

背景:
OpenAI 和Google DeepMind 先后(或者是后先)在2025 IMO 中获得金牌成绩后,多伦多大学数学助理教授Daniel Litt 抛出了一个有趣的问题:
那些在2025年国际数学奥林匹克竞赛(IMO)中获得金牌的AI模型,面对第6题时到底发生了什么?
这个问题看似简单,实则触及了AI 应用于数学研究的一个核心困境。
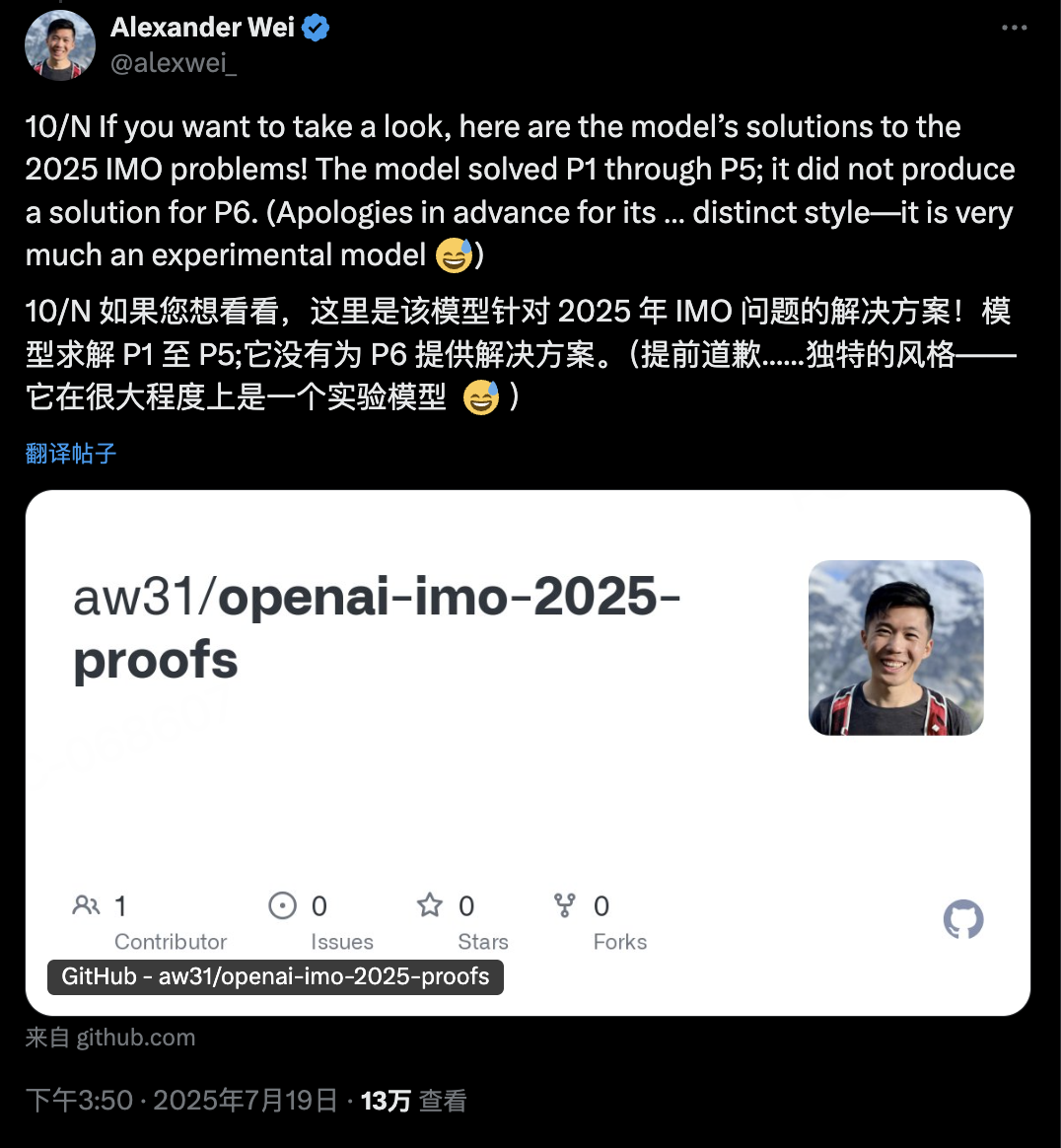
事情的起因是OpenAI的Alexander Wei分享了他们模型在IMO竞赛中的表现:成功解决了前5道题,但在第6题上“没有产生解答”。
这个措辞很是微妙。
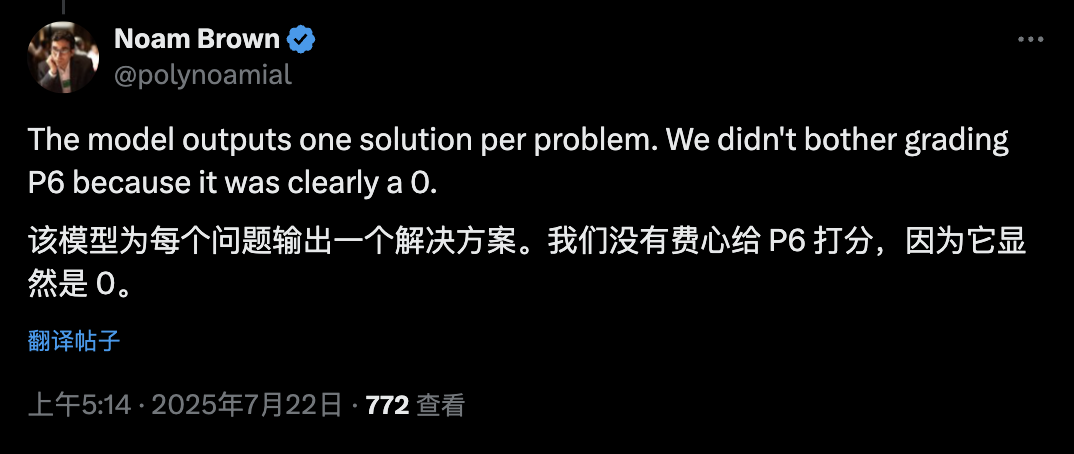
后来真相浮出水面——
OpenAI的Noam Brown澄清道:模型确实为第6题输出了一个解答,但这个解答明显错误,甚至不值得评分。
为什么这个细节如此重要?
要理解这一点,需要先了解一个背景:检查数学证明的正确性极其困难且耗时。
Litt教授曾详细讲述过,即使是精心撰写的数学论文,要仔细检查其正确性也是一项艰巨的任务。
想象一下,如果一个工具能解决困难的数学问题,但同时也会对无法解决的问题给出错误答案,会发生什么?
它可能最终成为一个生产力黑洞。
更糟糕的是,如果它成功愚弄了用户,可能会导致错误的数学主张被广泛传播。
这种担忧已经开始变成现实。
自今年6月15日以来,在arXiv上提交的包含“Hodge猜想”标题或摘要的9篇论文中,有7篇都是无意义的。
而这些论文几乎都是在大语言模型的辅助下写成的。
目前,识别这些论文的谬误还相对容易(只需要专业人士几分钟时间)。
但随着AI能力的提升,这将变得越来越困难。
我们可能很快就无法再相信arXiv上随机选择的数学论文了。
而更令人担忧的是一个趋势:AI 工具产生难以检查、令人信服的数学散文的能力,可能会比产生正确答案的能力发展得更快。
这意味着,我们可能很快就会看到大量看起来极具说服力,但实际上完全错误的数学结果涌现。这些结果可能会以学术论文的形式出现,混杂在真正的研究成果之中,让人难以分辨。
当然,形式化验证(如使用Lean等工具)理论上可以帮助解决这个问题。
但现实是残酷的:在许多数学领域,任何形式的形式化验证都还很遥远。
如在相关讨论中提到的,在某些研究领域进行形式化验证需要巨大的工作量:至少需要几个世纪的人年工作时间。
虽然希望AI能够在这方面提供帮助,但目前看来,这仍然是一个遥远的目标。
这或许也正是悖论的本质:当AI 变得足够强大,能够产生看似合理的数学论证时,验证这些论证的正确性反而变得更加困难。

数据科学家Christopher D. Long 也指出:如果AI持续产生有缺陷的证明并编造参考文献,它将成为一个净负面因素。新颖的数学研究需要知识、创造力、长期规划、可行性评估,以及至关重要的——对正确性的理解。

回到最初的问题:
如果这些模型在IMO竞赛中没有为第6题提交错误答案,那对AI在数学领域的近期应用来说是一个相当积极的信号。但如果它们确实提交了错误答案……
这个看似微小的细节,实际上可能决定了未来AI 在数学研究中究竟会是助力还是阻力。
Daniel Litt 推文: https://x.com/littmath/status/1947398065209462981
(文:AGI Hunt)