

美团团队 投稿
量子位 | 公众号 QbitAI
多模态推理,也可以讲究“因材施教”?
来自美团的研究者们提出Metis-RISE框架(RL Incentivizes and SFT Enhances),探索了这一方法。
他们提出了一个混合训练框架,将RL激励和SFT增强以非传统顺序结合,更有效地提升多模态大语言模型(MLLMs)的推理能力。

简单来说,就是先用强化学习(RL)放任模型大胆去探索,激发潜能,再通过监督微调(SFT)针对性补齐短板,来突破多模态推理瓶颈。
最终产生7B和72B参数的MLLM,2个模型在OpenCompass多模态推理榜单上取得了优异成绩,其中72B参数模型平均得分在整体排名中位列第四,验证了Metis-RISE的可扩展性和有效性。
突破传统训练范式,激活模型潜在推理能力
当前多模态推理大模型训练范式面临双重挑战:
纯RL:一方面正确轨迹采样成功率波动大(0-1),另一方面不能“无中生有”,受限于基座模型的能力上限
先SFT后RL:早期监督训练禁锢模型创造力,如同给AI“套上枷锁”,后期RL探索空间受到限制
这些恰是Metis-RISE破局之处,如下图所示,与从冷启动SFT阶段开始的传统流程不同,团队方法基于经验观察省略了这一初始步骤,直接从使用Group Relative Policy Optimization(GRPO)算法变体的RL训练开始。
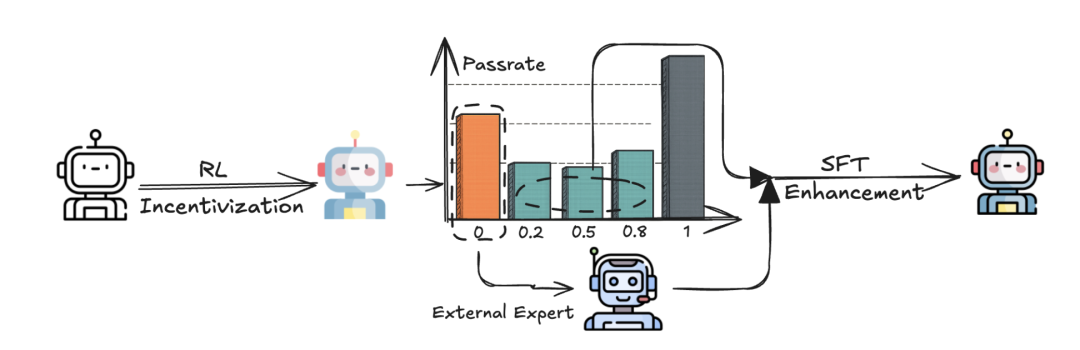
方法分为2步走:
阶段1:强化学习激励
采用改进版GRPO算法,通过比较同一查询生成的候选输出组来估计模型生成响应的优势。
允许模型大胆“放飞自我”,将取消KL散度约束、在线数据过滤、非对称耦合、token级策略损失和软过长惩罚应用于多模态学习,增强GRPO训练过程的稳定性和有效性。
关键机制:非对称裁剪+动态数据过滤,避免无效探索
阶段2:SFT对症下药
Metis-RISE中的SFT阶段通过一个精心策划的数据集,策略性地增强模型:
自我蒸馏推理轨迹:团队使用RL训练的模型在prompt数据池中进行k-shot轨迹采样。对于模型推理表现不一致的prompt(轨迹正确性得分严格在0和1之间),使用模型自身的正确推理轨迹作为监督信号。这强化了模型可以发现但尚未可靠执行的推理路径,以解决采样效率低下问题。
专家增强知识注入:对于模型始终无法成功处理的prompt(所有尝试中轨迹正确性得分为0),团队推断其缺乏必要的推理能力。在这种情况下,一个更强的外部推理专家会生成高质量的轨迹。这些专家生成的解决方案随后用于增强SFT数据集,有效注入新知识并弥补模型的原始能力缺陷。
成绩亮眼,72B模型OpenCompass排名第四
团队基于开源的Qwen2.5-VL系列进行开发,采用结合RL激励和SFT增强的两阶段训练方法,训练了两个模型变体:Metis-RISE-7B和Metis-RISE-72B。
为了全面评估模型性能,团队采用了VLMEvalKit,并在OpenCompass多模态推理排行榜上进行基准测试。
团队将Metis-RISE与专有模型、开源≤10B模型、开源>10B模型,这三类最先进模型进行比较,如下图所示。
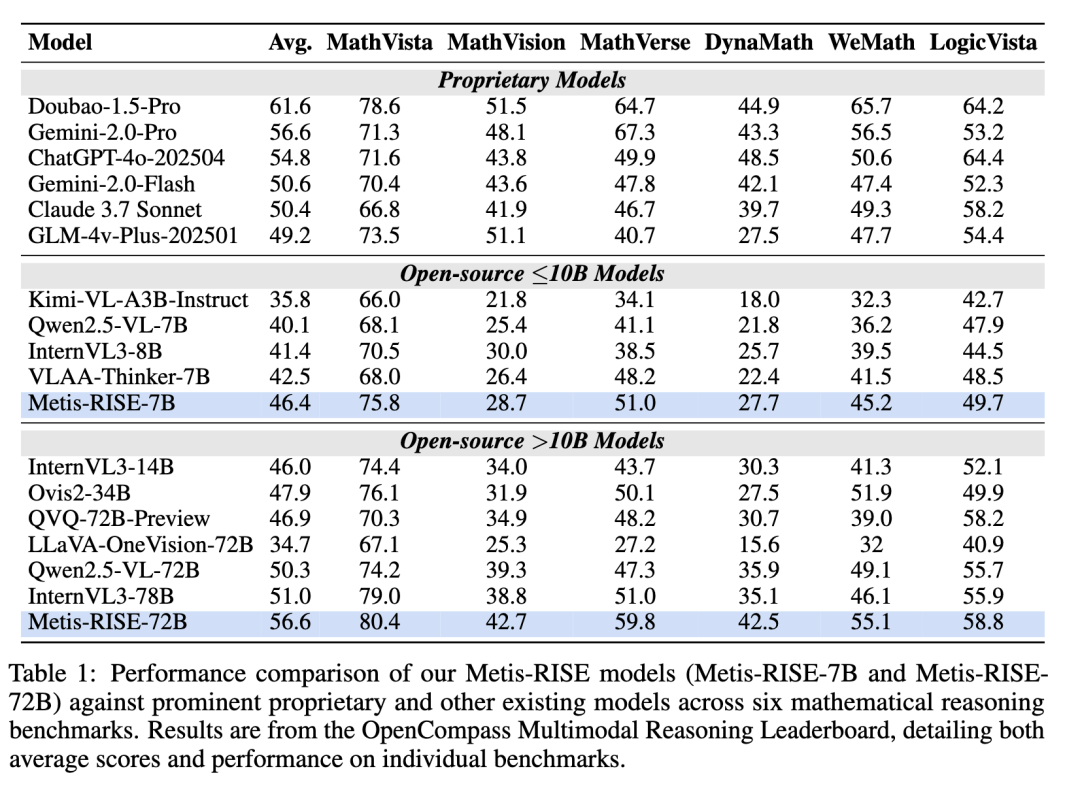
结果显示,Metis-RISE-7B模型在≤10B参数类别中表现出色,平均得分为46.4。这一结果超越了所有同等规模的模型,包括VLAAThinker-7B(42.5)和InternVL3-8B(41.4),确定了Metis-RISE-7B在这些基准上的水平最先进。
Metis-RISE-72B平均分数为56.6,使其成为>10B参数类别中表现最佳的模型。它显著优于其他大模型如InternVL3-78B(51.0)和Qwen2.5-VL-72B(50.3)的表现,这进一步展示了团队方法的强大优势。
值得注意的是,Metis-RISE-72B的性能具有很强的竞争力,并且在某些情况下超过了著名的专有模型。例如,Metis-RISE-72B超过了ChatGPT4o-202504(54.8)和Claude3.7Sonnet(50.4),同时与Gemini-2.0-Pro(56.6)的性能相当。
综合来看,这些优异的结果使得Metis-RISE-72B在本次评估时在OpenCompass多模态推理排行榜上位列第四,突显了它在复杂多模态推理任务中的先进能力。
消融实验
下图展示了Metis-RISE-7B进行的详细消融研究,细致地说明了Metis-RISE框架中每个阶段的不同影响和协同贡献。基准模型(Qwen2.5-VL-7B)在评估数据集上取得了39.2分的初始平均分数。在应用初始RL阶段(基准→RL)后,平均分数增加到44.0分(+4.8分),性能显著提升。
这一巨大进步突显了RL在激励模型探索能力方面的关键作用,鼓励模型发现并激活潜在的正确推理路径。这种效果在WeMath等具有挑战性的数据集上尤为明显,分数从36.2跃升至43.3,在DynaMath上则从21.8提升至26.2,展示了RL解锁推理潜力的能力。
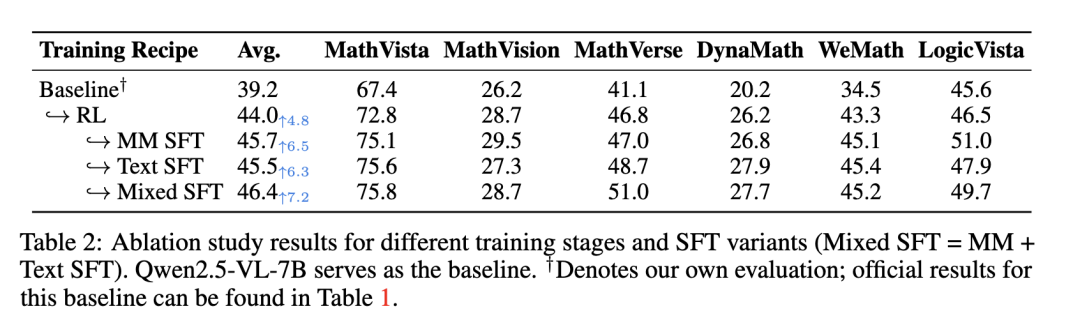
同时,所有SFT变体在RL增强基线(平均得分为44.0)之上都带来了性能提升。具体来说,在RL阶段之后应用多模态图文SFT,平均得分进一步提高了1.7分(从44.0提高到45.7),而纯文本SFT导致得分增加了1.5分(达到45.5);混合数据SFT方法取得了最佳结果,在RL增强模型上平均得分提高了2.4分,达到46.4。这一额外提升突显了SFT在精炼和巩固RL揭示和激活的推理能力方面的有效性。
定性分析
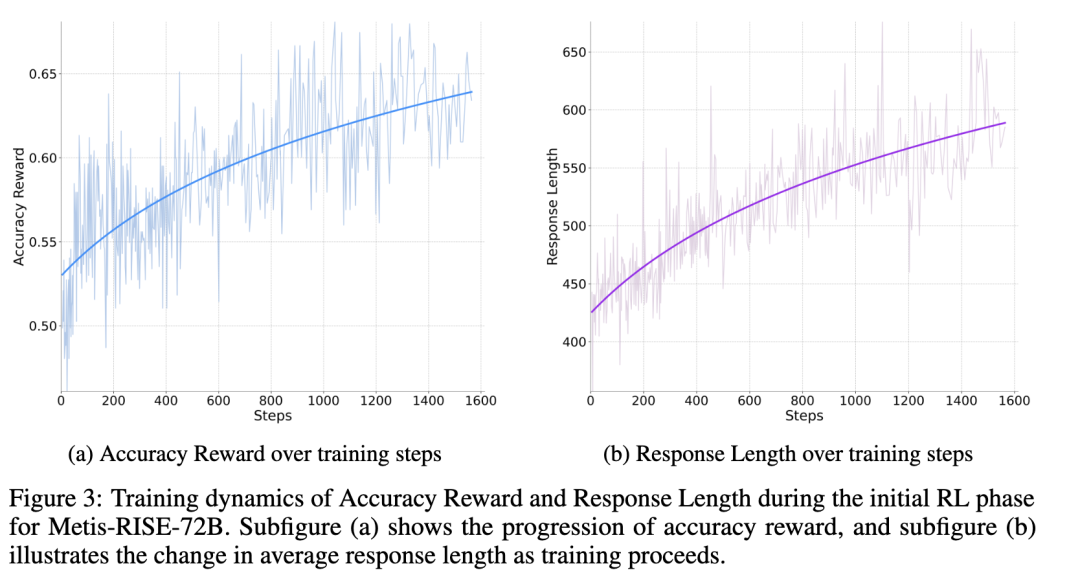
在Metis-RISE-72B模型的初始强化学习(RL)阶段,团队观察到准确率奖励和响应长度方面的显著趋势。
具体来说,下图展示了随着训练的进行,准确率奖励持续且稳定地增加。同时,揭示了模型响应平均长度的相应上升趋势,即RL阶段模型输出长度持续增长,思维链逐渐清晰。
团队表示,在后续研发工作中,将继续探索RL和SFT的循环迭代应用,实现推理能力的持续改进,并开发基于模型的验证器,扩展Metis-RISE在更复杂推理场景中的应用。
论文地址:
https://arxiv.org/pdf/2506.13056
项目主页:
https://github.com/MM-Thinking/Metis-RISE
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)