
项目简介
Spark-TTS 是一个先进的文本到语音系统,它利用大型语言模型(LLM)的力量,实现高度准确和自然的声音合成。它旨在高效、灵活且强大,适用于研究和生产使用。
关键特性
-
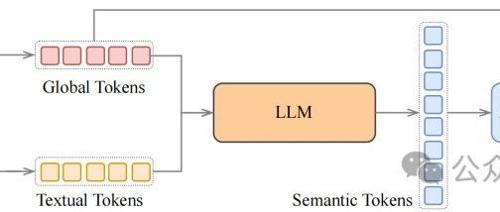
简洁与高效:Spark-TTS 完全基于 Qwen2.5 构建,消除了对额外生成模型如流匹配的需求。它不再依赖单独的模型来生成声学特征,而是直接从LLM预测的代码中重建音频。这种方法简化了流程,提高了效率并降低了复杂性。 -
高质量语音克隆:支持零样本语音克隆,这意味着即使没有针对该语音的特定训练数据,也能复制说话者的声音。这对于跨语言和代码切换场景非常理想,可以实现语言和声音之间的无缝切换,无需为每种语言进行单独训练。 -
双语支持:支持中文和英语,并能够实现跨语言和代码切换场景的零样本语音克隆,使模型能够以高自然度和准确性合成多种语言的语音。 -
可控语音生成:支持通过调整性别、音调和说话速度等参数来创建虚拟说话者。
| Inference Overview of Voice Cloning 语音克隆推理概述  |
| Inference Overview of Controlled Generation 受控生成的推理概述 |
安装
克隆并安装
下面是 Linux 安装的说明。如果您使用的是 Windows,请参阅 Windows 安装指南。
(感谢@AcTePuKc 提供的详细 Windows 安装说明!)
-
克隆仓库
git clone https://github.com/SparkAudio/Spark-TTS.gitcd Spark-TTS
-
安装 Conda:请参阅 https://docs.conda.io/en/latest/miniconda.html -
创建 Conda 环境:
conda create -n sparktts -y python=3.12conda activate sparkttspip install -r requirements.txt# or:pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
模型下载
Download via python: 使用 Python 下载:
from huggingface_hub import snapshot_downloadsnapshot_download("SparkAudio/Spark-TTS-0.5B", local_dir="pretrained_models/Spark-TTS-0.5B")
使用 git clone 下载:
mkdir -p pretrained_models# Make sure you have git-lfs installed (https://git-lfs.com)git lfs installgit clone https://huggingface.co/SparkAudio/Spark-TTS-0.5B pretrained_models/Spark-TTS-0.5B
基本用法
您可以使用以下命令简单地运行演示:
cd examplebash infer.sh
或者,您可以直接在命令行中执行以下命令进行推理:
python -m cli.inference \--text "text to synthesis." \--device 0 \--save_dir "path/to/save/audio" \--model_dir pretrained_models/Spark-TTS-0.5B \--prompt_text "transcript of the prompt audio" \--prompt_speech_path "path/to/prompt_audio"
Web UI 使用方法
您可以通过运行 python webui.py --device 0 启动 UI 界面,这允许您进行语音克隆和语音创建。语音克隆支持上传参考音频或直接录音。
| Voice Cloning 语音克隆 | Voice Creation 语音创建 |
|---|---|
|
|
|
可选方法
关于额外的 CLI 和 Web UI 方法,包括替代实现和扩展功能,您可以参考:
-
AcTePuKc 的 CLI 和 UI
运行时
Nvidia Triton推理服务
我们现在提供了一份使用 Nvidia Triton 和 TensorRT-LLM部署 Spark-TTS 的参考。下表展示了在单个 L20 GPU 上,使用 26 个不同的 prompt_audio/target_text 对(总计 169 秒音频)的基准测试结果:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
请参阅 runtime/triton_trtllm/README.md 中的详细说明以获取更多信息。
项目链接
https://github.com/SparkAudio/Spark-TTS
扫码加入技术交流群,备注「开发语言-城市-昵称」
(文:GitHubStore)