

金磊 发自 凹非寺
量子位 | 公众号 QbitAI
不是5秒,不是10秒,更不只是1分钟。
AI视频生成,正式迎来无限时长的时代!
来,话不多说,直接来看一部AI版《罗马假日》:
而就是这么一部小短剧片段,它的“起点”,仅仅就是一张照片和一句Prompt:
身着优雅西装的欧美男子与一位美女漫步在罗马街头,分享各自的生活趣事,眼神中满是欣赏;夕阳西下,余晖洒在两人脸上,彼此深情对视。

△视频生成输入的第一帧图像
或许你会说,这不就是AI一口气生成出来的37秒视频吗?
非也,非也。
它创作出来的方式,实则是先生成一个30秒的视频,然后用一套“Extend(扩展)大法”继续去延长视频的时间。
方法就是pick刚才已经生成的视频,再来一句Prompt:
两个人拥抱到了一起。
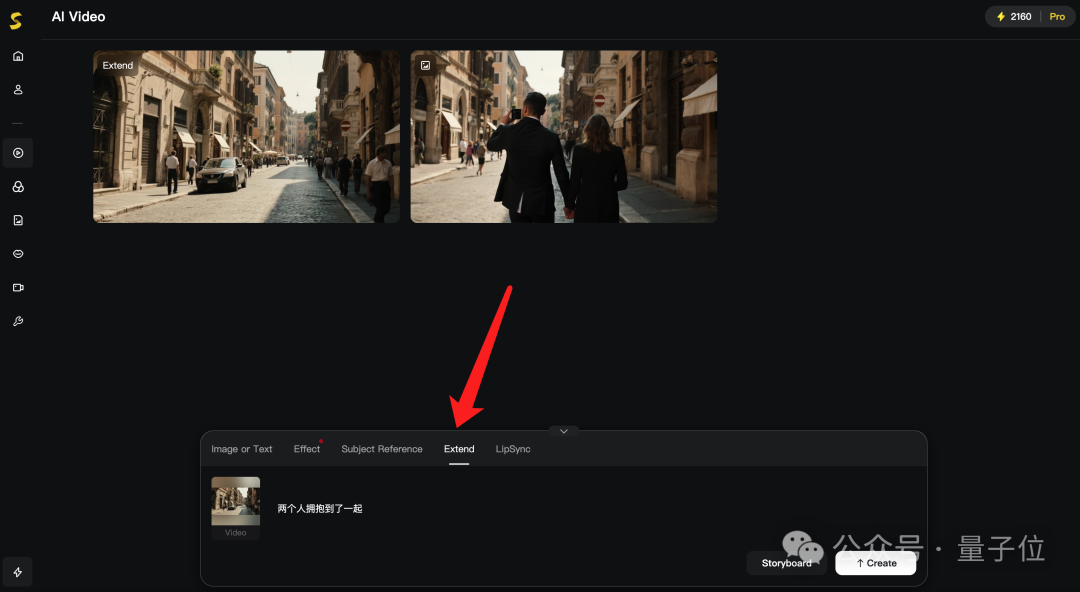
最后,在前面所有画面人物都没有发生变化的同时,AI根据后续的Prompt,继续扩展了7秒钟。
通过这种方式,如果你想继续延长视频的情节和时长,只需反复上述操作即可。
这就是无限时长的由来了。
而这个AI,正是昆仑万维最新升级的SkyReels-V2。作为全球首个无限时长视频生成模型,实现了电影级理解,并且全面开源。
整体体验下来,它的特点可以总结为一句话——很懂拍电影。
不仅在时长方面可以做到无限,对视频内容的连续性、镜头的自如切换,以及主体的一致性等等都做到了不错的把控。
那么昆仑万维为什么要搞这样的一个AI呢?
这是因为全球AI视频生成领域正面临三大核心痛点:
-
时长限制:主流模型仅能生成5-10秒片段,无法满足影视级叙事需求 -
专业度缺失:通用模型难以理解镜头语言、运镜逻辑等电影语法 -
质量妥协:提升分辨率往往牺牲运动流畅性,物理合理性频遭诟病
这也正是SkyReels-V2要解决的问题。
接下来,为了把这种效果体现得更加明显一些,我们继续一波实测走起。
实测AI视频的无限生成
这一次,我们以5秒为一个单位,一点一点地把玩一下这个无限生成模式。
先“喂”给SkyReels-V2这样的一张静态图片:

然后我们先让这张漫画风的图片,按照物理规则动起来:
保持漫画风格,画面中的树、湖面、男孩的头发,随风飘动。

继续用Prompt来扩展后续视频内容:
男孩子突然发现鱼漂和鱼竿开始抖动,脸上露出惊喜的表情。

男孩立马站起身来,双手用力拽鱼竿。

男孩身子往后退,用力拽鱼竿,没钓到鱼。

就在这么5秒、5秒的扩展之后,我们就完成了一小段动漫的场景:
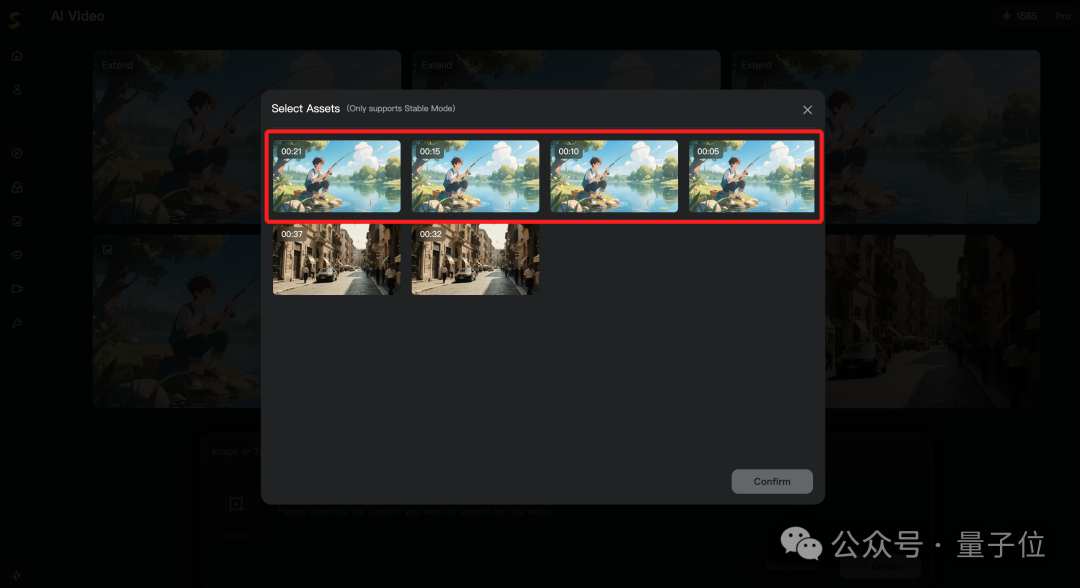
值得一提的是,刚才我们完整展示的2个视频的BGM,同样也是由昆仑万维的音乐生成AI——Mureka来生成的哦~
除此之外,官方这次也展示了几个不错的效果。
例如女生化妆的AI视频生成:
以及水母在海洋徜徉:
那么在看完效果之后,接下来的一个问题就是:如何做到的?
背后的技术也开源了
在科普SkyReels-V2技术之前,我们还应当先了解一下当前视频生成模型在技术上普遍存的问题。
归结来看,主要分为三点,即:
-
通用多模态大语言模型(MLLM)难以理解专业电影语法(如镜头构图、演员表情和摄像机运动); -
现有优化目标未能充分探索运动质量; -
扩散模型和自回归模型各自的局限性导致难以兼顾视觉质量与时间连贯性。
对此,昆仑万维团队提出的SkyReels-V2,便是通过结合多模态大语言模型(MLLM)、多阶段预训练、强化学习和扩散强制框架,实现了在提示遵循度、视觉质量、运动动态和时长方面的突破性进展。
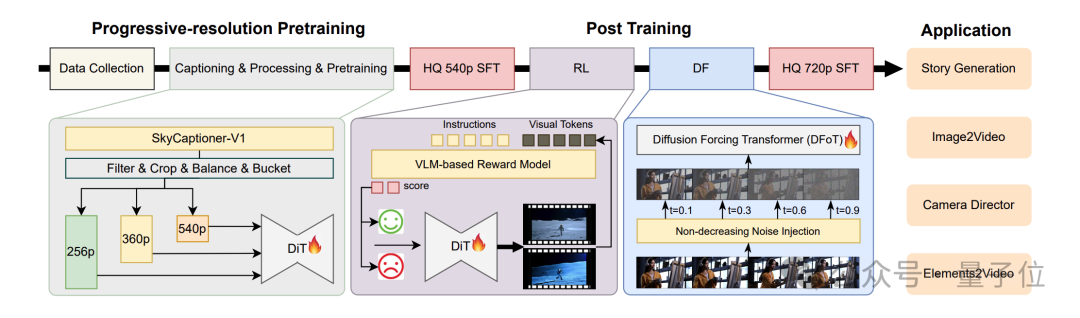
首先,SkyReels-V2的首要创新是设计了一套全面的视频结构化表示方法,将通用描述与专业镜头语言相结合。
这个系统包括主体描述(类型、外观、动作、表情、位置等)、镜头元数据(镜头类型、镜头角度、镜头位置等)、摄像机运动(例如推拉摇移等专业运动参数)。
为实现上述专业维度的高精度标注,研发团队针对性训练了多个专家级模型。
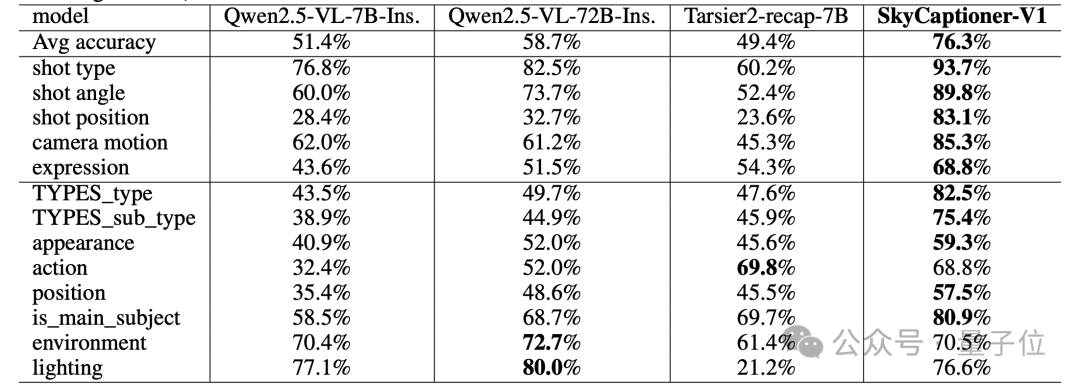
例如镜头标注器,它可精确识别镜头类型、角度与位置,在测试中分别取得 82.2%、78.7% 和 93.1% 的准确率。
表情标注器则能深度解析七种基础情绪及其强度变化,平均精度达到 85%;还有摄像机运动标注器,采用6DoF坐标参数化运动,单类型运动识别准确率89%。
这些专家模型与基础MLLM的知识被蒸馏到统一的SkyCaptioner-V1模型中,最终形成了一个平均准确率达76.3%的专业视频标注系统,尤其在镜头相关字段上表现突出(镜头类型识别准确率93.7%)。
除此之外,SkyReels-V2还采用一个三阶段渐进分辨率预训练框架:
- 低分辨率阶段(256p)
:通过图像-视频联合训练建立基础生成能力 - 中分辨率阶段(360p)
:应用更复杂的数据过滤策略提升清晰度 - 高分辨率阶段(540p)
:专注于视频目标,采用更严格的质量标准
训练中采用双轴分桶框架(时长桶×宽高比桶)和FPS归一化技术,有效处理视频数据的时空异质性。优化器使用AdamW,学习率从1e-4逐步降至2e-5,确保稳定收敛。
而针对视频生成中常见的运动质量问题(幅度不当、主体变形、物理规律违反等),团队设计了半自动偏好数据收集管道。
它包含两种类型的数据,一个是人工标注数据,由专业人员评估运动质量,形成1200个视频测试集;另一个是自动生成数据,通过渐进失真创建技术模拟各种运动缺陷。

基于这些数据,团队训练了专门的奖励模型,并应用流匹配直接偏好优化(Flow-DPO)技术,通过三阶段训练(每阶段20k数据)显著提升了运动质量。
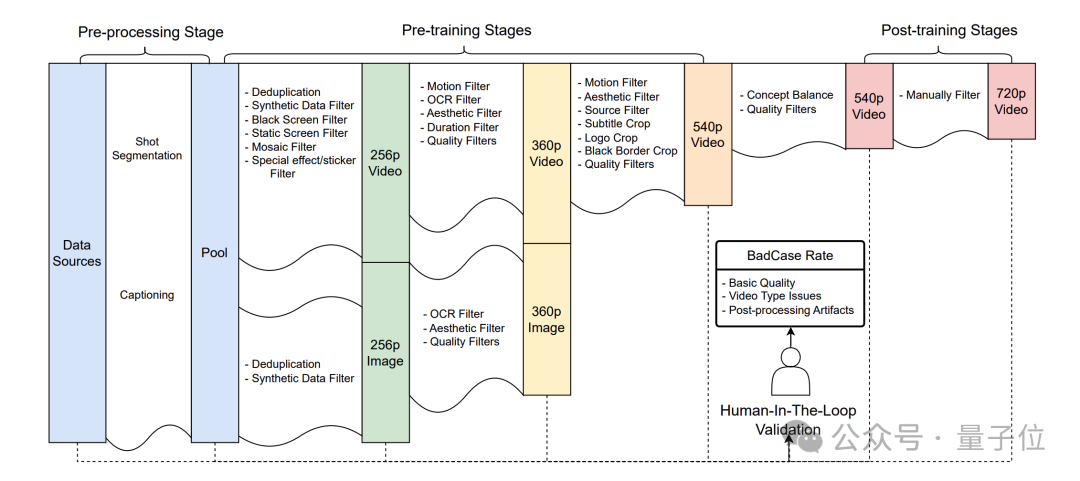
SkyReels-V2的核心突破是扩散强迫(Diffusion Forcing)技术,将传统扩散模型转化为支持无限长度生成的架构。
这个技术同样包含三个关键点。
一是帧导向概率传播(FoPP)时间步调度器,它通过动态编程计算非递减噪声计划,将组合空间从O(1e48)减少到O(1e32)。
二是自适应差异(AD)时间步调度器,可以支持从同步扩散(s=0)到自回归生成(s=T)的灵活调整。
最后则是上下文因果注意力,通过推理时缓存历史样本的K、V特征,显著降低计算开销。
这一框架使模型能够以前一视频段的最后几帧为条件,生成新的帧序列,理论上支持无限长度扩展。为防止误差累积,团队采用轻微噪声标记已生成帧的稳定化技术。
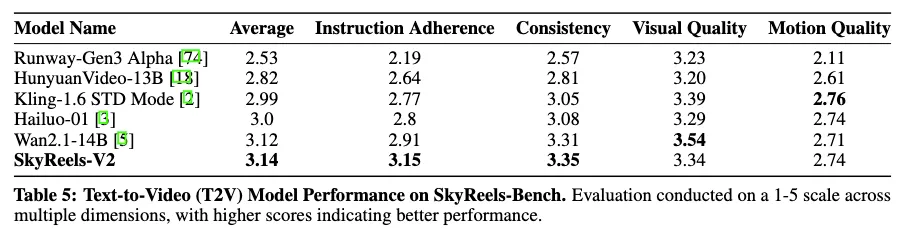
从昆仑万维以及第三方测试结果来看,在SkyReels-Bench评估中,SkyReels-V2在指令遵循方面取得了显著进展,同时在保证运动质量的同时不牺牲视频的一致性效果。
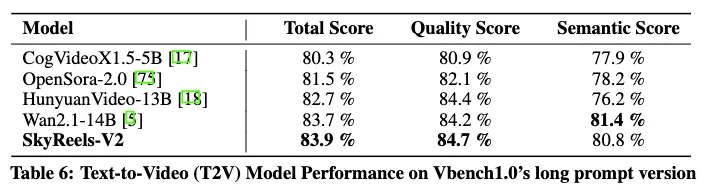
在VBench1.0自动化评估中,SkyReels-V2在总分(83.9%)和质量分(84.7%)上均优于所有对比模型,包括HunyuanVideo-13B和Wan2.1-14B。这一结果进一步验证了SkyReels-V2在生成高保真、指令对齐的视频内容方面的强大能力。
以上便是SkyReels-V2能够解锁如此实力背后的关键技术了,并且已经全部开源。
AI重塑内容生产
在解读完技术之后,我们还有个话题值得聊一聊——SkyReels-V2的问世,意味着什么?
归结为一句话,或许就是:
正在重塑、改写创意内容产业的DNA。
SkyReels-V2展现的不仅是技术能力,更是一种新型创作哲学的雏形。
当AI能够理解并执行“日落时分的海滩漫步”这样的抽象指令,并自主处理镜头运动、场景过渡等专业细节时,人类的角色正在从执行者转变为“创意导演”——专注于概念构思与审美判断等高层次创造活动。
这种人机协作模式指向了一个更为深刻的变革:艺术创作的重心从技艺展示转向思想表达。
创作者可以将更多精力投入叙事结构、情感传递和概念创新等真正体现人类独特性的领域,而将技术实现交由AI处理。
这或许正是文艺复兴时期“艺术家作为思想家”理想在数字时代的全新诠释。
而目光聚焦于昆仑万维本身,可以说它再一次走到了生成式AI大浪潮的前面:不仅有技术,还有产品,更是做到了全面开源。
据高盛预测,到2027年AI生成视频市场规模将突破万亿美元,而昆仑万维SkyReels-V2的横空出世,正以“无限时长+电影级质量+精准控制”三位一体的突破性技术,率先打开这片蓝海市场!
至于SkyReels-V2及其后继技术将如何继续改写创意产业的DNA,取决于我们如何以智慧与远见引导这场变革。
不过可以肯定的一点是,当技术最终成功隐入创作的背景,成为思维的自然延伸时,人类讲故事的方式,以及通过故事理解世界的方式,都将发生我们今日难以想象的深刻转变。
最后,体验地址放下面了,感兴趣的小伙伴快去尝鲜吧~
SkyReels官网地址:
https://www.skyreels.ai/home
GitHub地址:
[1]https://github.com/SkyworkAI/SkyReels-V2
[2]https://github.com/SkyworkAI/SkyReels-A2
HuggingFace地址:
[1]https://huggingface.co/collections/Skywork/skyreels-v2-6801b1b93df627d441d0d0d9
[2]https://huggingface.co/Skywork/SkyReels-A2
论文地址:
[1]https://arxiv.org/abs/2504.13074
[2]https://arxiv.org/pdf/2504.02436
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🌟 点亮星标 🌟
(文:量子位)