

今天是2025年4月26日,星期六,北京,晴。
我们继续看两个问题。
一个是回顾下老刘说NLP社区20250425技术进展早报,社区讨论不少,外部的技术进展也有一些,可看看。
另一个是对GraphRAG用在Agent方案Graphiti进行解读,看它是个啥,用来做什么,跟Graphrag有啥区别,了解下技术实现原理。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、老刘说NLP社区20250425技术进展早报
来看看昨日0425进展,围绕MCP可信度、GraphRAG用在agent、目标检测跟踪库、金融领域推理大模型、法律领域数据、3D建模大模型、多模态数据预标注等话题,供各位参考,这是社区的日常活动之一,有兴趣的可加入。

1、关于MCP的一个观点
Mcp还有一个较大的问题,你把你的业务命运交给一个你无法控制的provider,比如都说exa.ai的mcp服务能提供realtime的检索,但是用了证明根本不real-time,所以这个时候你对你业务要求高,不如你自己写function calling+n多测试更有把握。个人用,跟企业用还不太一样。敢用才能有用。
2、GraphRAG用在agent进展
《Zep: A Temporal Knowledge Graph Architecture for Agent Memory》,https://arxiv.org/pdf/2501.13956,https://github.com/getzep/graphiti
也搞成了MCP就叫做Graphiti MCP Server,https://github.com/getzep/graphiti/blob/main/mcp_server/README.md。直接理解就是,用来管agent里面memory的graphrag,把agent 的memory 进行graph化存储跟检索的组件。
3、目标检测跟踪库
社区之前有讨论火灾实时监测的任务,可以参考trackers:https://github.com/roboflow/trackers
4、金融领域推理大模型进展
DianJin-R1、Fin-R1及文档转markdown、docx的多模态大模型做法,https://mp.weixin.qq.com/s/npPf0aZPrxb4njUGVjRlkQ,金融领域推理模型进展,《DianJin-R1: Evaluating and Enhancing Financial Reasoning in Large Language Models》(https://arxiv.org/pdf/2504.15716),模型及数据相关地址在:https://huggingface.co/DianJin,https://modelscope.cn/organization/tongyi dianjin,https://github.com/aliyun/qwen-dianjin,https://tongyi.aliyun.com/dianjin,https://github.com/aliyun/qwen-dianjin/blob/master/DianJin-R1/README_zh.md
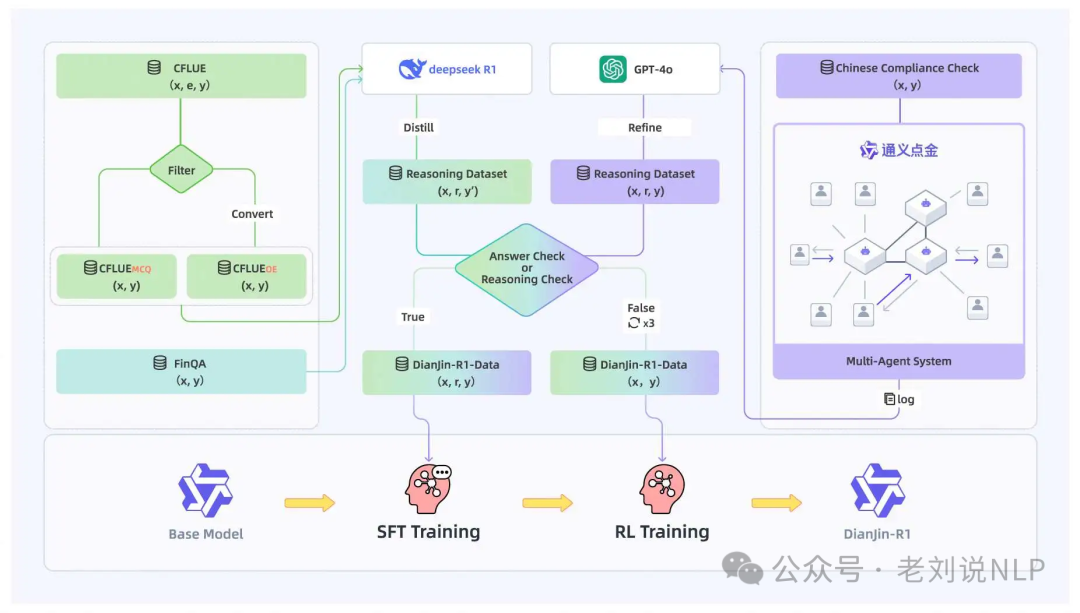
这个工作认为,金融任务通常需要领域特定的知识、精确的数值计算和严格的合规规则,所以提出一个增强的推理框架DianJin-R1,通过推理增强的监督学习和强化学习来解决。里面提到的多agent生成答案,然后再让gpt4-o合成一个综合的推理答案的思路可以借鉴,就是分合操作。
5、关于法律领域数据
社区昨天进行法律领域数据的讨论。法律数据相关的datasets,https://github.com/twang2218/law-datasets;也可以看cail比赛。

6、关于3D建模进展
已有相应的开源大模型项目出来,例如腾讯3D模型官网地址:https://3d.hunyuan.tencent.com/,Github地址:https://github.com/Tencent/Hunyuan3D-1,
Hugging Face 模型地址:https://huggingface.co/tencent/Hunyuan3D-1,Gitee地址:https://gitee.com/Tencent/Hunyuan3D-1
7、关于多模态微调数据预标注的问题
讨论EasyDataset(https://github.com/ConardLi/easy-dataset)不能标注图像数据的问题,
可以自己写脚本蒸馏,也可以使用labelme,labelstudio等,有自动预标注功能。详情见社区讨论。

二、GraphRAG用在Agent方案Graphiti解读
我们继续来看GraphRAG用在Agent的进展,有个工作叫做 Graphiti(https://github.com/getzep/graphiti),一个动态的、时序感知的知识图谱引擎(组件)。

直接理解就是,用来管agent里面memory的graphrag,把agent 的memory进行graph化存储跟检索的组件,就是把kg,揉进memory里面了,把agent 的memory 进行graph化存储跟检索的工具。所以,其就是一个组件的存在,是Zep代理记忆层的核心,用于LLM驱动的助手和代理,使助手和代理能够进行长期记忆和基于状态的推理。
这里就要说到zep,zep是一种用于AI代理的记忆层服务,旨在通过动态知识图谱增强大模型(LLMs)的能力,具体的工作在《Zep: A Temporal Knowledge Graph Architecture for Agent Memory》,https://arxiv.org/pdf/2501.13956,核心思想是,通过动态、时间感知的知识图谱引擎Graphiti,实现从非结构化对话数据和结构化业务数据中动态合成知识。
在效果侧,Zep在Deep Memory Retrieval (DMR)基准测试中表现出色,并在更全面和更具挑战性的LongMemEval基准测试中验证了其能力。
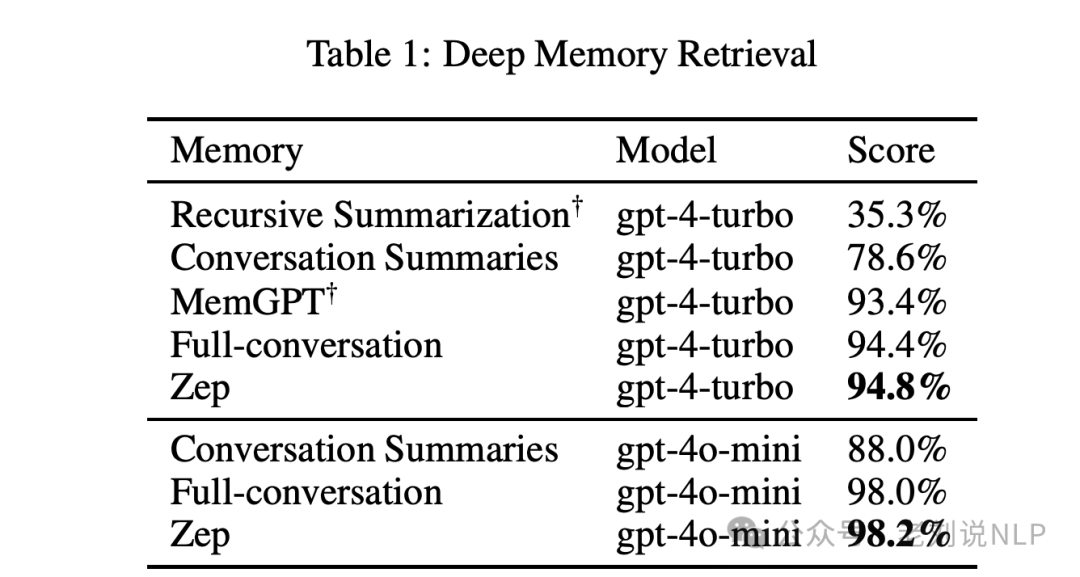
那么,其是如何做到的,可以看几个问题:
Graphiti的核心是处理非结构化和结构化数据,用来创建和查询随时间演化的知识图谱,以处理不断变化的关系并保持历史上下文,并使用时间、全文、语义和图算法方法进行查询。
先看建库阶段,图谱如何构建
知识图包括三个层次子图:事件子图、语义实体子图和社区子图。
事件子图存储原始输入数据,语义实体子图从事件中提取实体并解析,社区子图表示强连接实体的聚类。
其中:
事件是Zep图构建的起点,可以是消息、文本或JSON格式。每个事件包含一个时间戳,用于准确识别和提取消息内容中提到的时间信息。
从事件中提取实体,提取后,系统将每个实体名称嵌入到一个1024维的向量空间中,这种嵌入使得通过余弦相似性搜索在现有图实体节点中检索相似节点成为可能。
事实提取则通过分析消息内容提取关键谓词的事实。
时间提取上,系统使用时间戳提取事实的时间信息,包括绝对时间(如”1912年6月23日”)和相对时间(如”两周前”)。这些时间信息被存储在事实的边中,以便于后续的时间范围验证。当引入新的边时,系统会将其与现有边进行比较,以识别是否存在潜在矛盾。特别是,系统会检查新边的时间范围是否与现有边的时间范围重叠。如果存在重叠,系统会将受影响边的t_invalid字段设置为失效边的t_valid字段,从而标记这些边为失效。
对于社区子图,标签传播算法构建社区子图,动态更新社区表示以提高效率。社区节点包含其成员节点的摘要,并通过关键词嵌入支持快速检索
这个都是使用大模型来做的。
具体实现核心在于Graph Construction Prompts。包括实体抽取、实体消歧、事实抽取、事实消歧、时间抽取等。
Entity Extraction实体抽取的prompt:

Entity Resolution实体消歧的prompt:

Fact Extraction事实抽取的prompt:

Fact Resolution事实消歧的prompt:

Temporal Extraction时间抽取的prompt:

再看记忆检索又是如何做的?
对于输入,用户或代理提供一个文本查询(query),这个查询通常是对话中的一个问题或请求。它接受一个文本字符串查询α作为输入,并返回一个文本字符串上下文作为输出。输出β包含了节点和边格式化数据。过程f(α)→β包括三个不同的步骤

首先是搜索(Search),目标是将查询转换为包含语义边列表、实体节点和社区节点的三元组这三种图类型包含相关的文本信息。具体实现上包括余弦相似性搜索(Cosine Similarity Search):使用余弦相似性算法在知识图谱中查找与查询语义上相似的实体和关系;全文搜索(Full-Text Search):使用全文搜索引擎(如Lucene)查找与查询文本相似的实体和关系;广度优先搜索(Breadth-First Search, BFS):在知识图谱中进行广度优先搜索,识别与查询相关的节点和边,特别是在最近提到的内容中。然后将搜索结果收集为一个列表,包括相关的实体节点和关系边。
其次是重排序(Reranking),使用重排序器对搜索结果进行排序,以提高结果的相关性。重排序方案包括互惠排名融合(RRF)结合多个检索结果的排名、最大边际相关性(MMR)平衡相关性和多样性以及基于对话提及的重排序根据实体或事实在对话中的提及频率进行排序、节点距离重排序器根据节点与查询的图距离进行排序以及交叉编码器使用LLM通过交叉注意力评估节点和边的相关性。
最后是构建上下文(Constructor),将重排序后的结果转换为适合LLM使用的文本格式。对于每个相关的边,返回事实和其有效时间范围。对于每个相关的实体,返回实体名称和摘要。对于每个相关的社区,返回社区摘要。

最终生成的上下文字符串被提供给LLM代理,用于生成对查询的响应。
所以,看到这,我们不禁会想,这不就是GraphRAG么?
对的,Graphiti和GraphRAG都是用于处理和查询知识图谱的工具,但它们在设计目标、功能和应用场景上有一些显著的区别,如下【有些地方可能写的并不对】
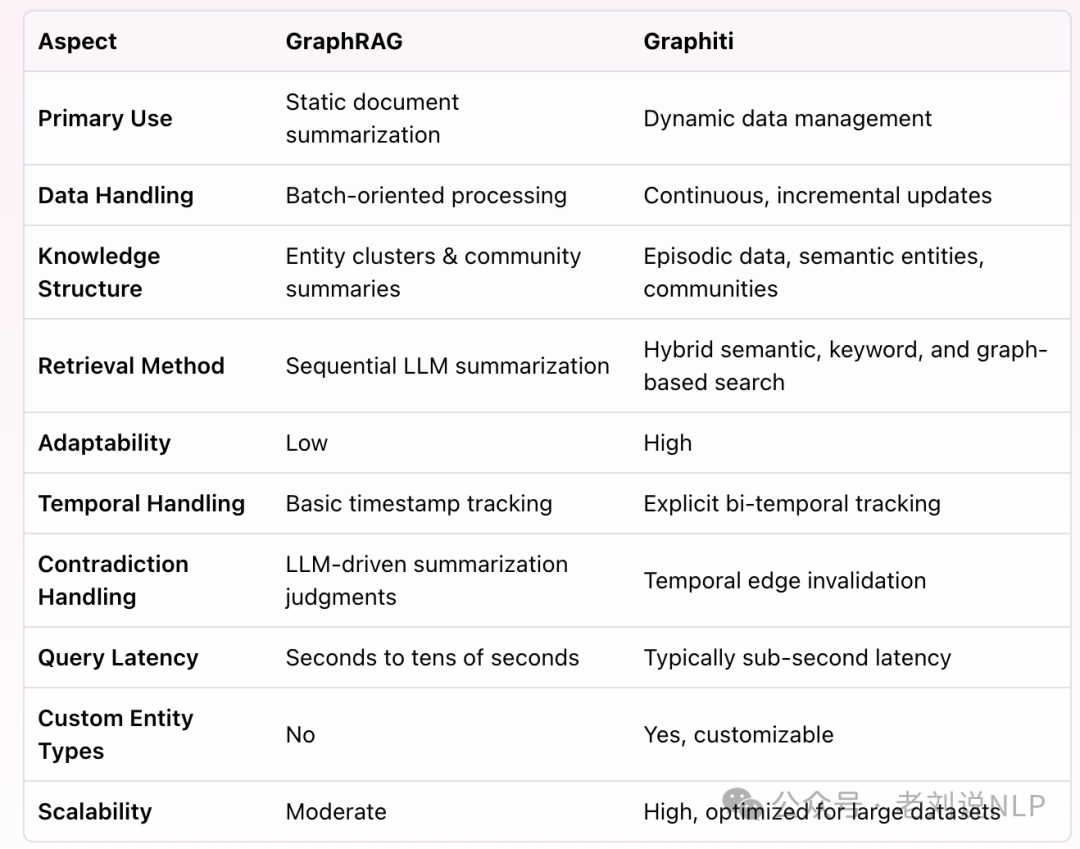
在设计目标上GraphRAG主要设计用于静态文档的总结,通过使用图来更好地建模文档语料库,并通过语义和图搜索技术提供这种表示;Graphiti从一开始就设计用于处理不断变化的信息,支持混合语义和图搜索,并且能够扩展以处理大规模数据集。
在数据处理上,GraphRAG,批量处理,面向批处理的处理方式,专注于实体集群和社区摘要;Graphiti则连续、增量更新,支持动态数据处理,将数据作为离散的事件进行摄取,维护数据来源并允许增量实体和关系提取。
在知识结构上,GraphRAG使用实体簇和社区摘要来表示知识结构,通过顺序的LLM总结来进行检索;Graphiti则支持事件驱动的数据、语义实体和社区,结合语义和BM25全文搜索,并能根据与中心节点的距离重新排序结果。
在搜索方法上,GraphRAG顺序的LLM总结,逐个处理文本块;Graphiti则混合语义、关键词和基于图的搜索, 能够根据时间戳进行点查询,并记录关系的生命周期。
在适应性上,GraphRAG适应性较低,主要用于静态文档;Graphiti则高度适应,能够处理动态和频繁更新的数据集。
在时间处理上,GraphRAG为基本的时戳跟踪;Graphiti有明确的双时态跟踪,能够处理时间上的矛盾。
在查询延迟上,GraphRAG的查询延迟为几秒到几十秒;Graphiti通常在亚秒级延迟内完成查询。
在自定义实体类型上,GraphRAG不支持自定义实体类型;Graphiti支持自定义实体类型,适用于特定应用领域的精确知识表示。
在可扩展性上,GraphRAG具有中等可扩展性;Graphiti高可扩展性,优化处理大规模数据集。
在数据源支持上,GraphRAG主要处理文本数据;Graphiti支持无结构文本和结构化JSON数据的摄取。
也就是说,Graphiti在处理动态数据和实时交互方面具有明显优势,而GraphRAG更适合于静态文档的总结和分析。选择哪个工具取决于具体的应用需求和数据特性。,毕竟前者是为了做agent,适用于需要实时交互和精确历史查询的应用,就是让agent里面的moemory上下文召回的更准确,更动态。后者是为了做rag,两者的目标不一样。
当然咯,也可以贴一下最近的热点MCP,也搞成了MCP就叫做Graphiti MCP Server,https://github.com/getzep/graphiti/blob/main/mcp_server/README.md。

参考文献
1、https://github.com/getzep/graphiti
(文:老刘说NLP)