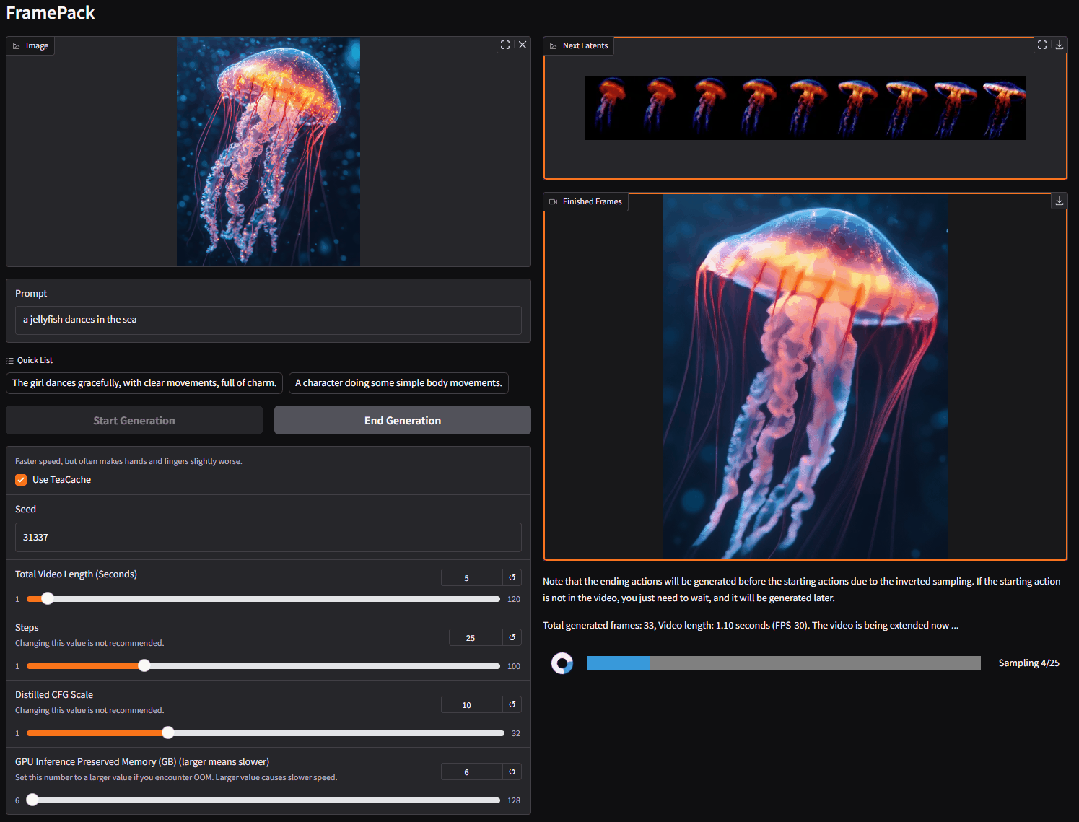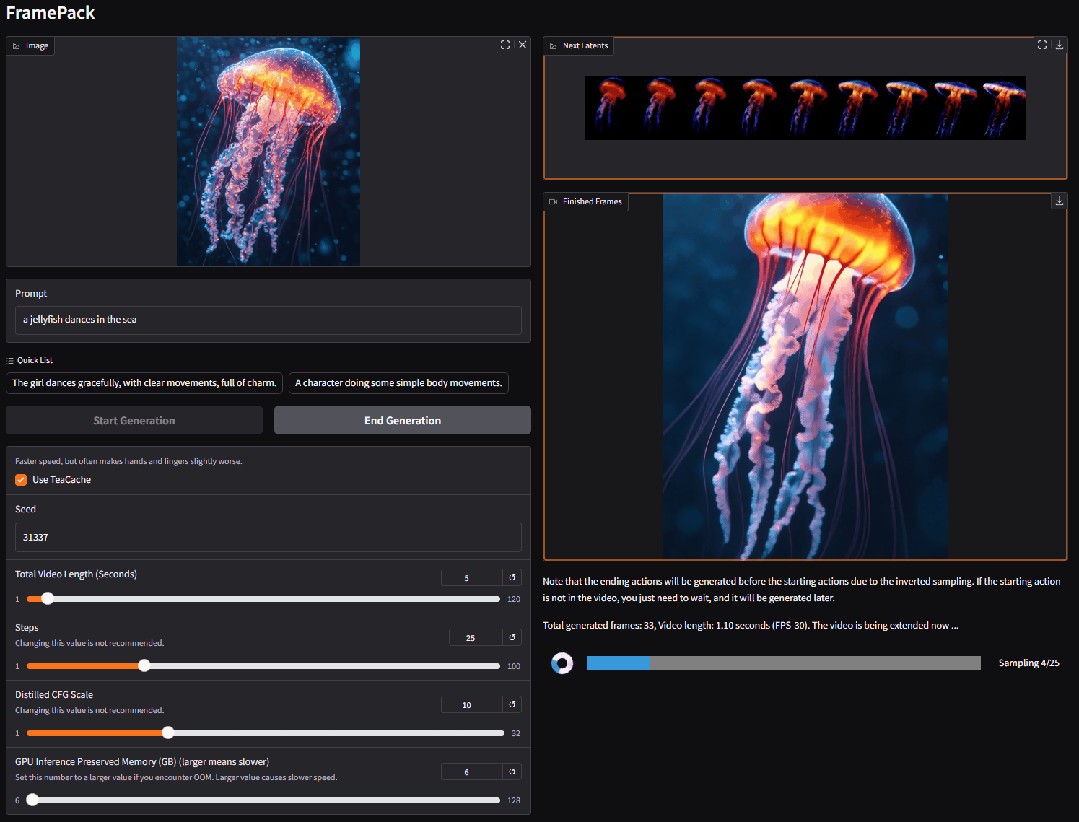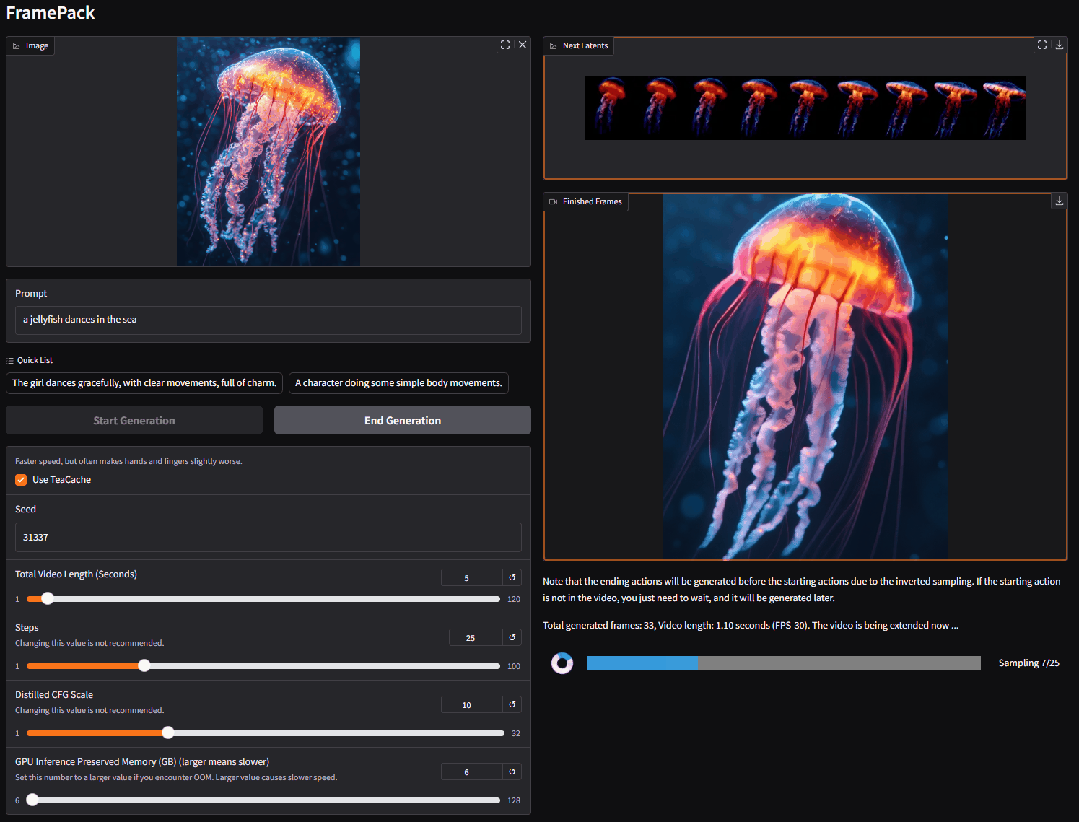
FramePack 逐帧视频生成框架(开源)
由 ControlNet 作者 Lvmin Zhang 开发的突破性视频生成技术 FramePack 正式开源。该框架结合了图像扩散的高效性与视频生成的连续性,突破了传统视频模型对高显存的依赖,使笔记本 GPU 也能流畅生成长视频。
FramePack 模型参数 13B ,仅需 6GB 显存即可驱动生成数千帧视频,并支持高批量训练。在消费级显卡(如 RTX 4090)上优化后,速度可达每秒 1.5 帧,大幅降低长视频生成门槛。
使用入口:开源;前往 Github 下载并安装 GUI(github.com/lllyasviel/FramePack);技术报告(arxiv.org/abs/2504.12626)。
权威信源:https://lllyasviel.github.io/frame_pack_gitpage
> “FramePack的核心思想应该很快会被各大模型公司借鉴 🧐”
Krea AI
上线 3D 创作功能 && 完成 4700 万美元 B 轮融资
4月1日
Krea AI 平台迎来全面升级,重点推出了全新的 3D 生成工具。用户只需上传图片或输入文字描述,点击「生成」按钮,即可在几秒内获得专业级 3D 模型,大幅提升创作效率。

4月18日
全新上线的 Krea Stage 功能支持通过图像或文字生成完整的 3D 环境,并能输出风格一致的场景快照。生成的 3D 场景可一键导出至 Blender,进一步优化了从创作到后期处理的整体工作流程
4月8日
公司宣布完成 4700 万美元的 B 轮融资,投后估值达 5 亿美元。本轮融资由 Bain Capital Ventures 领投,Andreessen Horowitz 和 Abstract Ventures 跟投。此前,公司已先后完成 300 万美元的种子轮融资和 3300 万美元的 A 轮融资。
使用入口:前往 Krea AI 官网(krea.ai)体验。
权威信源:https://www.krea.ai/blog/new-krea

> “Krea在UX上做得一直非常出色 👏”
xAI
Grok 本月发布 Grok Studio、个性化响应、workspace 等多项更新
4月16日,推出智能协作平台 Grok Studio ,支持生成文档、代码、报告、浏览器游戏并提供实时预览,可以集成 Google Drive 直接处理云端文件。开发者可以运行 Python、C++、JavaScript 等代码并即时查看效果。
4月17日,Grok 上线对话记忆及个性化回复功能(测试阶段),记忆内容支持随时查看或删除。
4月18日,Workspaces 通过将对话内容和相关文件集中保存在特定工作区,有效解决了传统聊天模式中上下文容易丢失的问题。Grok 能够持续跟踪长期项目的进展,即使跨越多轮会话也能完整保留历史记录。
权威信源:前往 Grok 官网(grok.com)或者 iOS/Android 下载 App 进行体验
> “OpenAI和Claude有的功能,Grok都会立即跟上 👀”
智谱
完成北京市人工智能产业投资基金追加投资,Z 基金出资 3 亿支持全球开源社区
4月16日,北京市人工智能产业投资基金宣布在去年已有投资基础上,继续追加投资智谱(Z.ai)2 亿元人民币,支持智谱的开源模型研发与开源社区生态建设。
4月18日,为了进一步以实际行动推动开源生态建设,Z 基金出资 3 亿元支持全球范围内的 AI 开源社区发展,任何基于开源模型(不局限于智谱开源模型)的创业项目均可申请。
权威信源:官方介绍
4 月 19 日
人形机器人半程马拉松
天工机器人夺冠
2025 北京亦庄半程马拉松暨人形机器人半程马拉松,作为全球首个人形机器人与人类同场竞技的半程马拉松赛事,吸引了 12,000 名人类选手和 20 余家人形机器人企业代表队参与。
在全长 21.0975 公里、含坡道(最大坡度 9°)与多次转向的复杂赛道上,共有 6 支机器人队伍成功完赛。天工机器人「天工 Ultra 」以 2 小时 40 分 42 秒夺冠,松延动力机器人 N2 与上海卓益得机器人行者二号分获亚季军。
权威信源:媒体报道

> “第一次让大众看到了现阶段人形机器人的真实发展情况 🤦♂️”
字节跳动
Coze Space(扣子空间)AI Agent 应用内测
扣子空间(Coze Space)是一款 AI Agent 协同办公应用,目前进入内测阶段。该应用能自动分析用户需求、拆解任务、调用浏览器、代码编辑器等工具执行,并最终生成完整结果报告(如网页、PPT 、飞书文档)。
平台提供探索模式(单Agent模式)和规划模式(多Agent模式)两种任务模式,支持 MCP 集成并涵盖了飞书多维表格、高德地图等应用,即将支持从「扣子开发平台」发布 MCP 至「扣子空间」。
使用入口:前往扣子官网(coze.cn/space-preview)体验。
权威信源:官方介绍
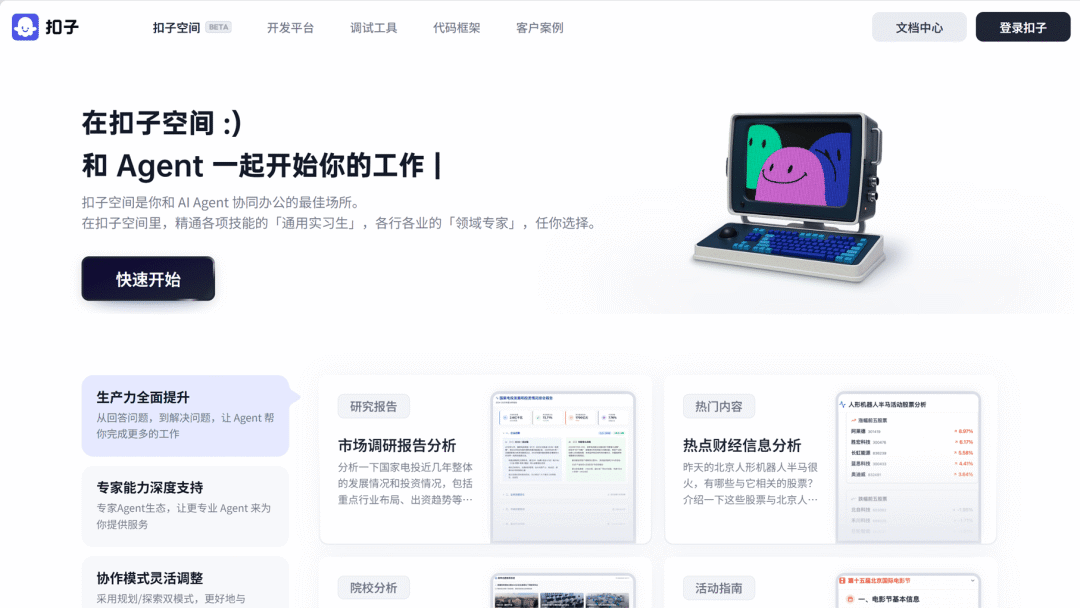
> “意料之中,字节也出了类Manus产品 🤙”
4 月 21 日
Nari Labs
Dia-1.6B TTS 模型,支持情感控制与非语言内容生成(开源)
Dia 是一款文本转语音(TTS)模型,能将文本转换为高度逼真的对话语音,支持通过音频条件控制输出的情感和语调,并可以生成笑声、咳嗽等非语言交流内容(目前仅支持英语)。
模型团队两名本科学生想打造一款媲美甚至超越 NotebookLM Podcast 的模型,历经多重难关,三个月后 Dia 终于诞生了!他们计划将 Dia 制作为一款面向 C 端的应用程序。(加入 Waiting List 申请早期访问权限:https://tally.so/r/meokbo )
使用入口:开源;前往 HugingFace 获取模型(huggingface.co/nari-labs/Dia-1.6B);前往 Github 获取代码(github.com/nari-labs/dia)。前往 Demo 页面(huggingface.co/spaces/nari-labs/Dia-1.6B)试玩。
权威信源:https://x.com/_doyeob_/status/1914464970764628033

生树科技
Vidu Q1 视频生成模型上线,支持 1080p 极清画质与电影级运镜
Vidu Q1 是一款高性能视频生成模型,将视频生成的质量和可控性提升至专业影视级别。模型支持 1080p 极清画质和 HDR 色彩空间,能智能生成符合电影语法的运镜,使画面表现稳定流畅。
此外,该模型还支持 3D 声场定位(如杜比全景声)和 MIDI 设备实时输入,实现音画同步创作,提供媲美专业影视工作室的体验。
使用入口:前往 Vidu 官网(vidu.com)体验;或者调用 API(platform.vidu.com)。
权威信源:https://x.com/ViduAI_official/status/1914303116209697051

昆仑万维
SkyReels-V2 无限时长电影生成模型(开源)
SkyReels-V2 是全球首个基于扩散强迫(Diffusion-forcing)框架的无限时长电影生成模型,能够生成高运动质量、高一致性且高保真的视频内容,目前可支持 30 秒至 40 秒时长的视频生成。
模型还提供了故事生成、图生视频、运镜专家以及多主体一致性视频生成(SkyReels-A2)等多种实用场景,为电影级长视频创作提供了创新技术方案。
使用入口:开源;前往 Github 获取模型(github.com/SkyworkAI/SkyReels-V2);技术报告(arxiv.org/abs/2504.13074)。前往 SkyReels 官网(skyreels.ai)体验。
权威信源:官方介绍

> “视频模型开始往生成时长的方向努力了 ⏱”
Sand.ai
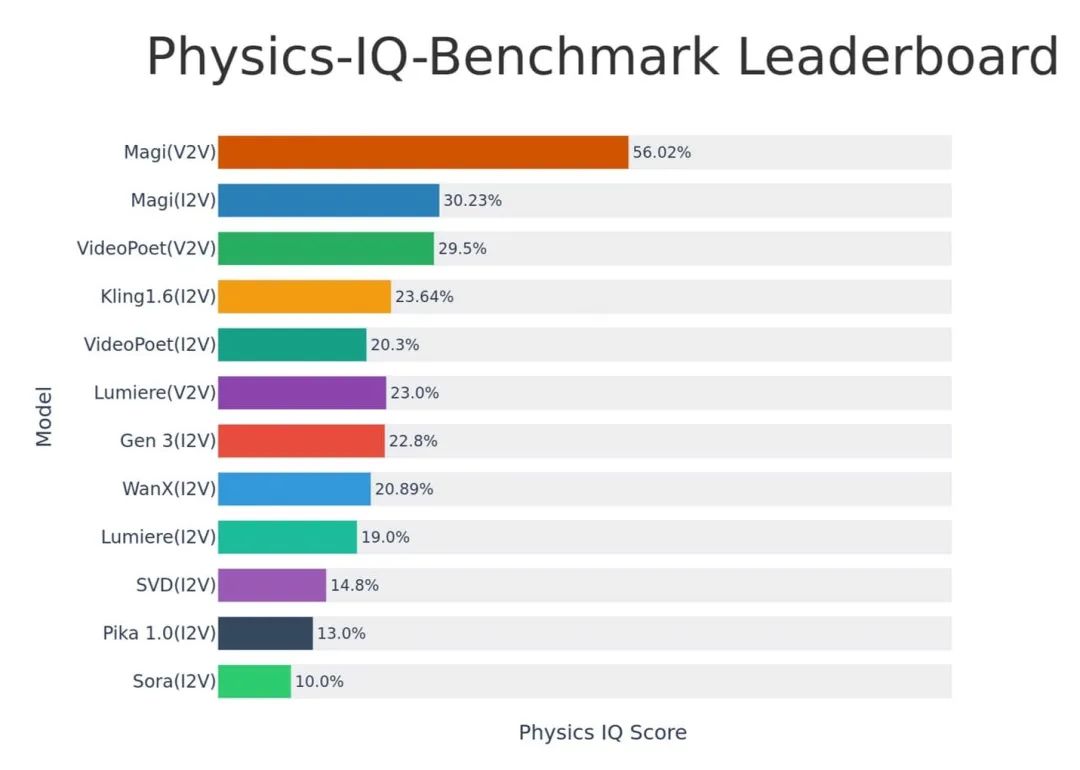
MAGI-1 图生视频模型系列,支持无限延伸与秒级精度时间控制(开源)
Magi-1 是一款基于自回归预测的视频生成模型,通过预测固定长度的连续帧序列来合成高质量视频。在图生视频(I2V)任务中,该模型凭借 无限延伸 和 秒级精度的时间控制 的出色能力超越了多数同类模型,还支持通过分段提示实现场景过渡和精细化控制。
Magi-1 提供了两个开源版本:24B 参数模型可生成原生 1440×2568 分辨率的高清视频,4.5B 参数版本仅需单张 RTX 4090 显卡即可完成推理。
使用入口:开源;前往 HugingFace(huggingface.co/sand-ai/MAGI-1)或者 Github(github.com/SandAI-org/MAGI-1)获取模型和代码;技术报告(static.magi.world/static/files/MAGI_1.pdf)。前往 Sand AI 官网(sand.ai/magi)试玩。
权威信源:赛博禅心
秘塔
推出「今天学点啥」模式,LLM 驱动个性化学习内容生成
秘塔推出「今天学点啥」模式,旨在根据用户的知识水平和偏好,将复杂内容转化为适合用户需求的讲解内容,实现个性化、定制化的学习体验。
今天学点啥模式,能够根据用户的知识水平和偏好,将复杂内容转化为适合用户需求的讲解内容,实现个性化、定制化的学习体验。
用户只需上传文档、输入网址或关键词,系统便会自动生成匹配的 PPT 、音频讲解及课程资料。目前支持课堂讲解、小说风格、故事叙述等多样化讲解风格与互动形式,并能模拟特定人物(如「莎士比亚」或「李白」)的口吻进行讲解。
使用入口:前往秘塔官网(metaso.cn/study)体验。
权威信源:官方介绍
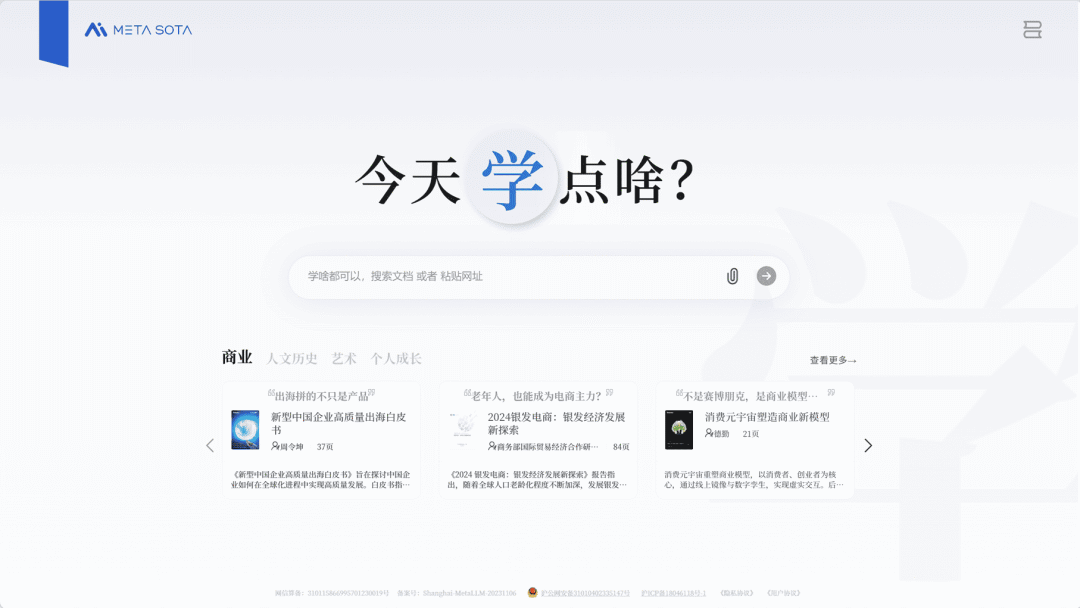
> “很好的应用形式 👏 但是生成内容的质量还是需要提升 💪”
4 月 22 日
Fellou.ai(谢扬)
Fellou 是全球首款 Agentic Browser (内测)
Fellou 是全球首款 Agentic Browser(行动型浏览器),目前处于内测阶段。用户通过自然语言提出目标,Fellou 即可自动解析指令、拆解任务、跨网页和系统调度操作,完成端到端任务交付。它还具备主动感知能力,会主动询问是否需要介入或接管任务。
Fellou 采用虚拟化技术隔离任务执行环境(影子空间),确保 Agent 执行任务时不干扰用户使用电脑,同时用户还可以看到 Agent 的执行进程并在适当时刻加以干预。此外,用户可将个人任务流程封装为可共享的工作流供他人直接调用,高阶开发者则可以使用 Eko Framework 开发框架快速将自定义工具型。
Fellou 创始人谢扬,此前创办的企业级身份认证平台 Authing 已服务超 700 家企业客户,月均处理千万级认证请求,并获得头部 VC 数千万美元投资。
使用入口:前往 Fellou 官网(fellou.ai)体验;目前支持Mac(Apple 芯片 / Intel芯片)网页及 PC 端下载,Windows 及移动版计划于下半年推出。 团队还计划开源 Agentic Browser Benchmark。
权威信源:官方介绍 | 赛博禅心

> “本地浏览器的方案,可以解决一些用户数据的问题 👌”
教育部
更新《普通高等学校本科专业目录(2025年)》,增列 29 种新专业,包括人工智能教育
教育部同步更新发布《普通高等学校本科专业目录(2025年)》,增列 29 种新专业,纳入 2025 年高考招生。新目录包含 93 个专业类、845 种专业,进一步强化专业设置对国家战略急需和高质量发展的快速响应。
其中,人工智能教育,专业代码 040117TK,属于教育学类,布点高校为北京师范大学。
权威信源:媒体报道

4 月 23 日
Ostris
Flex.2-preview 文生图模型,整合通用控制和图像修复能力(开源)
Ostris 推出 8B 参数的文生图扩散模型 Flex.2(预览阶段)。该模型不仅支持文生图基础功能,还整合了通用控制能力(线条、姿态、深度)以及图像修复(Inpainting)等多项实用特性,并支持通过 AI-Toolkit 进行定制化微调,为用户提供了更灵活的适配方案。
使用入口:开源;前往 HugingFace 获取模型(huggingface.co/ostris/Flex.2-preview);通过 ComfyUI 和 Diffusers 使用。
权威信源:https://x.com/ostrisai/status/1914799647899722198
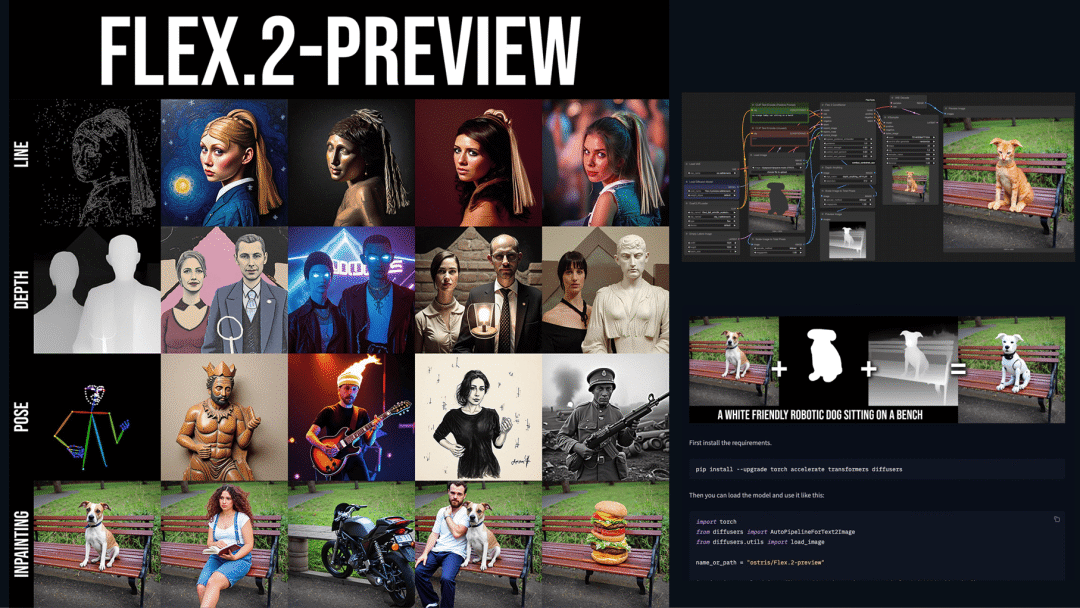
> “可以作为ComfyUI中Flux模型的一个替代方案 🎨”
MiniMax
Hailuo 上线 Character Reference 功能,单图生成多样化电影级角色视频
Character Reference(角色参考)功能可以基于单张参考图像生成多样化角色视频。
该功能可以在保持角色特征高度一致的前提下,为用户生成多角度、多动态姿势、表情丰富的角色视频,并且引入了电影级的光影效果与专业构图,使生成结果视觉效果媲美专业电影画面。
使用入口:前往 Hailuo AI 官网(hailuoai.video/create)体验。
权威信源:https://x.com/Hailuo_AI/status/1914845649704772043

Character.AI
AvatarFX 视频生成模型,静态图片生成动态对话角色
Character.AI 推出角色动画生成模型 AvatarFX ,用户仅需上传一张图片并选择声音,即可将静态角色(包括二维动画、三维卡通、宠物等非人类形象)转化为具有自然说话、动作和表情变化的动态形象。
该模型具备强大的多角色对话功能,支持多轮互动和长视频生成,在保持面部表情与肢体动作高度协调的同时,展现丰富细腻的情感表达。
使用入口:团队未来几个月将把 AvatarFX 模型引入 Character.AI 产品,订阅用户将首先体验这一功能;Waiting List(character.ai/video?ref=blog.character.ai)。
权威信源:https://blog.character.ai/avatar-fx-cutting-edge-video-generation-by-character-ai | https://character-ai.github.io/avatar-fx

> “其实就是对嘴型,类似Hedra 👄”
腾讯
混元 3D 生成模型升至 2.5 版本,支持 4K 高清纹理
腾讯混元 3D 生成模型升级至 2.5 版本,在建模精细度上取得了突破。新版本支持 4K 高清纹理和细粒度 bump 贴图,还优化了模型表面平整度、边缘锐度和细节表现,使整体画质达到高清标准。
在模型架构方面,混元 3D v2.5 参数量从 1B 提升至 10B ,有效面片数增长超过 10 倍,大幅提升了模型的生成能力和细节处理水平。
使用入口:前往腾讯混元3D官网(3d.hunyuan.tencent.com)体验,免费生成额度翻倍;或者调用 API(cloud.tencent.com/document/product/1729/117860)。
权威信源:官方介绍

> “腾讯在3D开源模型这片蓝海中,算是有了自己的一席之地 🏆”
4 月 24 日
昆仑万维
Skywork-R1V 2.0 多模态推理模型(开源)
Skywork-R1V 2.0 号称在目前开源多模态模型中,视觉与文本推理能力最均衡。根据多个权威基准测试结果,R1V 2.0 相较前代 R1V 1.0 实现了全面升级,在文本理解和视觉推理两大核心任务上均有显著提升。
该模型在高考理科(数学/物理/化学)难题的深度推理及通用任务场景中均展现出卓越性能。
使用入口:开源;前往 HugingFace(hf.co/Skywork/Skywork-R1V2-38B)或 Github(github.com/SkyworkAI/Skywork-R1V)获取模型;技术报告(arxiv.org/abs/2504.16656)。
权威信源:官方介绍
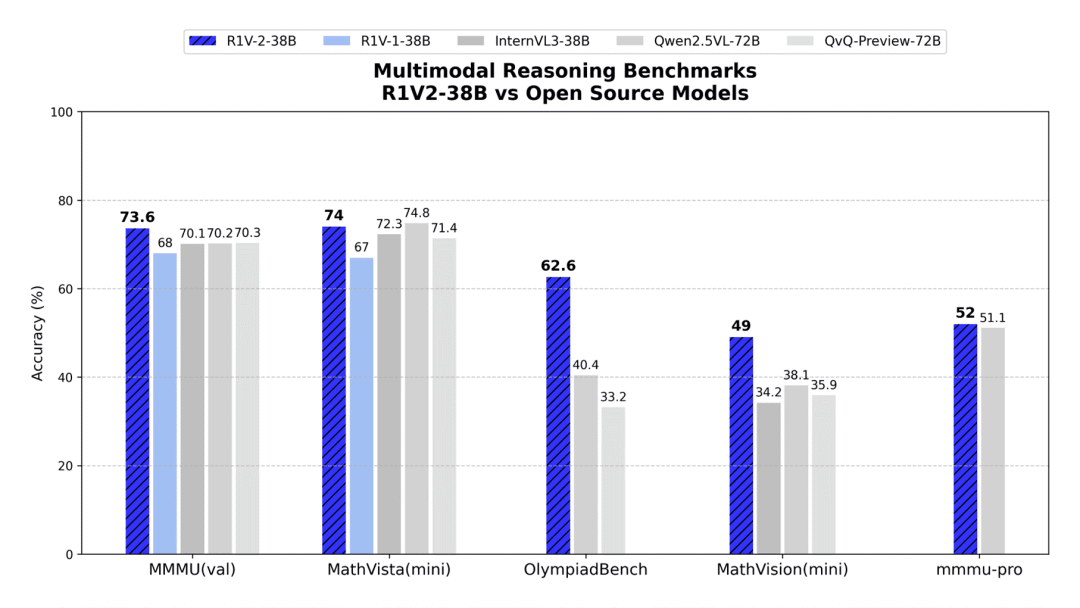
> “适合本地化部署的多模态推理模型 ✔”
OpenAI
gpt-image-1 多模态模型 API 开放
继上月 OpenAI ChatGPT 图像生成功能广受欢迎(首周用户生成图像超 7 亿张)后,OpenAI 现正式开放 gpt-image-1 多模态模型的 API 接口。
gpt-image-1 模型创作能力强大,不仅能精准理解用户指令,还支持多样化的图片视觉风格。模型本身具备丰富的世界知识储备、出色的文字渲染一致性以及专业的图像编辑能力,可以为用户提供高效的创意解决方案。
使用入口:前往官网 Playground(platform.openai.com/playground/images)体验;或者调用 API。
权威信源:https://openai.com/index/image-generation-api

> “此模型上线后,抢了不少传统图像模型的市场 👀”
腾讯 CodeBuddy
推出 Craft 软件开发 Agent,自动生成完整的项目代码
腾讯旗下代码助手 CodeBuddy 推出软件开发 Agent —— Craft。开发者只需用自然语言输入需求,Craft 便能自动生成完整的项目代码。
此外,Craft 支持主流 IDE,兼容腾讯生态系统,还支持 MCP 协议,实现代码的无缝接入测试、构建和部署,并且。
使用入口:前往 CNB(cnb.cool)中免费使用;前往 CloudStudio(cloudstudio.net)免费使用;打开 VSCode 或 JetBrains、VS、微信小程序 IDE 等主流 IDE,插件市场搜索「腾讯云代码助手CodeBuddy」免费使用。
权威信源:https://copilot.tencent.com | 官方介绍
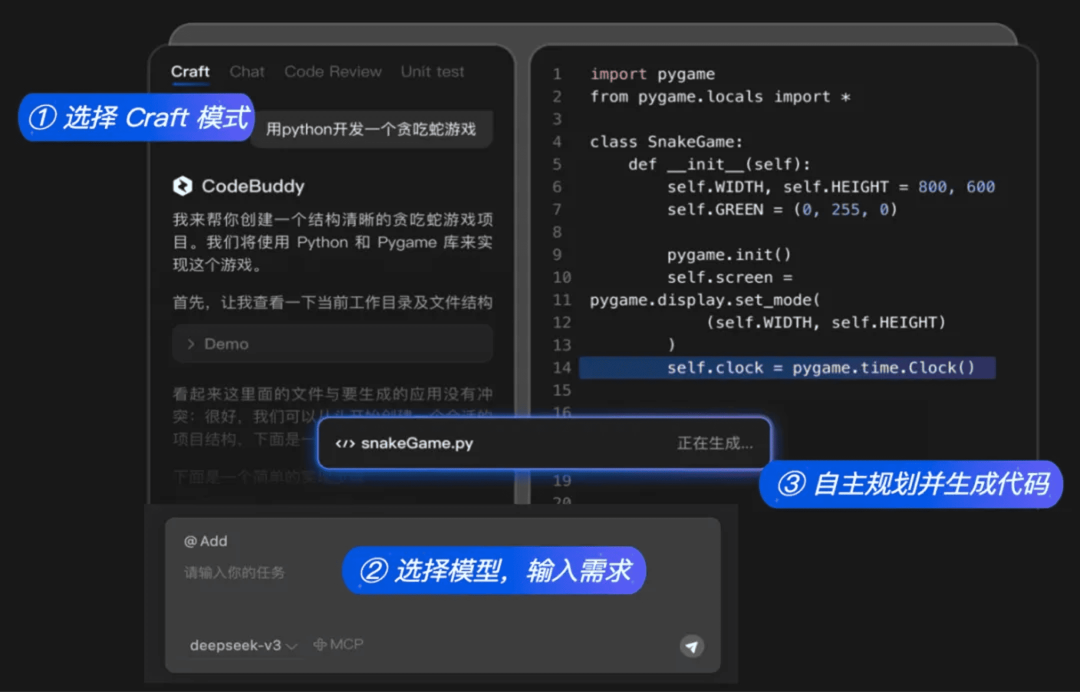
> “腾讯也浅尝了一下AI编程领域 👀”
蝴蝶效应(Manus)
完成 7500 万美元融资,估值达到 5 亿美元
Manus 所属中国初创公司蝴蝶效应(Butterfly Effect)宣布完成 7500 万美元战略融资,估值攀升至近 5 亿美元。本轮融资由硅谷顶级风投 Benchmark 领投,红杉中国、腾讯等现有投资方跟投。融资将主要用于加速 Manus 全球市场拓展(重点布局美国、日本及中东地区),并升级 AI Agent 系统算力基础设施。
权威信源:https://www.theinformation.com/briefings/benchmark-invests-chinese-startup-behind-manus-ai-agent

> “有了资本的助力,希望Manus可以尽快开放注册。”
4 月 25 日
Tavus
Hummingbird-0 零样本唇形同步模型发布
Hummingbird-0 是零样本唇形同步领域最先进的模型,在视频逼真度、身份保持、唇部同步精度三大核心指标上均处于领先行业,同时运算成本更低。
仅需用户提供几秒钟原始视频素材,Hummingbird-0 就能在一分钟内生成高质量的 10 秒唇部同步视频,全程无需额外训练。模型支持处理最长 5 分钟视频,兼容多种主流视频格式和分辨率,但不适用于动画、歌唱视频、实时处理或多说话者场景。
使用入口:前往 Demo 页面(fal.ai/models/fal-ai/tavus/hummingbird-lipsync/v0)体验;前往 Tavus(docs.tavus.io/sections/lipsync/overview)和 FAL(fal.ai/models/fal-ai/tavus/hummingbird-lipsync/v0)调用 API。
权威信源:https://www.tavus.io/post/introducing-hummingbird-0-a-leap-in-lip-sync
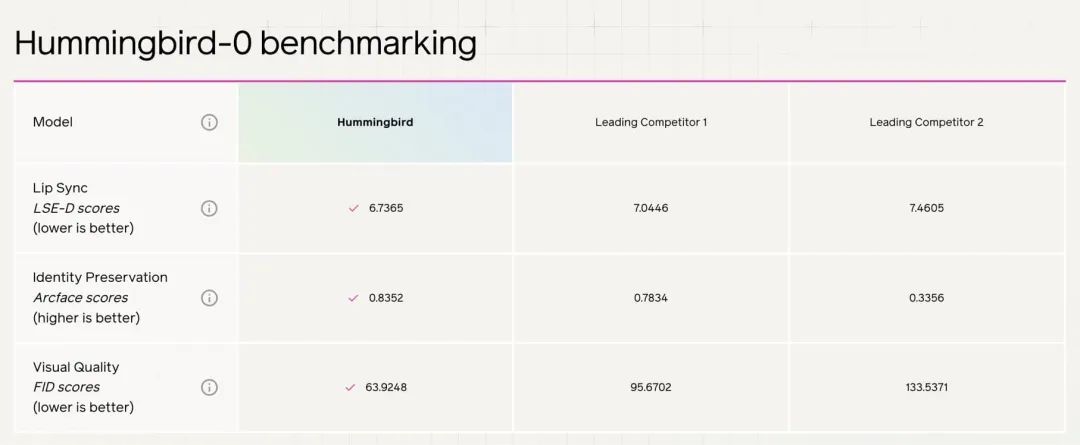
> “类似Sync的「视频->视频」对口型 👄”
百度Create2025 大会
发布文心大模型 Turbo 版,心响 App,沧舟 OS,文心杯创业大赛等
Create2025 百度 AI 开发者大会发布了文心大模型 X1 Turbo 和 4.5 Turbo版本,能力更强、速度更快,成本更低。
此外,百度还发布了高说服力数字人、通用超级智能体 心响 App、内容操作系统 沧舟OS 等多款 AI 应用,并宣布将帮助开发者积极全面拥抱 MCP。大会正式启动第三届「文心杯」创业大赛。
使用入口:文心大模型 4.5 公告(yiyan.baidu.com/notice/feature);百度数字人(huibo.baidu.com);心响 Agent(xinxiang.baidu.com);百度 MCP 生态平台(sai.baidu.com/mcp)
权威信源:https://create.baidu.com | 官方介绍

中共中央政治局第二十次集体学习
坚持自立自强,突出应用导向,推动人工智能健康有序发展
中共中央政治局 4 月 25 日下午就加强人工智能发展和监管进行第二十次集体学习。中共中央总书记习近平在主持学习时强调,面对新一代人工智能技术快速演进的新形势,要充分发挥新型举国体制优势,坚持自立自强,突出应用导向,推动我国人工智能朝着有益、安全、公平方向健康有序发展。
西安交通大学教授郑南宁同志就这个问题进行讲解,提出工作建议。中央政治局的同志认真听取讲解,并进行了讨论。
权威信源:https://www.gov.cn/yaowen/liebiao/202504/content_7021072.htm | 媒体报道 | 给政治局讲人工智能的西安交大郑南宁报告全文
> “官方声音:应用导向 ❗❗❗”
2050
2050@2025 年青人因科技而团聚
2050是一个以「年青人因科技而团聚」为愿景,由全球自愿者共同发起的有关科技和未来的见面活动。从 2018 年开始,每年四月的最后一个完整周末,从周五开始到周日,我们会在杭州的云栖小镇团聚 2.5 天直到 2050 年。
2025年4月25日至4月27日,2050@2025 如约而至。
权威信源:https://2050.org | 官方介绍

>“年青人是不一样的,他们来自世界不同的地方,说着不同的语言,热爱不同的科学和技术,怀揣不同的梦想。年青人是一样的,他们都是没有伞的孩子,他们喜欢在雨中奔跑。”——杭州市云栖科技创新基金会发起人,阿里云创始人 王坚
4 月 26 日
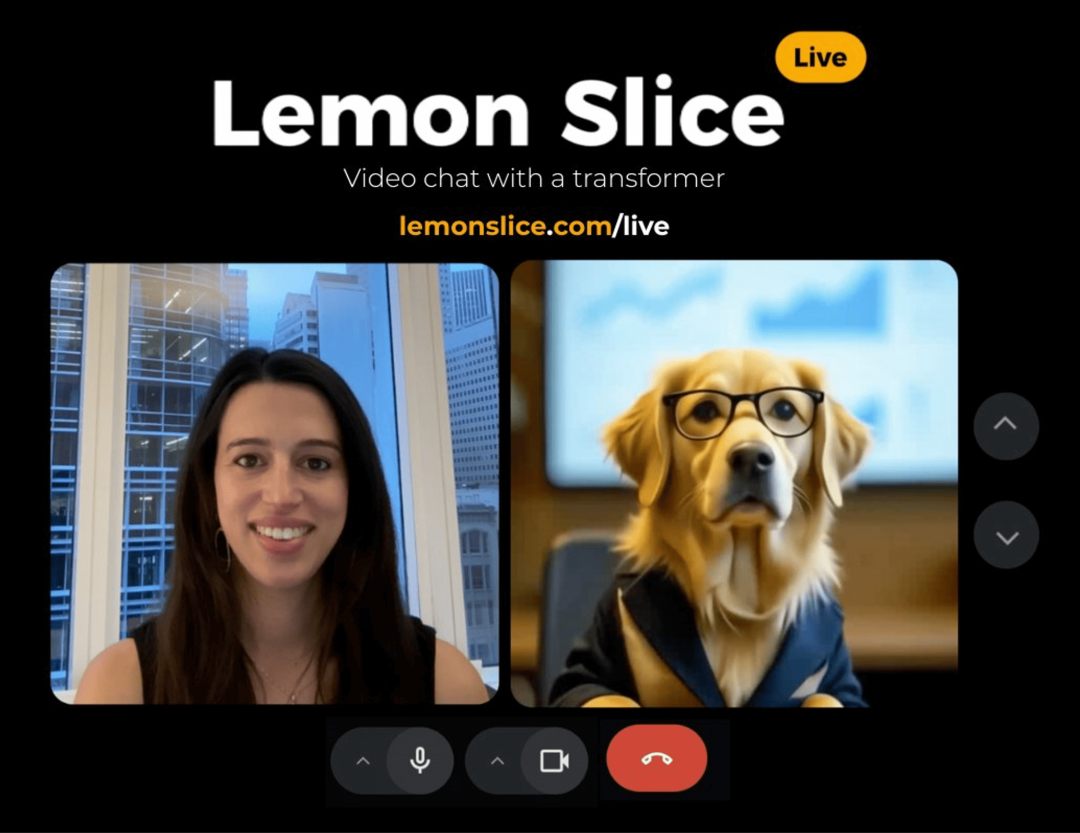
Lemon Slice X Deepgram
Lemon Slice Live 零样本实时数字人聊天模型
Lemon Slice 公司与 Deepgram 合作研发了一款零样本实时视频交互模型 Lemon Slice Live ,能够将任意图像(照片、插画或绘画)转化为可对话的数字人,全程跳过传统角色训练和动作绑定。
通过 Lemon Slice Live 在线应用,该技术能以 25fps 流畅帧率运行,提供自然的实时对话体验,支持 10 种语言交互,并实现精准唇形同步、生动表情动画和动态语音回应。
使用入口:前往 Lemon Slice Live 官网(lemonslice.com/live)体验;技术报告(lemonslice.com/live/technical-report)。团队表示正在开创「互动媒体」的新范式,未来将彻底改变内容消费形态,让电视剧、电影、广告甚至在线课程都能与观众实时对话。
权威信源:https://lemonslice.com/live/technical-report
> “优势在于生成速度 ⚡”
月之暗面
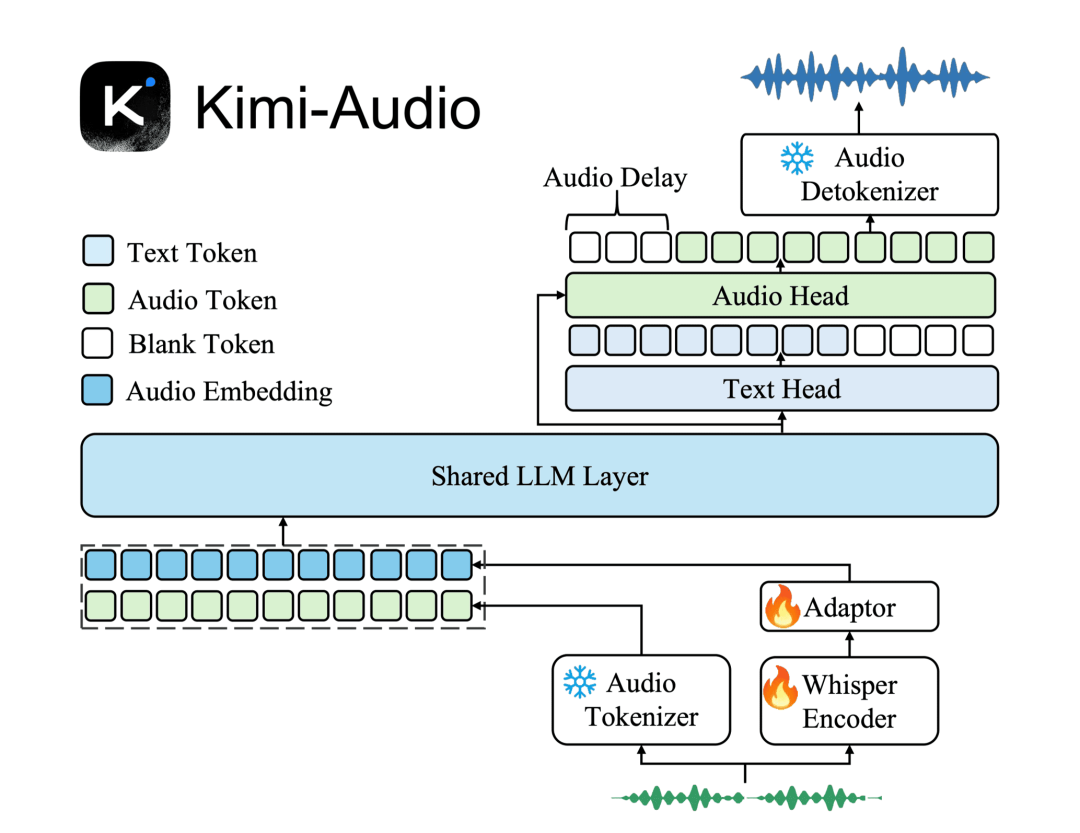
Kimi-Audio 通用音频基础模型,单一框架处理多样化音频任务(开源)
Kimi-Audio 是一个通用音频基础模型,能够在单一统一框架内处理各种音频处理任务,如自动语音识别(ASR)、音频问答(AQA)、音频字幕生成(AAC)、语音情感识别(SER)、声音事件/场景分类(SEC/ASC)以及端到端的语音对话。
该模型训练数据覆盖 1,300 万小时的语音、音乐和环境音数据及文本数据,在 LibriSpeech 、MMAU / VocalSound 及 VoiceBench 等基准测试中均取得当前最优性能。
使用入口:开源了模型/代码/评估工具包;前往 HugingFace 获取模型(huggingface.co/moonshotai/Kimi-Audio-7B-Instruct);前往 Github 获取代码(github.com/MoonshotAI/Kimi-Audio);技术报告(github.com/MoonshotAI/Kimi-Audio/blob/master/assets/kimia_report.pdf)。
权威信源:https://x.com/Kimi_Moonshot/status/1915807071960007115
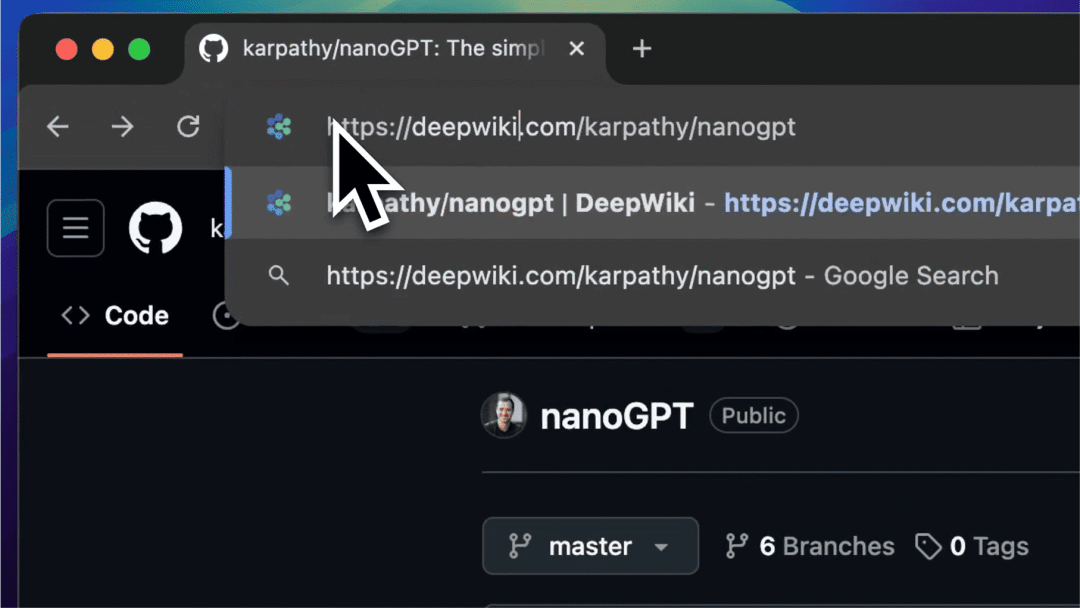
Cognition Labs(Devin)
DeepWiki 工具免费开放,GitHub 仓库一键转 Wiki 式文档
DeepWiki 是一款基于大模型的 GitHub 仓库分析工具,能够为每个开源项目生成层次化结构的 Wiki 页面,帮助开发者快速理解复杂项目的设计逻辑,并支持对话式交互探索。
DeepWiki 已索引超 3 万个 GitHub 仓库,处理了 40 亿行代码和 1000 亿 token ,计算成本超 30 万美元,现已完全免费开放,用户无需注册即可使用。
使用入口:前往 DeepWiki 官网(deepwiki.com)浏览热门开源项目 Wiki;或将任何 GitHub URL 中 github 替换为 deepwiki 。
权威信源:https://x.com/silasalberti/status/1915821553465626791
> “用AI将互联网上的信息进行结构化,再分享出来,是个不错的尝试 🥳”
4 月 27 日
阶跃星辰
Step1X-Edit 图像编辑大模型(开源)
Step1X-Edit 图像编辑大模型具备精准语义理解、身份一致性保持和高精度区域控制三项关键能力。在最新发布的图像编辑基准 GEdit-Bench 中,其性能媲美 GPT-4o 和 Gemini 2.0 Flash。
模型支持文字替换、风格迁移、材质变换、人物修图、色彩调整、背景更改和主体替换等 11 类图像编辑细分任务,功能全面均衡。
使用入口:开源;前往 HugingFace 获取模型(huggingface.co/spaces/stepfun-ai/Step1X-Edit);前往 Github 获取代码(github.com/stepfun-ai/Step1X-Edit);技术报告(arxiv.org/pdf/2504.17761)。前往阶跃官网(stepfun.com)和阶跃AI App 体验。
权威信源:官方介绍

> “实测效果不错,还支持本地化部署,好评 👏”
4 月 29 日
阿里巴巴
Qwen3 多模态模型系列,MoE 与 Dense 架构覆盖多参数规模(开源)
Qwen 系列大语言模型迎来最新成员 Qwen3。模型支持「思考模式」和「非思考模式」两种模式,让模型具备稳定且高效的「思考预算」控制能力,使用户能够根据具体任务控制模型进行思考的程度。
本次开源包括 2 个 MoE(混合专家)模型和 6 个 Dense(稠密)模型,覆盖从 0.6B 到 235B 不等的参数规模。
MoE模型
- Qwen3-30B-A3B
- Qwen3-235B-A22B
稠密模型
- Qwen3-32B
- Qwen3-14B
- Qwen3-8B
- Qwen3-4B
- Qwen3-1.7B
- Qwen3-0.6B
使用入口:开源;前往 HugingFace(huggingface.co/Qwen/Qwen3-235B-A22B)或 Github(github.com/QwenLM/Qwen3)获取模型;前往 Qwen Chat 网页版(chat.qwen.ai)或者通义 App 体验;调用 API(aliyun.com/product/tongyi)。
权威信源:https://qwenlm.github.io/blog/qwen3 | 官方介绍
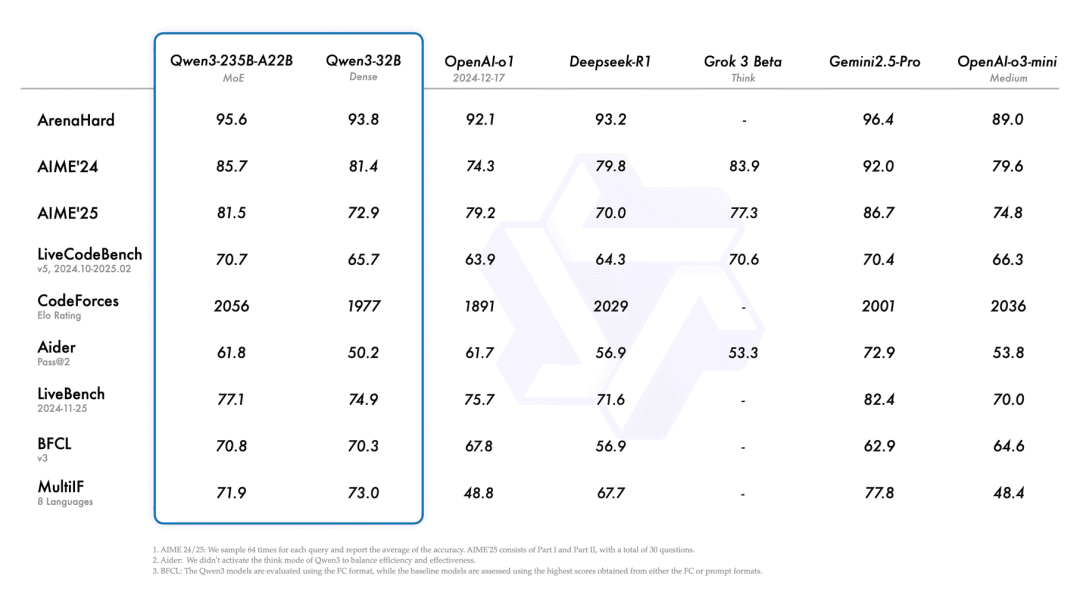
> “Qwen3将推理模型和非推理模型进行了融合,MoE架构在本地运行时又可以获得更高的输出速度。Qwen将开源模型的标准推向了新的高度,不愧是开源之王 🥳”
Higgsfield AI
Iconic Scenes 功能上线,照片一键融入经典电影场景
Iconic Scenes(经典电影场景)生成功能,可以将用户上传的人物照片替换到经典电影场景中。
网站预设了 20 多种经典电影场景模板(如《星际穿越》《黑客帝国》《泰坦尼克号》)及 30 多种风格化模板(如吉卜力动画、复古迪士尼),并支持 80 多种专业镜头运动效果,让普通照片瞬间升级为电影级动态画面。
使用入口:前往 Higgsfield AI 官网(higgsfield.ai/scene)体验;或者调用 API(higgsfield.typeform.com/HiggsfieldAPI)。
权威信源:https://x.com/higgsfield_ai/status/1916885476943802679
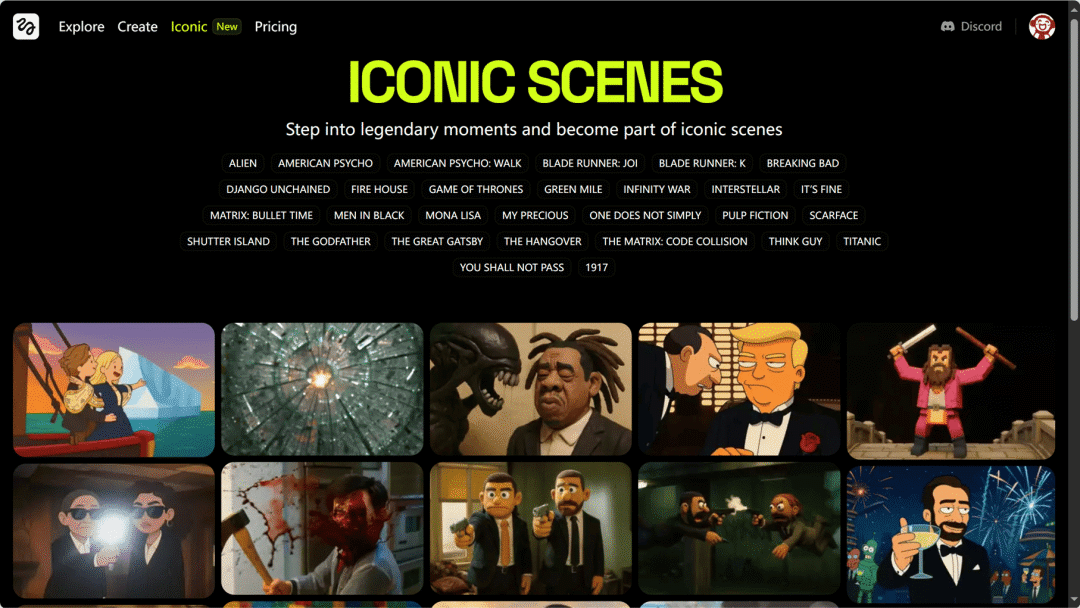
> “模板更新很快,质量也非常高 👍”
OpenAI
ChatGPT 本月发布长期记忆、轻量版 Deep Research 及个性化商品推荐等重要更新
4月11日,推出长期记忆功能(Plus 和 Pro 用户),基于完整聊天历史提供个性化回答。
4月25日,Deep Research 轻量版向 Plus、Team 和 Pro 用户开放,达到原版使用限制后会自动切换至轻量版。免费用户可以获得轻量版的基础支持。
4月29日,ChatGPT 搜索功能升级购物体验,向全球用户(含免费及未登录)提供商品查找、比较与购买服务。平台强调是通过独立筛选机制推荐产品,所有结果均非广告。
权威信源:前往 ChatGPT 官网(chatgpt.com)或移动 App 体验

习近平在上海考察
强调加快建成具有全球影响力的科技创新高地
中共中央总书记、国家主席、中央军委主席习近平 29 日在上海考察时强调,上海承担着建设国际科技创新中心的历史使命,要抢抓机遇,以服务国家战略为牵引,不断增强科技创新策源功能和高端产业引领功能,加快建成具有全球影响力的科技创新高地。
29日上午,习近平在中共中央政治局委员、上海市委书记陈吉宁和市长龚正陪同下,来到位于徐汇区的上海「模速空间」大模型创新生态社区调研。
权威信源:https://www.gov.cn/yaowen/liebiao/202504/content_7021730.htm | 媒体报道

4 月 30 日
Amazon
Nova Premier 多模态基础模型的旗舰版本
Amazon 推出旗舰多模态基础模型 Nova Premier ,上下文长度达到 1M Token ,可处理极长的文档或大型代码库。
该模型亦可作为教师模型,通过 Amazon Bedrock 平台将其先进能力蒸馏至 Nova Pro 、Nova Micro 和 Nova Lite 等更轻量化的衍生模型中。
使用入口:前往 Amazon Nova 官网(nova.amazon.com/chat)体验;开发者可以前往 Amazon Bedrock 调用模型 API。
权威信源:https://aws.amazon.com/cn/blogs/aws/amazon-nova-premier-our-most-capable-model-for-complex-tasks-and-teacher-for-model-distillation | 官方介绍

> “感觉就是GPT-4.1的翻版,但比GPT-4.1卖得还贵 🤐”
DeepSeek
DeepSeek-Prover-V2 数学定理证明模型系列发布(开源)
DeepSeek 推出专为 Lean 4 形式化定理证明设计的高性能模型系列 DeepSeek-Prover-V2。该系列在 MiniF2F 测试中达到 88.9% 的通过率,并成功解决 PutnamBench 中的 49 道难题,展现强大自动推理能力。
模型提供 671B 和 7B 两个版本: 671B 版基于 DeepSeek-V3 训练,具顶尖数学推理能力;7B 版则优化了上下文处理,支持长达 32K Token 上下文。
使用入口:开源;生成的证明部分开放下载;前往 HugingFace 获取模型和数据(huggingface.co/deepseek-ai/DeepSeek-Prover-V2-671B)。
权威信源:https://huggingface.co/deepseek-ai/DeepSeek-Prover-V2-671B

> “这个模型,感觉是为了强化学习的训练准备的 🔍”
小米
Xiaomi MiMo-7B 推理模型系列发布(开源)
小米发布其首个开源推理模型系列 Xiaomi MiMo ,参数量 7B ,由新成立不久的「小米大模型 Core 团队」初步尝试开发。
Mimo-7B 全系列模型均已开源,包括预训练模型 Mimo-7B-Base 、监督微调模型 Mimo-7B-SFT 、以及强化学习模型 Mimo-7B-RL 和 Mimo-7B-RL-Zero 。
使用入口:开源 ;前往 HugingFace 获取模型(https://huggingface.co/XiaomiMiMo)。
权威信源:https://github.com/XiaomiMiMo/MiMo/blob/main/MiMo-7B-Technical-Report.pdf | 官方介绍
> “RL已经成为模型训练的主流了 👀”
JetBrains
Mellum 代码补全聚焦模型系列首发,全新训练支持 14 种编程语言(开源)
JetBrains 推出开发者专用大模型系列 Mellum,首个版本专注于代码补全任务,后续将陆续推出针对不同开发场景的专用模型。
Mellum 并非基于现有模型微调,而是从零开始训练的全新模型,训练数据达 4 Trillion Token 。模型参数量 4B ,上下文长度 8K ,目前支持包括 Java 、Python 、JavaScript 等在内的 14 种主流编程语言的代码补全。本次开源发布包含基础模型 和 Python 指令微调模型。
使用入口:开源;前往 HugingFace 获取模型(huggingface.co/collections/JetBrains/mellum-68120b4ae1423c86a2da007a)。
权威信源:https://blog.jetbrains.com/ai/2025/04/mellum-goes-open-source-a-purpose-built-llm-for-developers-now-on-hugging-face

> “自动补全是否好用,是AI编程工具的一个核心竞争点 🎯”
FASHN AI
FASHN v1.5 虚拟试穿模型发布与重要升级
FASHN v1.5 虚拟试穿模型于3月29日发布,重点优化了宽松服装试穿效果并更精准保留体型、纹身等身体细节,同时简化操作流程,模型可自动管理多项参数(如恢复背景、恢复衣物、长上衣、调整手部、覆盖脚部等)。
4月30日,模型进一步升级,支持最高 100 万像素输出分辨率及更灵活的尺寸控制,API 接口保持不变,旨在提升真实感和易用性。
使用入口:前往 FASHN AI 官网(fashn.ai)使用,或者调用 API(fal.ai/models/fal-ai/fashn/tryon/v1.5)。
权威信源:https://fashn.ai/blog/fashn-resolution-upgrade-larger-outputs-flexible-aspect-ratios-same-speed

沐言智语
Muyan-TTS 零样本语音合成模型,低成本易于二次开发(开源)
Muyan-TTS 是一款低成本、完全开源且易于二次开发的文本转语音(TTS)模型,旨在为学术界和小型应用团队提供灵活的语音合成解决方案。
当前版本主要针对英语优化,包含一个在多样化长音频数据集上预训练的基础模型(支持零样本 TTS 合成)和一个在单一说话人数据上微调的模型(可进一步提升语音质量)。
使用入口:开源了训练代码和微调方法;前往 HugingFace 获取模型(huggingface.co/MYZY-AI/Muyan-TTS,https://huggingface.co/MYZY-AI/Muyan-TTS-SFT);前往 Github 获取代码(github.com/MYZY-AI/Muyan-TTS);技术报告(arxiv.org/abs/2504.19146)。
权威信源:官方介绍
中央网信办
部署开展「清朗·整治AI技术滥用」专项行动
为规范 AI 服务和应用,促进行业健康有序发展,保障公民合法权益,近日,中央网信办印发通知,在全国范围内部署开展为期 3 个月的「清朗·整治AI技术滥用」专项行动。中央网信办有关负责人表示,本次专项行动分两个阶段开展。
第一阶段强化 AI 技术源头治理,清理整治违规AI应用程序,加强AI生成合成技术和内容标识管理,推动网站平台提升检测鉴伪能力。第二阶段聚焦利用 AI 技术制作发布谣言、不实信息、色情低俗内容,假冒他人、从事网络水军活动等突出问题,集中清理相关违法不良信息,处置处罚违规账号、MCN 机构和网站平台。
权威信源:https://www.cac.gov.cn/2025-04/30/c_1747719097461951.htm | 官方介绍

Powered by 带带弟弟排版器 Pro
(文:赛博禅心)