
Search-R1:高效、可扩展的强化学习训练框架,用于训练具有推理和搜索引擎调用能力的大型语言模型(LLM)。亮点:
-
基于veRL构建,支持3B规模的基础LLM;
-
通过规则化奖励机制,让LLM自主学会推理和搜索;
-
提供完整的训练流程和工具支持,助力研究和开发。


参考文献:
[1] http://github.com/PeterGriffinJin/Search-R1
(文:NLP工程化)
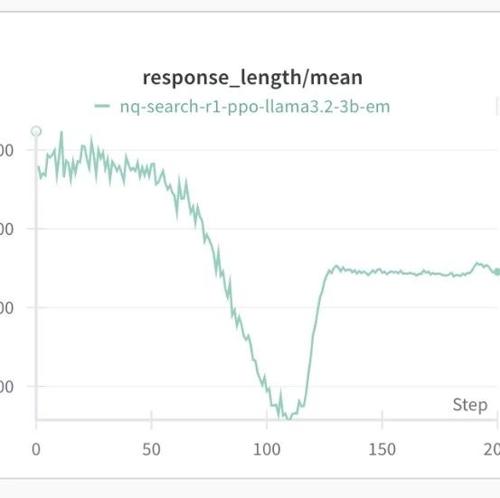
Search-R1:高效、可扩展的强化学习训练框架,用于训练具有推理和搜索引擎调用能力的大型语言模型(LLM)。亮点:
基于veRL构建,支持3B规模的基础LLM;
通过规则化奖励机制,让LLM自主学会推理和搜索;
提供完整的训练流程和工具支持,助力研究和开发。
参考文献:
[1] http://github.com/PeterGriffinJin/Search-R1
(文:NLP工程化)