

STI-Bench团队 投稿
量子位 | 公众号 QbitAI
多模态大语言模型(MLLM)在具身智能和自动驾驶“端到端”方案中的应用日益增多,但它们真的准备好理解复杂的物理世界了吗?
上海交通大学联合中国地质大学、南洋理工大学、智源研究院以及斯坦福大学的研究团队推出首个多模态大模型(MLLM)时空智能评测基准STI-Bench(Spatial-Temporal Intelligence Benchmark),向当前最先进的多模态大语言模型发起了关于精确空间时间理解的严峻挑战。
结果显示,即便是Gemini-2.5-Pro、GPT-4o、Claude-3.7-Sonnet、Qwen 2.5 VL等当前最强的多模态大模型,在需要定量分析真实世界空间关系和动态变化的任务上,表现并不尽人意。

从语义理解到时空智能
MLLM在视觉语言理解上成就斐然,并被寄望于成为具身智能和自动驾驶的“端到端”解决方案。但这要求模型超越传统的语义理解,具备精准的时空智能。
试想AI应用场景中的需求:
- 自动驾驶:
需知晓与前车的精确距离(米)、行人过马路的速度(米/秒)、安全过弯的车速限制等。 - 机器人操作:
需判断目标物体的尺寸位置(毫米级)、物体间的空间布局、高效的抓取路径与速度。
这些任务的核心是定量化的空间-时间理解能力,而这恰恰可能是当前大模型能力的薄弱环节。STI-Bench正是为了系统评估这一关键能力而生。
STI-Bench:”时空智能”的全面基准测试
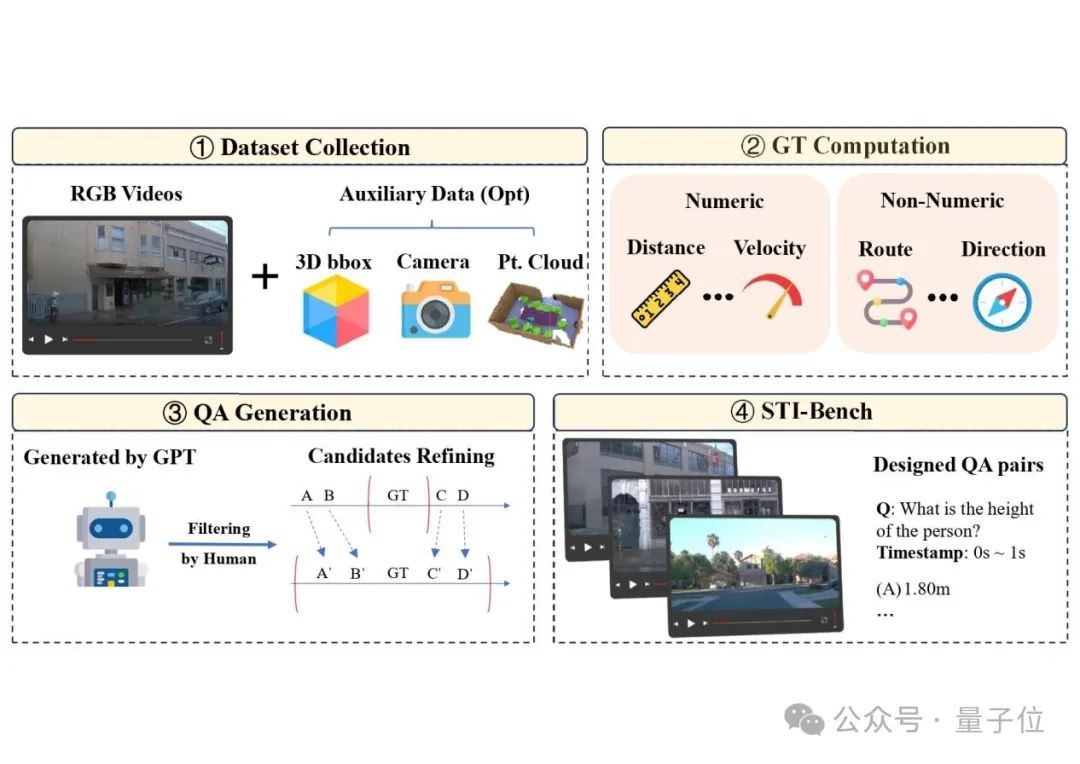
与现有侧重语义的评测不同,STI-Bench直接采用真实世界视频作为输入,聚焦于精确、量化的时空理解,旨在评估模型在真实应用场景中的潜力。
基准构建
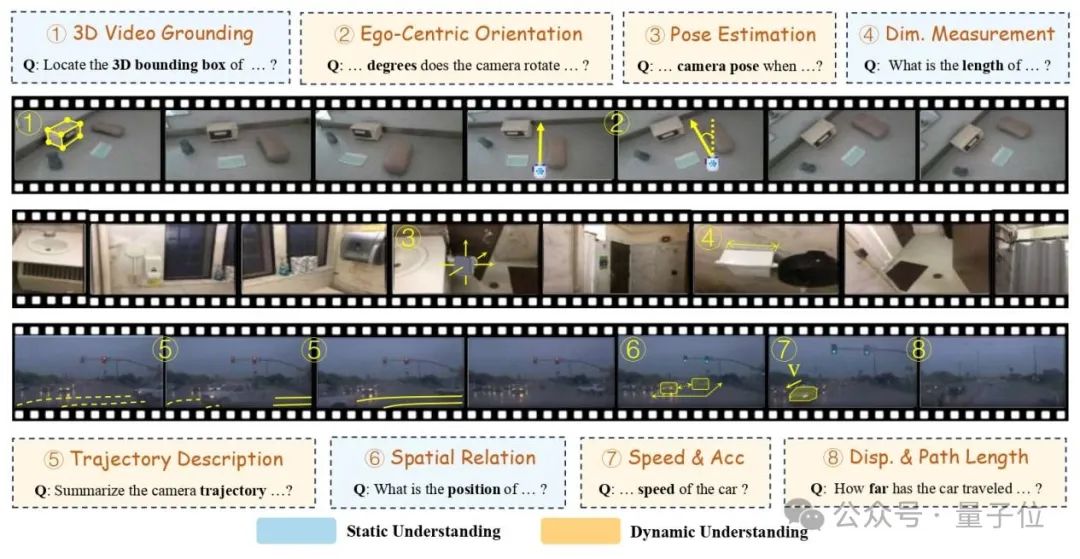
数据来源包括300多个真实世界视频,覆盖三类典型场景:桌面操作(毫米级)、室内环境(厘米级)、户外场景(分米级)。
评测任务共八项,分属两个维度。第一类是静态空间理解,包括:(1)尺度度量,评估物体大小和物体之间的距离;(2)空间关系,理解物体的相对位置关系;(3)3D视频定位,预测物体在三维空间中的位置框。第二类是动态时序理解,包括:(4)位移与路径长度,判断物体运动距离;(5)速度与加速度,分析物体运动的快慢及其变化趋势;(6)自我中心方向,估计相机的旋转角度;(7)轨迹描述,概括物体运动路径;(8)姿态估计,识别相机或物体在运动过程中的姿态变化。
此外,该数据集还包含2000多对高质量问答(QA),所有问答基于精确标注计算真值,采用GPT-4o生成多样化问题与答案,并经过多轮人工审核与校准,确保问答内容准确、语言合理、且与对应场景的精度需求高度匹配。
实验结果
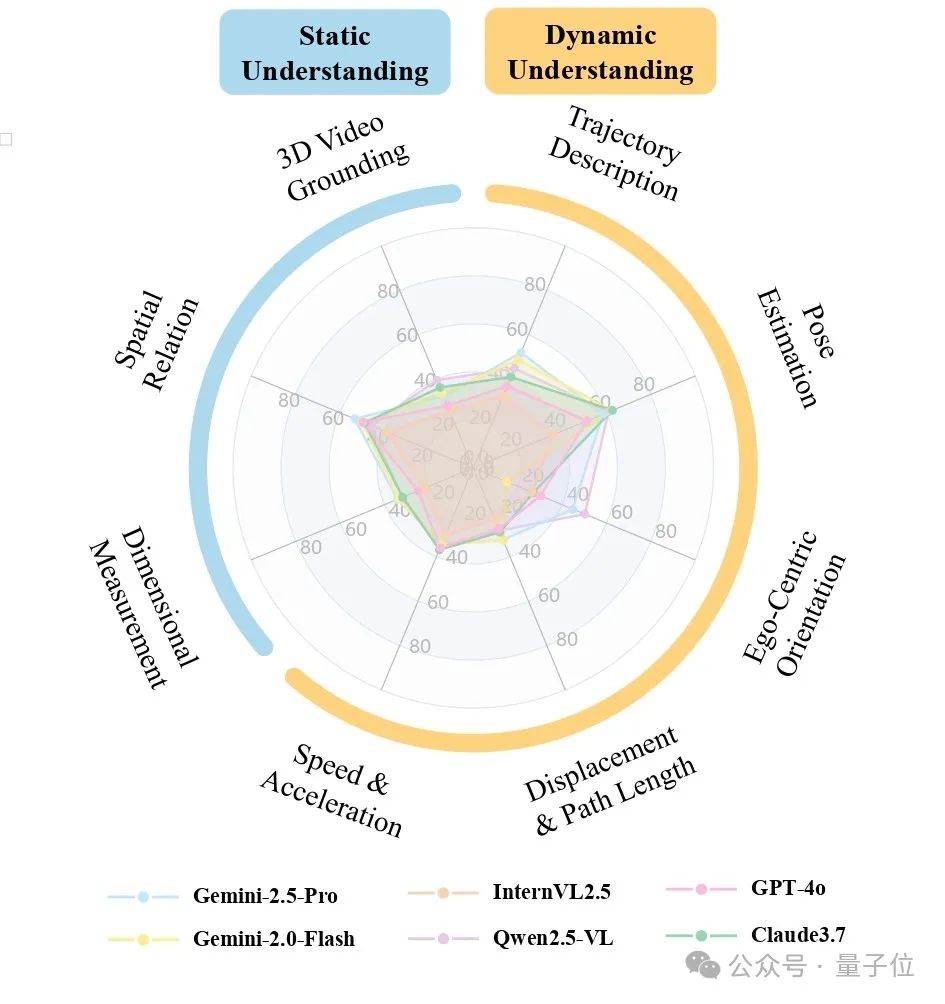
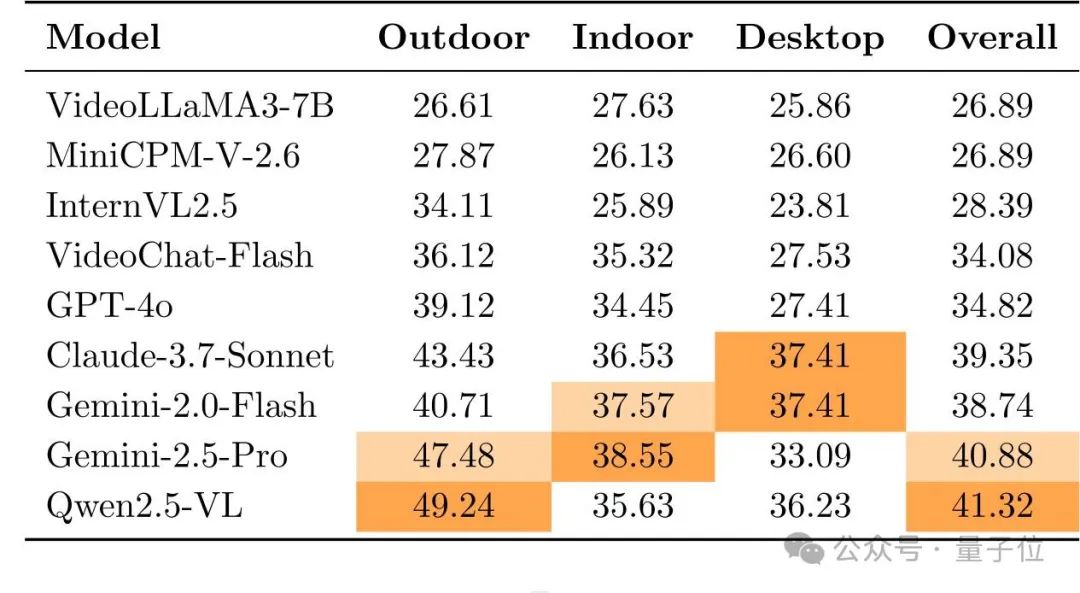
研究团队对当前最先进的多模态模型进行了全面评测,包括最强的专有模型(GPT-4o、Gemini-2.0-Flash、Gemini-2.5-Pro、Claude-3.7-Sonnet)和知名开源模型(Qwen2.5-VL-72B、InternVL2.5-78B、VideoLLaMA 3等)。
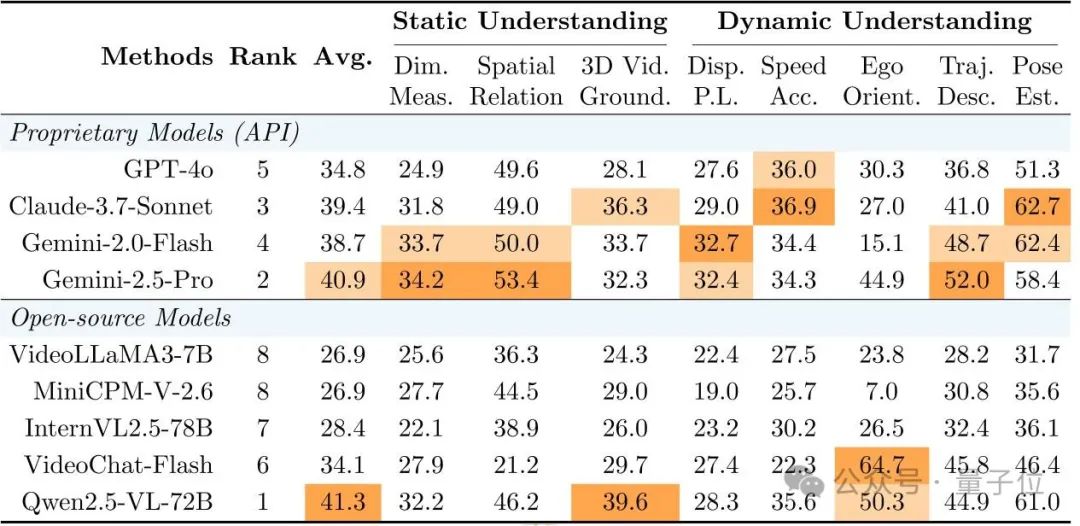
评测结果令人感到担忧:
整体表现不佳:表现最好的Qwen2.5-VL-72B和Gemini-2.5-Pro也仅不到42%的准确率,仅比随机猜测(20%)高一些,距离实际应用所需的可靠性还有天壤之别。
定量空间任务成”重灾区”:
-
尺度度量:最高仅34.2%(Gemini-2.5-Pro) -
位移路径长度:最佳成绩不到33% -
速度与加速度:最高仅36.9%
场景差异明显:
-
所有模型在户外场景表现相对较好(最高约50%) -
在对精度要求更高的室内场景和桌面环境中普遍下降(均低于40%)
开源模型崭露头角:
Qwen2.5-VL-72B不仅赢过所有开源对手,甚至击败了所有专有模型,为开源社区带来振奋。
错误原因分析
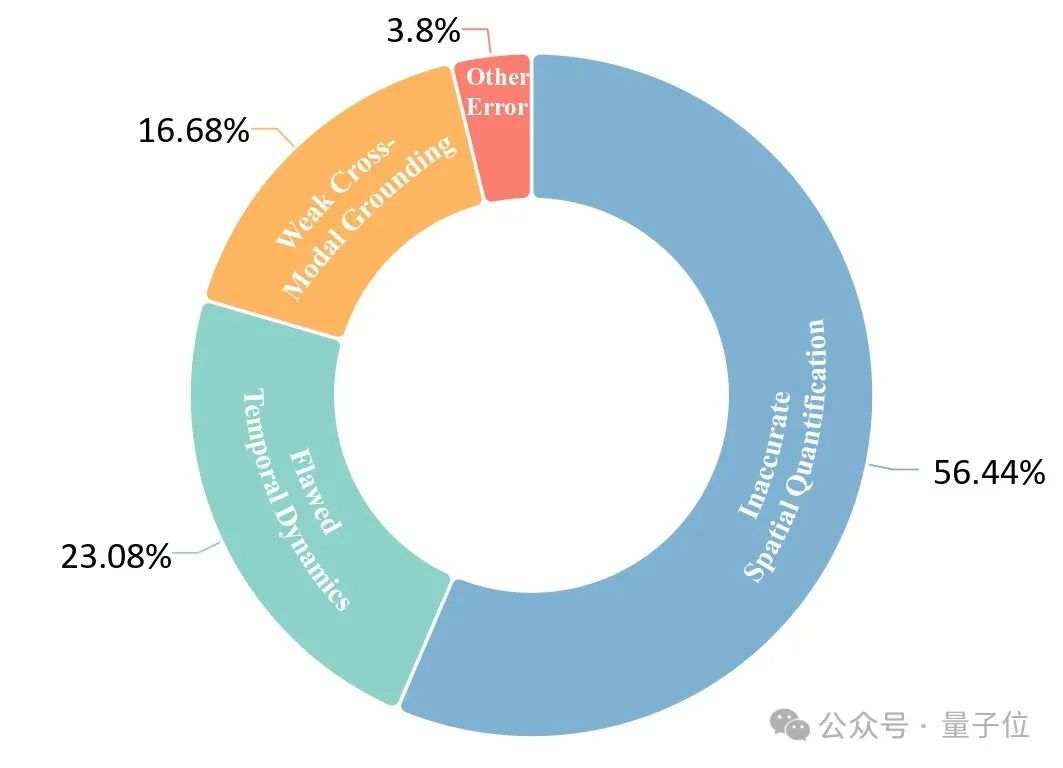
为了揭示大模型在空间-时间理解上失败的根本原因,研究者对Gemini-2.5-Pro在各个场景下各类任务的思考过程进行了详细错误分析,发现了三大核心瓶颈:
1. 定量空间属性不准确
模型往往难以通过单目视频准确估计视觉输入中物体的空间属性,如尺寸、距离,以及无法从视频中推断3D信息,影响了所有需要精确空间测量的任务。
2. 时间动态理解缺陷
模型在理解随时间变化的跨帧信息方面表现不佳,难以准确计算和描述运动特征如位移、速度和轨迹。尤其难以区分物体运动与相机运动,这些问题源于跨帧信息整合困难和物理先验的缺失。
3. 跨模态整合能力薄弱
模型无法有效结合理解文本指令与视觉内容,整合非视觉数据与视觉信息。这导致对时间约束的误解、给定初始条件等使用不当,以及结构化数据,如坐标、姿态等与视觉元素的正确关联,影响所有依赖多模态信息的任务。
这些问题直指当前MLLM在精准的空间-时间理解上的能力缺陷,也为未来研究指明了方向。
总结
STI-Bench的结果清晰地揭示了当前多模态大模型在精确空间-时间理解方面的严重不足。只有当MLLM掌握了可靠、精确的空间-时间理解能力,它们才能在具身智能和自动驾驶等领域发挥真正的价值,迈出从虚拟世界到物理世界的关键一步。
STI-Bench的发布,为评估和改进MLLM的空间-时间理解能力提供了一个新的基准和“试金石”,有望引导研究人员更深入地探索解决方案。
目前,该项目的论文、代码、数据等已经开源。
论文链接: https://arxiv.org/pdf/2503.23765
论文主页: https://mira-sjtu.github.io/STI-Bench.io/
Github: https://github.com/MIRA-SJTU/STI-Bench
Huggingface: https://huggingface.co/datasets/MIRA-SJTU/STI-Bench
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

🌟 点亮星标 🌟
(文:量子位)