

构建能够可靠执行复杂多步任务的AI智能体,已成为当前大模型应用最前沿的方向。利用现有的编排框架,开发者可以快速搭建一个功能原型。然而,令人沮丧的是,这些智能体在真实场景中常常表现得像一个不稳定的“实习生”——面对稍有变化的指令就无所适-从,频繁犯错,并且难以从失败中吸取教训。这种不可靠性问题,正是阻碍当下AI智能体应用难以真正走向生产的“拦路虎”。
AI智能体训练的困境
理想的AI智能体应该像一个经验丰富的员工,能自主规划、使用工具并从结果中学习。然而,现有的RL训练框架在面对真实的智能体应用时,却暴露了三大核心局限:
-
难以处理“多轮对话”:现有框架大多聚焦于单轮互动(输入->输出->评分),这对于学习解数学题等任务尚可,但无法有效支持智能体天然的、需要多步骤决策和与环境持续交互的“多轮”工作流。
-
GPU效率低下:在智能体训练的“推演(rollout)”阶段,模型常常需要等待真实世界的动作完成(如浏览网页、调用API)。在这期间,宝贵的GPU资源被闲置,导致整体训练效率低下,成本高昂。
-
与现有代码库集成困难:真实的智能体往往深度嵌入在复杂的业务逻辑和各类编排框架(如CrewAI、Mastra)中。现有的RL训练流程要求开发者进行大量代码重构,难以“即插即用”,集成成本极高。
ART 介绍
为了精准地解决这些问题,一个名为 Agent Reinforcement Trainer (ART) 的开源强化学习(RL)框架诞生了,它为我们解决这一难题提供了一个全新的范式——为AI智能体提供“在职培训”。

这个项目锚定现有智能体训练框架的局限性。ART通过两大架构创新,巧妙地化解了上述困境:
-
分离的“前端”与“后端”:ART将训练循环一分为二。“前端” 负责定义智能体的行为逻辑和奖励计算,可以运行在开发者的本地环境中,无缝对接所有现有工具和代码库。“后端” 则专注于LLM的推理和训练,可以部署在任何云端GPU服务器上。这种解耦设计,彻底解决了集成困难和环境依赖的问题。
-
兼容OpenAI的推理端点:为了最大化生态兼容性,ART在训练时提供了一个行业标准的、与OpenAI兼容的聊天API端点。这意味着开发者几乎无需修改现有的推理代码,就能直接将ART接入,无论是使用原生OpenAI SDK还是LiteLLM等包装器。
在底层,ART整合了vLLM(推理)、TRL和Unsloth(训练)等业界顶级工具,并通过在训练期间将vLLM的KV缓存卸载到CPU内存等优化手段,进一步节省了显存使用,甚至让7B模型在Google Colab的免费套餐上也能流畅训练。
使用方法
下图展示了使用ART优化智能体的简化流程。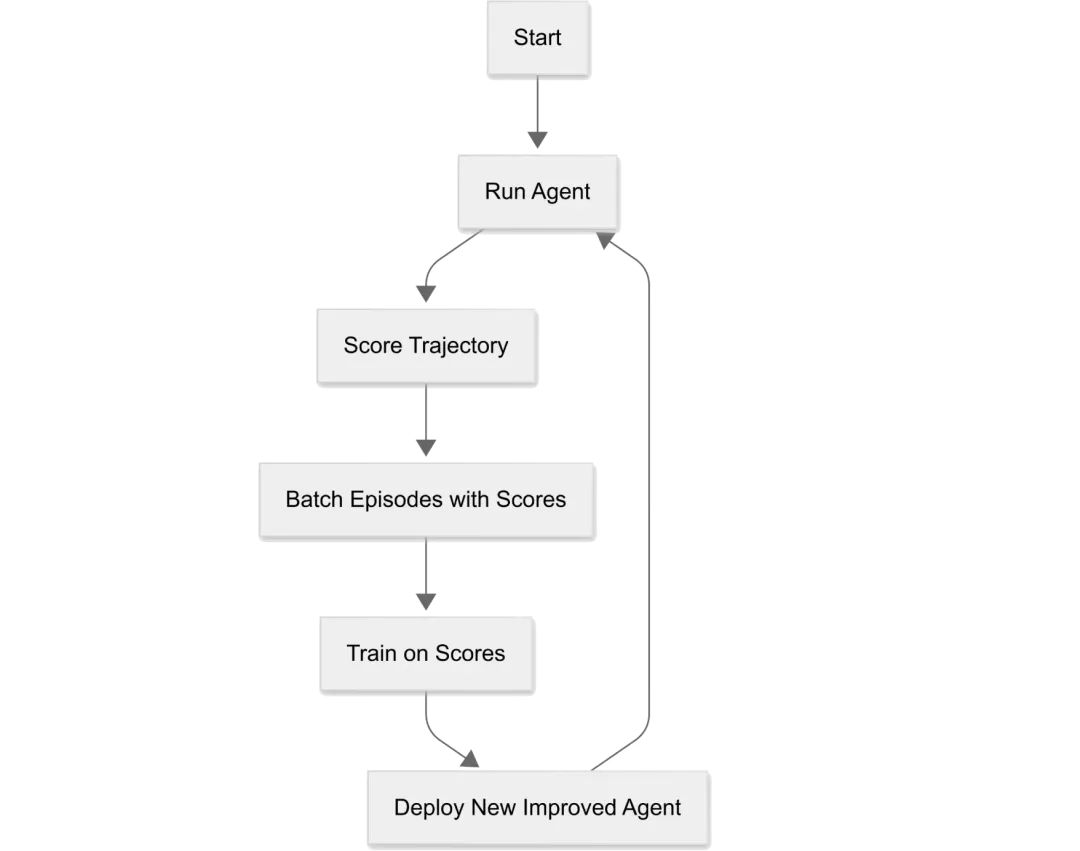 用户代码负责在环境中运行智能体并对其表现打分,ART则利用这些轨迹和分数来迭代地训练和改进智能体。
用户代码负责在环境中运行智能体并对其表现打分,ART则利用这些轨迹和分数来迭代地训练和改进智能体。
以下是使用ART的简单示例(2048 游戏)。
from dotenv import load_dotenv
import random
from typing import TypedDict
from typing import Literal
import string
import xml.etree.ElementTree as ET
load_dotenv()
WINNING_VALUE = 128
# Class that keeps track of state for a single game of 2048
class TwentyFortyEightGame(TypedDict):
id: str
board: list[list[int | None]]
# Randomly populates a cell on the board with a 2 or 4
def populate_random_cell(game: TwentyFortyEightGame) -> None:
all_clear_coordinates = [
(i, j)
for i in range(len(game["board"]))
for j in range(len(game["board"][i]))
if game["board"][i][j] is None
]
random_clear_coordinates = random.choice(all_clear_coordinates)
# 90% chance to populate a 2, 10% chance to populate a 4
game["board"][random_clear_coordinates[0]][random_clear_coordinates[1]] = (
2 if random.random() < 0.9 else 4
)
# Generates a new game of 2048
def generate_game(board_length: int = 4) -> TwentyFortyEightGame:
# random 6 character string
id = "".join(random.choices(string.ascii_letters + string.digits, k=6))
game = {
"id": id,
"board": [[None for _ in range(board_length)] for _ in range(board_length)],
}
# populate two random cells
populate_random_cell(game)
populate_random_cell(game)
return game
# Renders the board in a human-readable format
def render_board(game: TwentyFortyEightGame) -> str:
board = game["board"]
# print something like this:
# _ | 2 | _ | 4
# 4 | 8 | 2 | 16
# 16 | 32 | 64 | 128
# _ | 2 | 2 | 4
# where _ is an empty cell
max_cell_width = max(
[len(str(cell)) for row in board for cell in row if cell is not None]
)
board_str = ""
for row in board:
# pad the cells with spaces to make them the same width
board_str += "|".join(
[
str(cell).rjust(max_cell_width)
if cell is not None
else"_".rjust(max_cell_width)
for cell in row
]
)
board_str += "\n"
return board_str
# condense, privileging matches at the start of the sequence
# sequences should be passed starting with cells that are the furthest in the direction in which the board is being condensed
def condense_sequence(sequence: list[int | None]) -> list[int | None]:
condensed_sequence = []
gapless_sequence = [cell for cell in sequence if cell is not None]
i = 0
while i < len(gapless_sequence):
if (
i + 1 < len(gapless_sequence)
and gapless_sequence[i] == gapless_sequence[i + 1]
):
condensed_sequence.append(gapless_sequence[i] * 2)
i += 2
else:
condensed_sequence.append(gapless_sequence[i])
i += 1
# pad the sequence with None at the end
return condensed_sequence + [None] * (4 - len(condensed_sequence))
# Condenses the board in a given direction
def condense_board(
game: TwentyFortyEightGame, direction: Literal["left", "right", "up", "down"]
) -> None:
if direction == "left":
for row in game["board"]:
condensed_row = condense_sequence(row)
for i in range(len(row)):
row[i] = condensed_row[i]
if direction == "right":
for row in game["board"]:
reversed_row = row[::-1]
# reverse the row before and after condensing
condensed_row = condense_sequence(reversed_row)[::-1]
for i in range(len(row)):
row[i] = condensed_row[i]
if direction == "up":
for col_index in range(len(game["board"][0])):
column = [row[col_index] for row in game["board"]]
condensed_column = condense_sequence(column)
for row_index in range(len(column)):
game["board"][row_index][col_index] = condensed_column[row_index]
if direction == "down":
for col_index in range(len(game["board"][0])):
column = [row[col_index] for row in game["board"]]
reversed_column = column[::-1]
condensed_column = condense_sequence(reversed_column)[::-1]
for row_index in range(len(column)):
game["board"][row_index][col_index] = condensed_column[row_index]
# Applies an agent move to the game board
def apply_agent_move(game: TwentyFortyEightGame, move_xml: str) -> None:
direction = None
# parse the move
try:
root = ET.fromstring(move_xml)
direction = root.text
except Exception:
raise ValueError("Invalid xml")
if direction not in ["left", "right", "up", "down"]:
raise ValueError("Invalid direction")
condense_board(game, direction)
populate_random_cell(game)
# Returns the maximum cell value on the board
def max_cell_value(game: TwentyFortyEightGame) -> int:
return max([cell for row in game["board"] for cell in row if cell is not None])
# Returns True if the game is finished
def check_game_finished(game: TwentyFortyEightGame) -> bool:
if max_cell_value(game) >= WINNING_VALUE:
return True
# check if any cell is empty
if any(cell is None for row in game["board"] for cell in row):
return False
return True
# Returns the sum of all the cell values on the board
def total_board_value(game: TwentyFortyEightGame) -> int:
return sum([cell for row in game["board"] for cell in row if cell is not None])
import art
from art.local import LocalBackend
from dotenv import load_dotenv
load_dotenv()
random.seed(42)
# Declare the model
model = art.TrainableModel(
name="agent-002",
project="2048-multi-turn",
base_model="Qwen/Qwen2.5-3B-Instruct",
)
# To run on a T4, we need to override some config defaults.
model._internal_config = art.dev.InternalModelConfig(
init_args=art.dev.InitArgs(
max_seq_length=8192,
),
engine_args=art.dev.EngineArgs(
enforce_eager=True,
gpu_memory_utilization=0.8,
),
)
# Initialize the server
backend = LocalBackend(
# Normally we don't want to run the server in-process, but for the output
# to show up properly on Google Colab we'll enable this.
in_process=True,
path="./.art",
)
# Register the model with the local Backend (sets up logging, inference, and training)
await model.register(backend)
import art
import math
import requests
from pydantic import BaseModel
import weave
if os.getenv("WANDB_API_KEY", ""):
weave.init(model.project, settings={"print_call_link": False})
class Scenario2048(BaseModel):
step: int
@weave.op
@art.retry(exceptions=(requests.ReadTimeout))
async def rollout(model: art.Model, scenario: Scenario2048) -> art.Trajectory:
client = model.openai_client()
game = generate_game()
move_number = 0
trajectory = art.Trajectory(
messages_and_choices=[
{
"role": "system",
"content": "You are an excellent 2048 player. Always choose the move most likely to lead to combine cells to eventually reach the number 2048. Optional moves are 'left', 'right', 'up', 'down'. Return your move as an XML object with a single property 'move', like so: <move>left</move>",
}
],
metadata={
"game_id": game["id"],
"notebook-id": "2048",
"step": scenario.step,
},
reward=0,
)
while True:
trajectory.messages_and_choices.append(
{"role": "user", "content": render_board(game)}
)
try:
messages = trajectory.messages()
chat_completion = await client.chat.completions.create(
max_completion_tokens=128,
messages=messages,
model=model.name,
stream=False,
)
except Exception as e:
print("caught exception generating chat completion", e)
raise e
choice = chat_completion.choices[0]
content = choice.message.content
assert isinstance(content, str)
trajectory.messages_and_choices.append(choice)
try:
apply_agent_move(game, content)
move_number += 1
except ValueError:
trajectory.reward = -1
break
if check_game_finished(game):
max_value = max_cell_value(game)
board_value = total_board_value(game)
trajectory.metrics["max_value"] = max_value
trajectory.metrics["board_value"] = board_value
trajectory.metrics["move_number"] = move_number
# try to get as close to the winning value as possible
# otherwise, try to maximize number of high cells on board
# but above all else: WIN THE GAME!
if max_value < WINNING_VALUE:
# scale max value logarithmically between 0 for 2 and 1 for WINNING_VALUE
max_value_reward = (math.log(max_value, 2) - 1) / (
math.log(WINNING_VALUE, 2) - 1
)
# scale board value logarithmically between 0 for 2 * 16 and 1 for WINNING_VALUE * 16
board_value_reward = (math.log(board_value, 2) - 1) / (
math.log(WINNING_VALUE * 16, 2) - 1
)
# combine the two rewards, with max value having a higher weight
trajectory.reward = max_value_reward + (board_value_reward * 0.2)
else:
# double reward if the agent wins
trajectory.reward = 2
break
return trajectory
for i in range(await model.get_step(), 10):
train_groups = await art.gather_trajectory_groups(
(
art.TrajectoryGroup(rollout(model, Scenario2048(step=i)) for _ in range(18))
for _ in range(1)
),
pbar_desc="gather",
max_exceptions=18,
)
await model.delete_checkpoints()
await model.train(
train_groups,
config=art.TrainConfig(learning_rate=1e-5),
# Lowering the logprob_calculation_chunk_size is a memory saving measure
# to allow longer sequences (up to 8192 tokens) to be processed on a T4.
_config={"logprob_calculation_chunk_size": 8},
)
-
加载模型,评估
import torch
from unsloth import FastLanguageModel
# example: .art/2048-multi-turn/models/001/0003
lora_model_path = (
f".art/{model.project}/models/{model.name}/{await model.get_step():04d}"
)
print(f"loading model from {lora_model_path}\n")
peft_model, tokenizer = FastLanguageModel.from_pretrained(
model_name=lora_model_path,
max_seq_length=16384,
dtype=torch.bfloat16,
load_in_4bit=True,
)
FastLanguageModel.for_inference(peft_model)
game = generate_game()
move_number = 0
messages = [
{
"role": "system",
"content": "You are an excellent 2048 player. Always choose the move most likely to lead to combine cells to eventually reach the number 2048. Optional moves are 'left', 'right', 'up', 'down'. Return your move as an XML object with a single property 'move', like so: <move>left</move>",
},
]
while not check_game_finished(game):
rendered_board = render_board(game)
messages.append({"role": "user", "content": rendered_board})
inputs = tokenizer.apply_chat_template(
messages, return_tensors="pt", add_generation_prompt=True
).to("cuda")
content = ""
def get_completion() -> str:
with torch.no_grad():
outputs = peft_model.generate(
input_ids=inputs,
max_new_tokens=100,
do_sample=True,
temperature=0.7,
top_p=0.9,
)
return tokenizer.decode(
outputs[0][inputs.shape[1] :], skip_special_tokens=True
)
try:
content = get_completion()
except Exception as e:
print("caught exception generating chat completion", e)
raise e
messages.append({"role": "assistant", "content": content})
try:
apply_agent_move(game, content)
move_number += 1
except ValueError:
raise ValueError(f"Invalid move on move {move_number}: {content}")
# print the board every 10 moves
if move_number % 10 == 0:
print(f"\nmove {move_number}")
print(f"board:\n{rendered_board}")
print(f"agent move: {content}")
print(f"updated board:\n{render_board(game)}")
print(f"game finished in {move_number} moves")
max_value = max_cell_value(game)
board_value = total_board_value(game)
if max_value >= WINNING_VALUE:
print("game won! 💪")
else:
print("game lost! 😢")
print(f"final board:\n\n{render_board(game)}")
print(f"max value: {max_value}")
print(f"board value: {board_value}")
至此,从训练到使用的全过程就完成了。
loading model from .art/2048-multi-turn/models/agent-002/0010
==((====))== Unsloth 2025.5.1: Fast Qwen2 patching. Transformers: 4.51.3. vLLM: 0.8.5.post1.
\\ /| NVIDIA H100 PCIe. Num GPUs = 1. Max memory: 79.179 GB. Platform: Linux.
O^O/ \_/ \ Torch: 2.6.0+cu124. CUDA: 9.0. CUDA Toolkit: 12.4. Triton: 3.2.0
\ / Bfloat16 = TRUE. FA [Xformers = 0.0.29.post2. FA2 = False]
"-____-" Free license: http://github.com/unslothai/unsloth
Unsloth: Fast downloading is enabled - ignore downloading bars which are red colored!
The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
move 10
board:
_|2|4|2
_|_|4|4
2|_|4|2
_|_|_|_
agent move: <move>down</move>
updated board:
_|_|_|_
4|_|_|2
_|_|4|4
2|2|8|2
...
性能表现
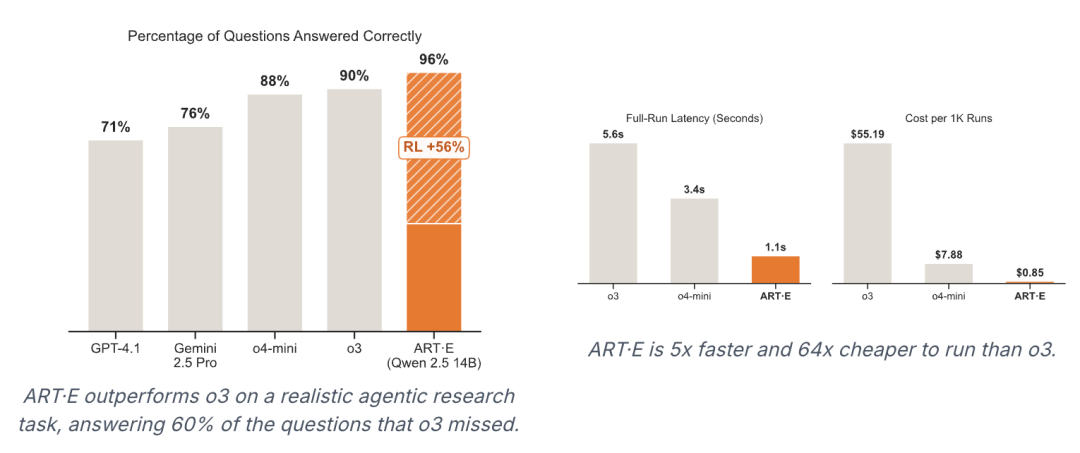
在名为“ART·E”的真实世界案例中,研究团队挑战了通过搜索邮件收件箱来回答自然语言问题的任务。他们利用公开的安然(Enron)邮件数据集,并创新地使用GPT-4.1合成了约4000个高质量的问答对,解决了缺乏训练数据的难题。智能体被赋予了搜索邮件、阅读邮件和返回答案三个基本工具。在训练中,ART的GRPO循环为每个问题生成4个不同的执行轨迹,并基于一个复合奖励函数进行优化——该函数不仅奖励正确答案,还惩罚“幻觉”并鼓励用更少的步骤完成任务。
完整代码:https://colab.research.google.com/github/openpipe/art/blob/main/examples/art-e/art-e.ipynb#scrollTo=thQ4e6tqk_I1
最终,经过训练的模型在准确率和效率上均超越了强大的o3模型,而整个训练过程在单个H100 GPU上仅耗时不到一天,成本约为80美元,充分展示了ART的强大效能与经济性。
ART很棒,但在开始使用之前,开发者建议先确认任务是否满足以下条件:
-
已有一定的成功率:开源模型在你的任务上至少已经能达到30%左右的成功率。RL擅长优化和提升,但如果任务对模型来说过于困难,它可能无法有效学习。 -
可量化的成功标准:你需要能够清晰地判断一次任务尝试是成功还是失败,并量化其表现。这个“奖励”可以是客观的(如“答案是否匹配标准答案”)或主观的(如“裁判LLM是否认为结果满意”)。 -
可重复执行的环境:训练过程需要智能体在同一场景下并行尝试多次。因此,该任务不应在训练中对真实世界产生不可逆的改变。
小结
就像当下上下文工程(上下文工程的崛起:提示工程已是过去式)以及Prompt优化(DSPY(DSPy(声明式自改进语言程序),面向大模型编程的新方法,克服当前LLM应用开发的诸多缺点),APE(Weavel Ape超过DSPy,或将成为最好用的提示(prompt)优化工具))思路一样,如何闭环整个过程,简化实施的复杂度,持续迭代改进,是提升工程化水平的关键,Agent Reinforcement Trainer (ART) 的出现,瞄准当前AI智能体困境,通过一套高效、易于集成且能从经验中学习的训练机制,持续提升表现。
github:https://github.com/OpenPipe/ART
公众号回复“进群”入群讨论。
(文:AI工程化)