


首创 MLLM 与 DiT 深度融合,阶跃星辰发布开源图像编辑模型 Step1X-Edit。

Step1X-Edit:统一的图像编辑模型在各种真实用户指令上的效果
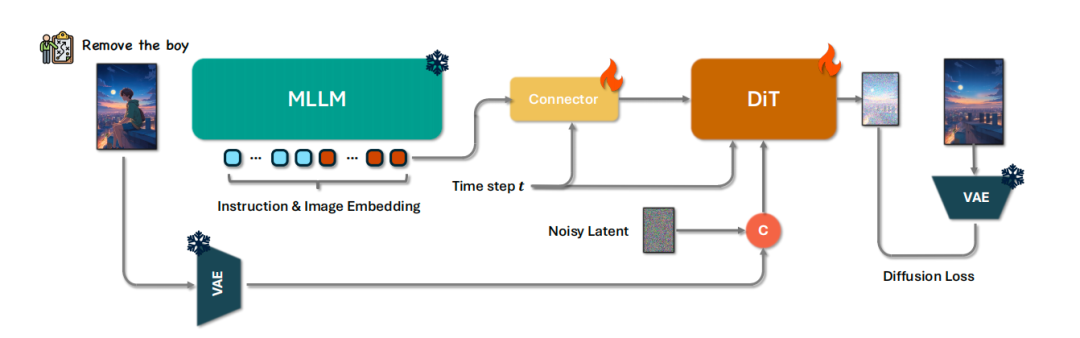
Step1X-Edit 由 19B 参数构成(7B 多模态语言模型 MLLM + 12B 扩散图像 Transformer DiT),具备语义精准解析、身份一致性保持和高精度区域级控制三项核心能力。模型支持包括文字替换、风格迁移、材质变换、人物修图在内的 11 类高频图像编辑任务,能够灵活应对复杂的编辑指令。

在技术路径上,Step1X-Edit 首次在开源体系中实现了多模态语言理解与扩散图像生成的深度融合。模型能够解析参考图像与用户编辑指令,提取潜在嵌入,并与扩散式图像解码器协同工作,生成符合预期的高质量编辑图像。
为了有效支撑模型训练,团队自建了全新的高质量数据生成管道,自动生成由参考图像、编辑指令与目标图像组成的大规模三元组数据集,确保数据在多样性、代表性与精度上的高标准,为模型的全面学习与泛化能力打下坚实基础。
在科学评估方面,团队构建了全新的 GEdit-Bench 基准,基于真实用户指令进行设计。评测结果显示,Step1X-Edit 在语义一致性、图像质量与综合得分等多项指标上,显著优于现有开源图像编辑模型,在开源体系中达到了新的性能高度。
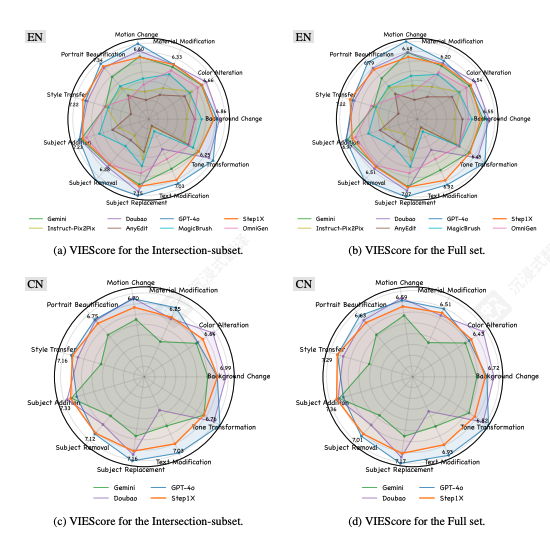
GEdit‑Bench 中每个子任务的 VIEScore,所有结果均由 GPT‑4o 评估
Step1X-Edit 相关体验地址
-
https://github.com/stepfun-ai/Step1X-Edit
-
https://huggingface.co/stepfun-ai/Step1X-Edit
-
https://www.modelscope.cn/models/stepfun-ai/Step1X-Edit/summary
-
https://arxiv.org/pdf/2504.17761

风吹,万物生,🌱
三大GPU算子挑战上线:FP8 GEMM、MLA with ROPE、Fused MoE
💰10万美元奖金等你来领!
🌍 全球开发者热血竞技,硅谷之约等你来赴~

(文:AI科技大本营)