
PyTorch 被广泛认为是众多深度学习研究人员和工程师的首选框架,然而,并非所有人都能充分发挥其潜力。目前,PyTorch 就像一头难以驯服的猛兽,许多强大的性能特性隐藏在开发者文档的深处。
网上常见的“Top-N”列表通常是泛泛而谈的内容,缺乏深度。为此,我对 PyTorch 的关键调优技术和设置进行了全面的实证测试,组合测试了不同模型架构和规模、不同 PyTorch 版本,甚至不同 Docker 容器中的推理性能。以下是我总结的关键发现,以及无论如何你都应该使用的技巧!
无需赘述常规介绍,我们逐一揭秘这些特性,探讨它们的用途、重要性及实现方法。
1. 始终使用混合精度
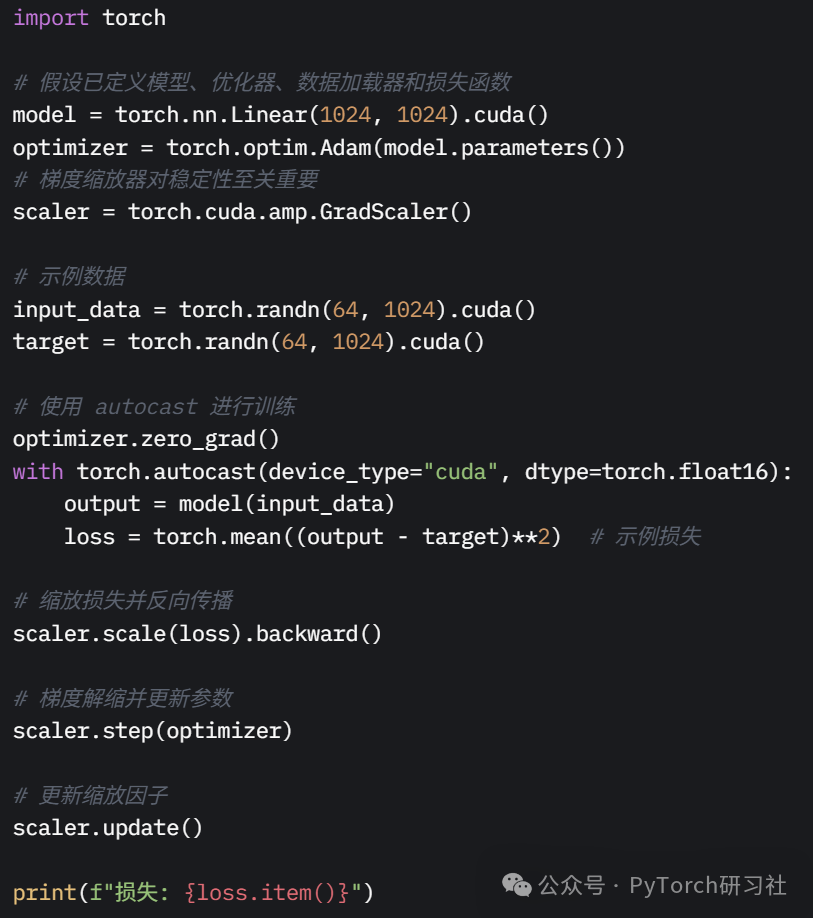
提升性能最简单的方法是使用混合精度训练。它在训练过程中结合低精度(如 float16 或 bfloat16)和标准精度(float32)格式。
torch.autocast() 是一个现代上下文管理器,能在作用域内自动将张量转换为合适的类型,同时确保梯度精度。低精度计算占用更少的内存,允许使用更大的模型或批次大小。现代 GPU 架构还能利用专用硬件核心显著加速计算,提升吞吐量并减少带宽需求。torch.autocast 简化了这一过程,自动处理类型转换,检测哪些层和操作可使用低精度(fp16/bf16/fp8)并相应转换张量。
2. 尽可能使用 PyTorch 2.0(或更高版本)
PyTorch 2.0 引入的 torch.compile() 是一个强大的即时编译(JIT)工具。只需添加一个简单的函数装饰器,它就能将你的 PyTorch 代码编译为优化的内核,使用 TorchInductor 等技术,支持 Triton 或 C++ 后端。用户通常只需最小的代码改动,就能获得显著的性能提升(在多种基准测试中通常提速 30-200%)。编译过程带来了速度优势,同时避免了 torch.jit 脚本化或跟踪的复杂性。

3. 推理时别忘了启用推理模式
这是一个简单但常被忽略的细节——如果你在进行推理而非训练/优化,记得使用 torch.inference_mode() 启用推理模式。
需要注意的是,model.eval()、torch.no_grad() 和 torch.inference_mode() 看似功能相似,实际上各有不同(且同样重要)。后两者是上下文管理器,用于在模型评估或推理时禁用梯度计算。推理期间,梯度计算是多余的开销,禁用它能显著节省内存(无需存储反向传播所需的中间激活值)并大幅加速计算!
-
使用 model.eval() 准备模块和层进行推理:
它会对特定层产生影响,例如禁用 dropout 层、改变批归一化行为等。推理时绝不能忘记这一步。 -
使用 torch.inference_mode() 防止推理时计算/存储梯度:
它让 PyTorch 跳过一些张量记录和检查,基本取代了 torch.no_grad(),明确告诉 PyTorch 不需要梯度反向传播。 -
仅在 torch.inference_mode() 不适用时使用 torch.no_grad():
如果你希望获得 torch.inference_mode() 的性能优势,但后续需要在梯度模式下使用张量结果,torch.no_grad() 可能是更好的选择。有关自动梯度机制的更多细节,可查阅相关文档。

4. 对 CNN 使用 Channels-Last 内存格式
在特定硬件和软件组合(如 NVIDIA GPU + cuDNN)上,采用 NHWC 格式(而非 NCHW,即批次、通道、高度、宽度)进行卷积操作可显著提升速度。这主要得益于更优的数据局部性和硬件加速的优化卷积内核。在排除混合精度的影响(所有计算均使用 float16)后,torch.channels_last 通常被认为是卷积密集型模型的第二大性能影响因素。
需要注意的是,这仅是内部内存格式的更改——张量形状和索引方式保持不变,包括输出张量。

5. 在需要时进行图手术
如果你还不了解,torch.fx 是一个强大的 Python 工具包,用于将 PyTorch 程序(nn.Module 实例)捕获为计算图,进行分析和转换。它提供了符号追踪、基于图的中间表示(IR)以及转换工具,用于检查和优化模型计算图,适用于高级优化和分析任务,如自定义量化、剪枝、算子融合或程序分析。

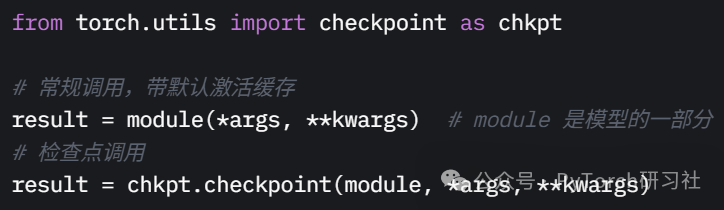
6. 使用激活检查点
简单来说,激活检查点是一种计算与内存的权衡——在前向传播中,我们执行模型的某些部分而不保存激活值;当调用 loss.backward() 时,缺失的激活值会通过重复所需的前向传播部分自动重新计算。
它不是存储反向传播所需的所有中间激活值,而是仅保存关键子集,并在反向传播期间重新计算其他部分。推理时,我们使用 torch.inference_mode() 完全禁用激活存储;即使在训练/优化期间,也可以选择性地关闭激活存储,以降低峰值内存需求。
这能让你训练更大的模型或使用更大的批次大小,牺牲一定的计算时间来换取更低的内存占用。
7. 谨慎选择优化器
在优化机器学习模型时,仅仅根据内存使用量或批次吞吐量更换优化器并非有效策略。不同优化算法的收敛速度差异巨大,足以掩盖性能上的微小差异。这体现了优化领域的一个公认原则:高级算法改进远比低级调整更具影响力。
不过,权衡总是存在的。每种优化算法可以以不同方式和精度实现。由 Tim Dettmers 开发的 bitsandbytes 库提供了 torch.optim 中多种算法的 8 位版本,通常能高效管理主机和 GPU 内存之间的状态张量。
8. 使用 cuDNN 基准测试自动调优卷积
最优的 cuDNN 卷积算法因层配置、输入大小和 GPU 硬件而异。启用基准测试模式可让 cuDNN 动态选择最佳算法,尤其在输入大小固定时,可能带来性能提升。这是因为 PyTorch 会针对遇到的特定输入大小测试多种卷积算法,并为脚本的后续执行选择最快的算法。

9. 启用异步数据加载
数据加载和预处理可能成为瓶颈,尤其是在处理大型数据集或复杂增强时。使用多个工作进程(num_workers > 0)可在 CPU 上并行加载数据,而 GPU 专注于计算。设置 pin_memory=True 能让 DataLoader 将张量复制到固定(页面锁定)内存,从而加速 CPU 到 GPU 的数据传输。

10. 优化内存使用
如果你仍在使用 PyTorch 1.X,可以通过在重置梯度时使用 set_to_none=True 选项(PyTorch 2.0 的默认行为)显著降低峰值优化内存。在训练循环中,调用 loss.backward() 和 optimizer.step() 后,需要重置梯度。可以通过 optimizer.zero_grad() 或 model.zero_grad() 实现,分别重置优化器或模型的所有参数。
为节省内存,可通过
optimizer.zero_grad(set_to_none=True)
或
model.zero_grad(set_to_none=True) 将梯度张量重置为 None,而不是更新为充满零的密集张量。这不仅节省内存,还能提升训练性能。
编写更简洁高效代码的建议
了解这些技巧是一回事,编写健壮、可维护且高效的 PyTorch 代码是另一回事。以下是我总结的一些最佳实践:
1. 清晰地组织模型
结构良好的模型更易于理解、调试和修改。
-
使用 nn.Sequential 处理简单的线性层堆叠,使用 nn.ModuleList 处理需要复杂迭代或索引的层列表。 -
对紧接批归一化的卷积层禁用偏置。如果 nn.Conv2d(包括 nn.Conv1d 和 nn.Conv3d)后直接跟 nn.BatchNorm2d,卷积层的偏置无用,可使用 nn.Conv2d(…, bias=False, …)。因为批归一化会减去均值,抵消了偏置的影响。 -
使用 torch.from_numpy(numpy_array) 或 torch.as_tensor(others)。 -
避免不必要的 CPU 和 GPU 间数据传输。 -
使用 Python 类型提示并编写清晰的文档字符串,说明输入、输出和模块/方法的功能。
2. 掌控数据流水线
数据问题是 bug 和性能不佳的常见原因。
-
在不同阶段明确检查张量形状(print(tensor.shape))或使用断言。 -
对数据集一致应用标准归一化(如减去均值、除以标准差)。 -
使用 torchvision.transforms 处理常见的图像任务。 -
严格区分训练、验证和测试集。确保验证/测试集数据不影响训练(例如,仅用训练数据计算归一化统计)。 -
始终使用前面分享的 DataLoader 优化(num_workers、pin_memory)。 -
将批次大小设为 8 的倍数,最大化 GPU 内存利用率。
3. 结构化训练循环
清晰的训练循环提升可读性和调试效率。
-
确保代码分为明确阶段:数据加载、前向传播、损失计算、反向传播、优化器步骤和指标记录。 -
显式地将模型和数据移动到正确设备(.to(device))。适用时使用 tensor.to(non_blocking=True) 重叠数据传输。 -
使用 try…except 捕获训练中的潜在问题(如 CUDA 错误、维度不匹配)。 -
使用 TensorBoard 或 Weights & Biases 等工具定期记录关键指标(损失、准确率)以可视化。
4. 系统化调试
调试深度学习模型可能很棘手。
-
先用小数据集和简化模型隔离问题,然后逐步增加复杂性。 -
若遇到不明 CUDA 错误,尝试在 CPU 上运行代码(.to(‘cpu’)),可能获得更清晰的错误信息。 -
对于 CUDA 错误,设置环境变量 CUDA_LAUNCH_BLOCKING=1,使 GPU 操作同步,立即报告错误位置。 -
使用 torch.isnan() 和 torch.isinf() 监控激活值和梯度中的 NaN 或 Inf 值。若梯度爆炸,可使用梯度裁剪(torch.nn.utils.clip_grad_norm_)。 -
为调试重现性,设置 Python、NumPy 和 PyTorch 的随机种子,并启用确定性算法。
5. 善用内置工具
-
使用 torch.profiler 识别代码性能瓶颈。 -
使用 torch.nn.init 函数(如 Xavier、Kaiming)进行适当的权重初始化,显著影响训练稳定性和速度。
总结
如果只能记住一件事,那就是:
做对一切远比做错一切好。
这些建议并非颠覆性的创新,而是“正确使用 PyTorch”的最佳实践。不同技巧对不同模型的效果不同,上述技巧并非在所有场景下都能带来性能提升。然而,只要遵循这些建议,你的代码通常会处于最佳状态。
此外,将这些特性与清晰的编码实践相结合——结构化的模型、谨慎的数据处理、有序的训练循环和系统化的调试——将为成功且可扩展的深度学习项目奠定坚实基础。
(文:PyTorch研习社)