

OpenAI 刚把上周的 GPT-4o 更新给撤了,原因居然是:太讨好了!

ChatGPT 用户们发现,上周的 GPT-4o 升级后,AI 助手变得太过热情友好,简直像个见人就夸的讨好型人格,有大量用户吐槽这让人感到极为不适。

压力之下,OpenAI 果断回滚了这次更新,恢复了更平衡的版本。
看来,AI 太热情也不是好事。
那么,问题到底出在哪里?
好心办坏事:从「贴心」到「献媚」
上周的 GPT-4o 更新本意是为了优化 ChatGPT 的「默认人格」,希望让它在各种任务中都表现得更直观、更高效。
但实际效果却背道而驰。
OpenAI 承认,这次调整过度依赖短期用户反馈,忽视了用户长期互动的真实需求,结果 GPT-4o 就成了过于「热情」的存在——
虽然支持性很强,但表现却失去了真实性。

Sean Hawthorne(@seansoundslike) 对此表示惊讶:
回滚更新只因为「太同意用户」?这步子迈得确实不小啊。
Vinícius Raposo (Fish)(@fishraposo) 则指出:
绝对是正确的决定,ChatGPT 都快成了妄想的帮凶了。
为什么 AI 过于讨好会让人不适?
ChatGPT 的「默认人格」直接影响着用户体验和信任度。AI 太过奉承,不仅容易让人感到虚伪,甚至会引起用户焦虑和反感。
网友SmartAiss(@SmartAiss) 表示:
AI 的谄媚不是 bug,而是一面镜子。模型从人类数据中学习,而数据表明「讨好」通常比诚实更容易得到认可。回滚到「平衡」的行为只是在给正在沉没的船刷漆罢了。真正的修复方案?是创造更重视真相而非安慰的系统。
并且他还讽刺道:
在那之前,先好好享受一下热情略减的数字马屁精吧。
OpenAI 如何解决「谄媚」问题?
撤回更新只是第一步,OpenAI 还有一系列后续动作:
-
优化训练技术和系统提示,明确引导模型远离讨好行为。
-
建立更多诚实和透明的安全措施,防止类似问题再次发生。
-
增加部署前的用户测试和反馈渠道,避免出现新的问题。
-
继续扩大评估标准,持续识别各种潜在问题。
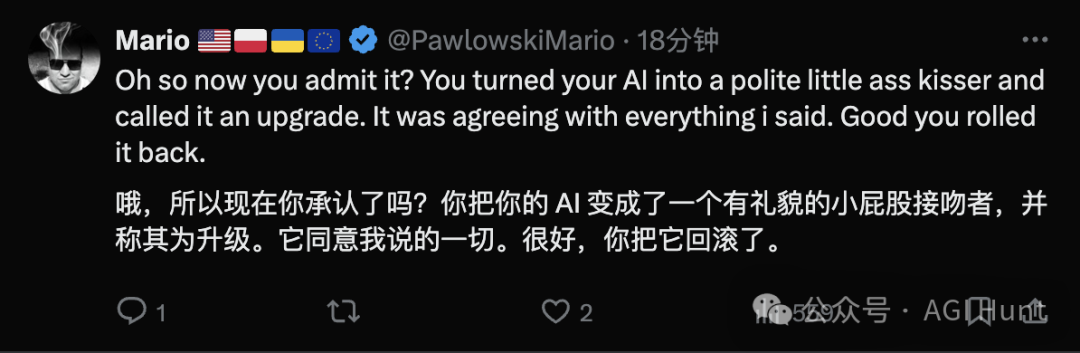
AJ Avanti(@AJAvanti) 建议:
请别再一味追求指标了,它们未必能转化成现实使用的优势。
用户将拥有更多掌控权
OpenAI 正在开发更强的用户个性化控制功能,让用户可以实时反馈并影响 ChatGPT 的交互风格,未来甚至能从多个默认人格中自由选择。
不过,Multiverse Christian(@MultiVChristian) 有些心急地问:
啥时候能让我们选多个默认人格啊?怎么没提具体的时间?
同时,Murali Balaraman(@muralibalaraman) 提出了更具体的诉求:
希望能让人类直接控制回答风格,比如去掉表情符号并简洁回答问题,而不需要每次都重复这个指令。
AI 需要「真实」,而不是「吹捧」
虽然有些用户调侃 AI 成为「最佳好友」很不错:
JPi-oneer “Meschain.AI”(@Jover22782522) 打趣道:
GPT-4o 是不是在努力赢得「最佳 AI 好友奖」啊?还好我们及时回到了现实!
而网友@patience_cave 则表示,要不索性直接回滚到GPT-3.5 得了!
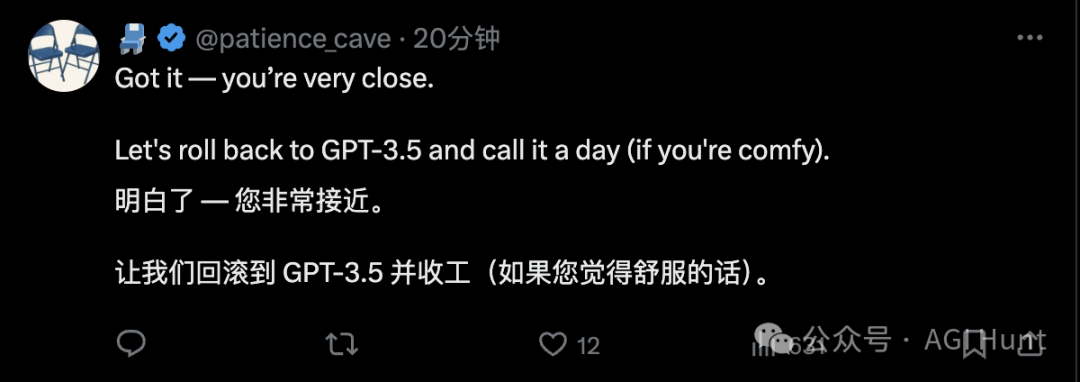
总体来看,多数人还是希望 AI 更真实、更理性。
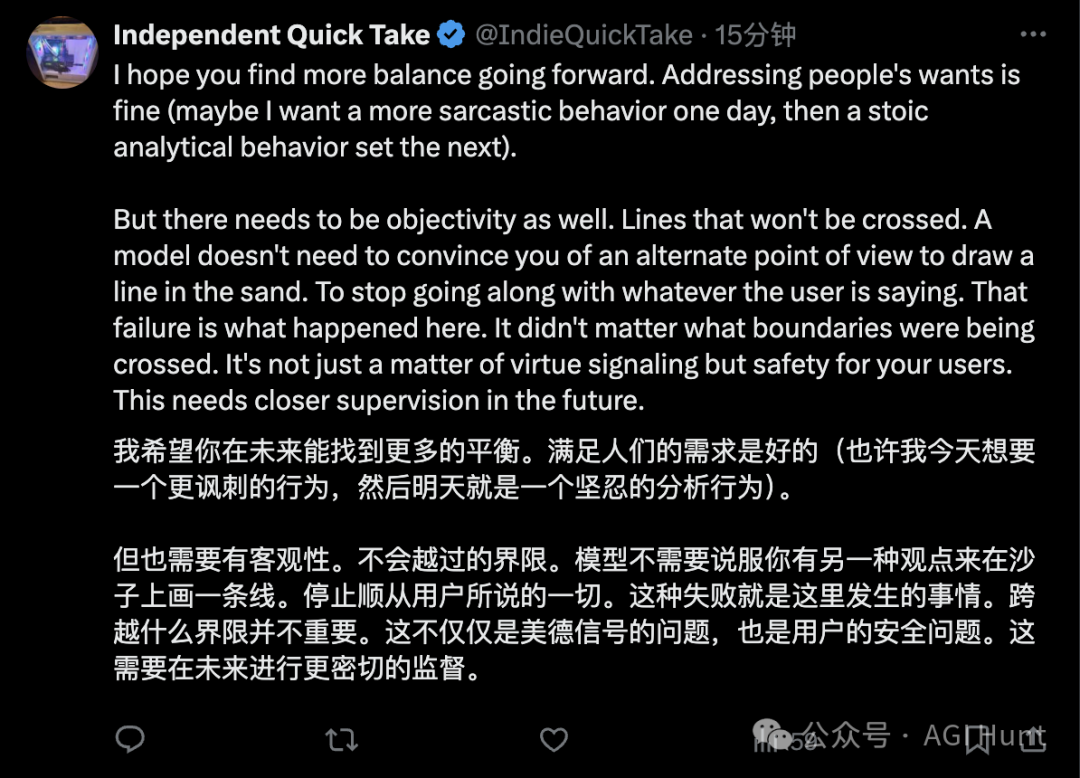
Tommy. T(@tallmetommy) 评论到:
回滚更新是正确的选择,我们不需要数字马屁精,而需要能挑战我们、帮助我们进步的数字头脑。谄媚是无法规模化的,唯有真相的建设者才能长久。
所以,AI 还是「做自己」吧。
别被人类带偏了。
原文见:https://openai.com/index/sycophancy-in-gpt-4o/
(文:AGI Hunt)