


邮箱|huangxiaoyi@pingwest.com
4月15日,可灵AI一口气完成了全系模型的更新,可灵2.0视频生成模型及可图2.0图像生成模型正式面向全球发布,还同步推出了视频多模态编辑、图像局部重绘以及图像风格转绘三项新功能。
这也把网友们炸开了锅。
和可灵的一贯作风一样,此次模型发布即可使用。在X上,已经有大量网友开始展示使用效果了。
有人惊叹于多种风格视频的自然生成,也有人通过多模态编辑为视频更换了主角,凭借自然的效果引起了广泛的讨论。

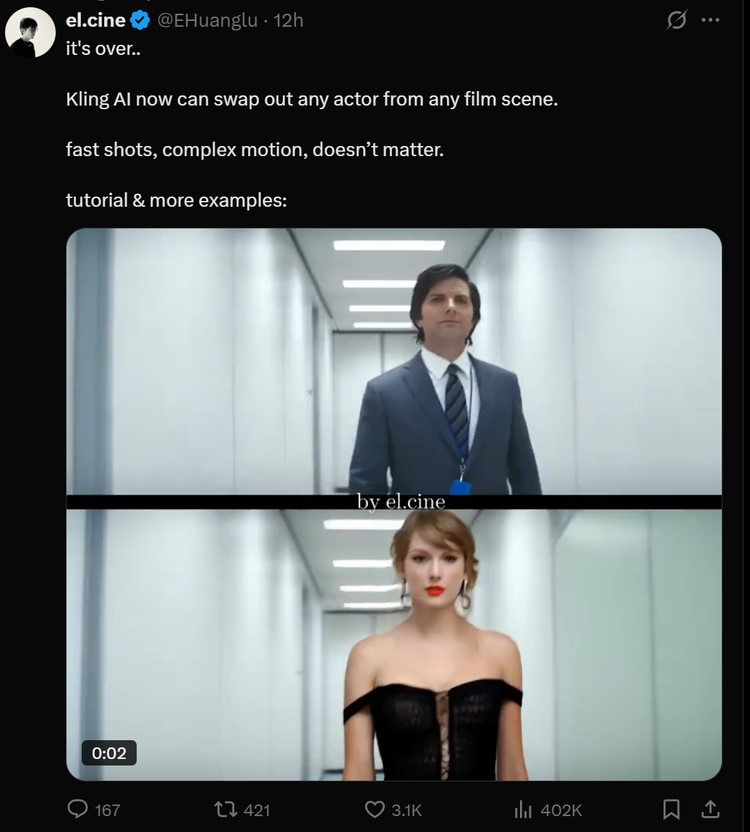
“it’s over,Kling AI 现在可以从任何电影场景中换掉演员。快速射击,复杂的动作,都不在话下了。”有网友说道。
就连马斯克本人也在X上关注了可灵AI官方账号。此前,马斯克曾评论了一则由可灵AI制作的内容,称“AI娱乐产业正飞速发展”。

不止来自用户和社交平台的反馈,数据层面上,在团队内部的多项胜负率评测中,模型也表现出了超高的领先优势。
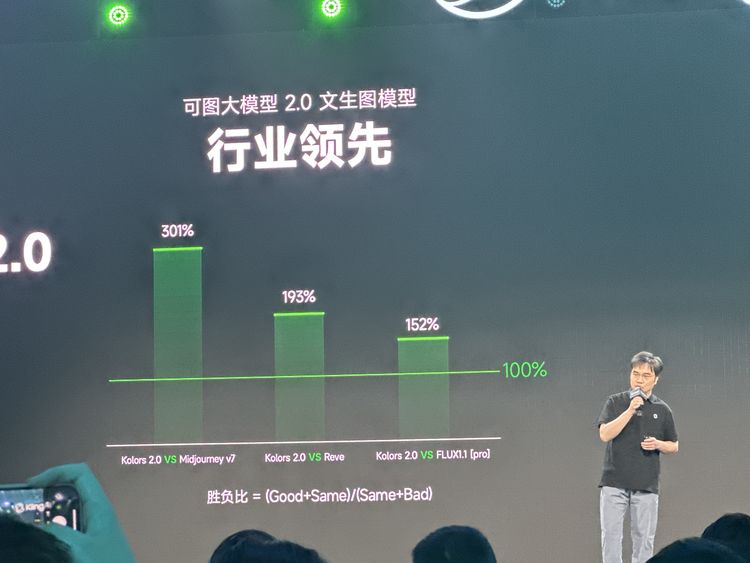
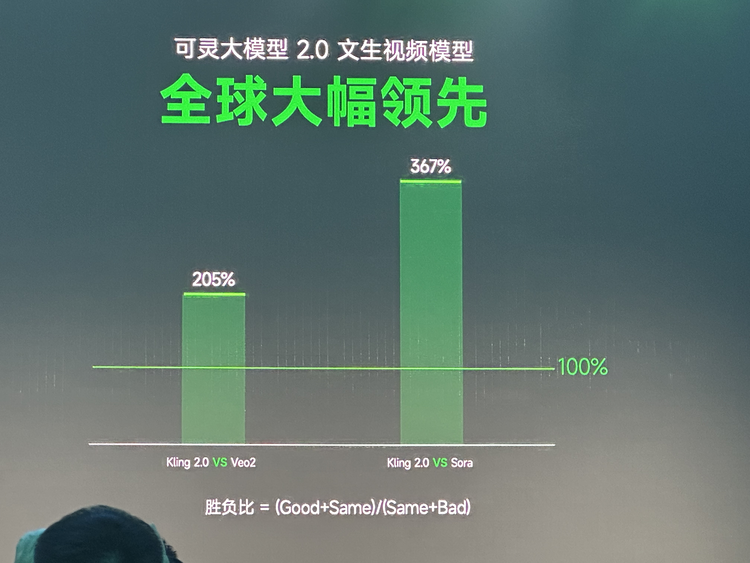
可灵2.0视频模型,对比谷歌Veo2的胜负比高达205%,而与OpenAI备受瞩目的Sora相比,更是达到惊人的367%的胜负比;在图像生成领域,可图2.0与Midjourney V7等业界公认的领先模型相比,胜负比最高超过300%。
那么,此次代际更新体现在哪里,效果到底如何?我们直接上图看看具体效果。
一连串大招,可灵全系模型迈进2.0时代
我们先看看此次更新的2个模型、3项功能分别如何。
首先是可灵2.0模型(大师版),文生视频和图生视频模型,支持首尾帧和新功能多模态编辑。单次可生成时长为5秒或10秒的视频。

以下面这则生成视频为例,一匹在草原狂奔的骏马,疾风吹过鬃毛,四腿的运动线条流畅,实感很强,即使是大幅度运动,画面也丝毫没混乱。
几乎做到了媲美真实场景的程度。相比于之前版本,可灵 2.0 的视频模型展示出了更强的语义响应、更优的动态质量和更好的画面美学。
其次,可图2.0模型在图像生成领域也有了质的飞跃,不仅提升了语义遵循能力,画面更具电影质感,还能响应近百种风格。据可灵AI披露,85%的用户都是采用的图生视频功能,图片生成的重要性不言而喻。

prompt : 电影静帧,镜头正面跟随一位身穿红色连衣裙的女子在雨中奔跑,她的头发被风吹乱,脸上混合着雨水和泪水,背景是模糊的霓虹灯光,街道湿滑反光

基础模型决定了生成效果的技术上限,可灵AI还同步推出了三项创新功能,从产品层面让视频生成更好用了。
其中,「多模态编辑」功能,允许用户通过输入图片或文字,对一段5秒的视频进行灵活的修改和再创作,可以针对用户上传的视频,替换、添加、删除元素,由此提高视频创作的可控性和迭代效率。
而可图2.0的「图片编辑」功能,则是支持对任意图片进行指定区域的局部重绘以及更自由的多尺寸扩图,效果自然,与原图高度融合。

「风格转绘」功能则让用户只需上传图片并输入风格描述,即可一键转变图像风格,轻松获得爆款效果。

从模型基础能力到功能应用层面全面突破,这意味着用户在创作全流程中的体验和最终效果都得到了提升。对创作者们而言,这是一套更加完整、强大且易用的创作工具,正在使AI创作变得更加自然、高效且富有表现力。
更稳、更美、更可控,用户能用一句话当导演?
作为全球首个用户可用的DiT视频生成模型,可灵2.0的更新受到广泛关注。
当前,视频生成模型们普遍面临着“动作幅度”与“稳定性和连贯性”难以兼顾的问题,且控制不足、创作依赖“盲盒抽卡”,画面美感难达专业水准。这些行业痛点,在可灵2.0中都得到了一定程度的优化。
首先,在基座模型能力上,可灵2.0在语义响应、动态质量和画面质感三大核心维度发生了突破。
AI创作的第一步就是理解用户创作意图,在语义响应能力方面,新版本展现出了更强的理解精度和执行力。
对比1.6与2.0版本在相同复杂提示词下的生成结果,2.0版本在动作响应上能够精准捕捉复杂肢体动作和面部微表情,每个细节都得到完美呈现,无论是捏拳的微小变化还是眼神的细微转变都能准确表达;


在运镜响应上,2.0版本成功实现了环绕运镜、跟随运镜等专业电影效果,大幅提升了视觉表现力,实现了专业级摄影效果。
在时序响应上,新模型保持了镜头内人物动作、表情和背景环境的高度连贯性和逻辑性,解决了之前版本中常见的时空跳跃问题。
动态质量方面,可灵2.0同样展现出显著优势。对比两个版本的生成结果,2.0版本在复杂动作完成度上有了质的突破,如跑酷等高难度动作展现出流畅自然的效果,物理合理性大幅提升;
运动幅度的优化让恐龙追逐等高动态场景展现出更合理且具张力的运动范围,大大增强了画面的沉浸感;
运动速度的调整则有效解决了慢动作问题,视频展现出更符合物理规律的真实速度感,让动态表现更加自然。
在画面美学层面,可灵2.0全方位提升了视觉表现力。对比此前的模型,新版本的视觉表现更具专业质感,呈现出电影级的画面品质,色彩和光影效果更为高级,整体美感显著提升;
细节刻画更加丰富,场景和人物细节更加精致,视觉信息更加丰富;
风格保持能力也大幅增强,从原始图像到生成视频,风格一致性更高,让创作者能够更精准地控制视觉风格。
在这些基础模型效果的突破上,可灵也搭配了功能层面的「多模态编辑」功能,重新定义了人与AI交互的方式。
正如快手高级副总裁盖坤所指出的:“文字作为表达媒介存在局限,无法完美描述人脑中的复杂影像。即使最精确的文字描述也难以完美传达脑海中的视觉想象。”
为解决这一问题,此次可灵2.0提出了名为Multi-modal Visual Language(MVL)的多模态视觉语言,核心理念是通过多模态信息的组合,来精准表达人脑中的想象,打破纯文本表达的局限。
在MVL体系中,存在两类关键元素:一是TXT(Pure Text,语义骨架);二是MMW(Multi-modal-document as a Word,多模态描述子),将多模态信息如图像、视频片段等作为“单词”嵌入到语义骨架中,共同构建完整的创作指令。
例如,用户可以指定一个人物图像作为主角外貌参考,另一张图像作为服装参考,第三张图像作为场景参考,再通过文本描述动作和情绪,最终生成一段完全符合预期的视频。
这种结合了自然语言描述与多模态参考的表达方式,大幅提升了创作指令的精准度,让AI更能理解创作者心中真正的想象。
多模态编辑功能可以说是此前多图参考的迭代,进一步对齐了文本语言、图片语言和视频语言,让不同类型的创作素材能够和谐共存于同一创作指令中。据快手透露,未来MVL还将扩展至声音、动作描述文件等更多模态。
更强的基础模型能力+更灵活可控的产品功能,对创作者们而言,可灵2.0让视频生成变得更加真实可用了。
刚刚拿下“全球第一”的可灵,如何保持领先?
去年可灵AI1.0发布上线,吹响了整个视频生成赛道的起跑哨,此后始终保持着综合效果的领先状态。
从客观数据来看,3月27日,全球知名AI基准测试机构Artificial Analysis发布的最新全球视频生成大模型榜单中,快手可灵1.6pro(高品质模式)以1000分的Arena ELO基准测试评分登顶图生视频(Image to Video)赛道榜首,将Google Veo 2、Pika Art等知名产品分别挤至第二、三名的位置。
除了专业榜单的认可,可灵在用户规模上同样表现亮眼。自去年6月正式发布以来,可灵AI已累计完成超过20次迭代,目前全球用户规模已突破2200万,增速迅猛。
这些成绩的背后,是可灵团队对产品持续迭代更新的坚持,不到一年时间经历了20多次迭代,以及对用户真实需求的深入洞察。
这种需求的洞察,首先体现在视频生成不是技术自嗨,而是围绕着用户的创作需求,能够尽可能地被用起来,因此,可灵从1.0开始就保持着模型发布,用户即可用。
无论是,可灵1.0上线后迅速掀起了一阵老照片修复潮,“老照片动起来”的创意作品风靡各大社交平台,还是此次2.0通过更强大的生成能力和更实用的交互方式,进一步降低了创作门槛,发布即可用,也意味着从生成技术到生成产品,可灵的每一步进化都能够建立在用户实际反馈的基础上。
此外,为了让可灵AI能够被更广泛的创作者应用,快手还构建了完整的生态支撑体系。
一方面,可灵AI面向开发者和企业提供API接入等服务,目前,已与包括小米、亚马逊云科技、阿里云、Freepik、蓝色光标等在内的数千家国内外企业展开合作关系。数据显示,来自世界各地的超过1.5万开发者已将可灵的API应用于不同的行业场景中,累计生成的图像数量约1200万个,生成的视频素材超过4000万个。
另一方面,在广大C端用户层面,可灵AI也构建起了AIGC创作-消费生态。从《山海奇镜之劈波斩浪》到《新世界加载中》等备受关注的AI剧作,都展示了AI在内容创作领域的无限可能。
可灵AI超级创作者、《新世界加载中》总导演、异类Outliers创始人陈翔宇提到,“我们实践之后发现,可灵AI是一个能够稳定、大规模嵌入剧集创作流程的生成式协作大模型。”陈翔宇认为,在AI的辅助下,导演及编剧团队的大量内容创意也实现了更富有想象力的表达,AIGC相较于实拍和动画,不仅是效率的提升,更是试错空间的革命性释放。
在此次产品更新的同时,快手也推出了“可灵AI NextGen 新影像创投计划”,进一步加大对AIGC创作者的扶持力度,通过千万资金投入、全球宣发、IP打造和保障,以全资出品、联合出品和技术支持等灵活多样的合作方式,让AI好故事走向世界。
持续的技术创新、实用的产品迭代和丰富的生态建设,对视频生成发展而言,缺一不可,这也是快手保持优势的原因所在。
正如快手高级副总裁、社区科学线负责人盖坤所言:“我们的初心,是让每个人都能用AI讲出好的故事。”借助AI的力量,让更多人能够轻松表达自己的创意,讲述属于自己的故事的那一天,也许并不遥远。


(文:硅星人Pro)