

 关注我,记得标星⭐️不迷路哦~
关注我,记得标星⭐️不迷路哦~
✨ 1: dots.llm1
dots.llm1:142B参数MoE大模型,开源中间训练检查点

dots.llm1 是一个大规模混合专家 (MoE) 模型,其主要功能、核心要点和关键特性如下:
- 大规模MoE模型:
该模型激活了140亿参数,总参数量达到1420亿,在性能上可与最先进的模型相媲美。 - 高效的数据处理:
采用精心设计的高效数据处理流程,在11.2T高质量tokens上进行预训练,性能可与Qwen2.5-72B媲美,且未使用合成数据。 - 开放模型动态:
开源了每训练1万亿个tokens的中间训练检查点,为研究大型语言模型的学习动态提供了宝贵的见解。 - 增强的数据处理:
提出了一种可扩展的、精细的三阶段数据处理框架,旨在生成大规模、高质量和多样化的预训练数据。 - 无合成数据预训练:
在基础模型预训练中使用了11.2万亿高质量非合成tokens。 - 性能和成本效益:
dots.llm1是一个开源模型,在推理时仅激活 140 亿个参数,从而提供全面的功能和高计算效率。 - 基础设施:
引入了一种创新的MoE all-to-all通信和计算重叠方法,该方法基于交错的1F1B流水线调度和高效的分组GEMM实现,以提高计算效率。
地址:https://github.com/rednote-hilab/dots.llm1
✨ 2: paperless-gpt
AI赋能的Paperless-ngx文档管理工具
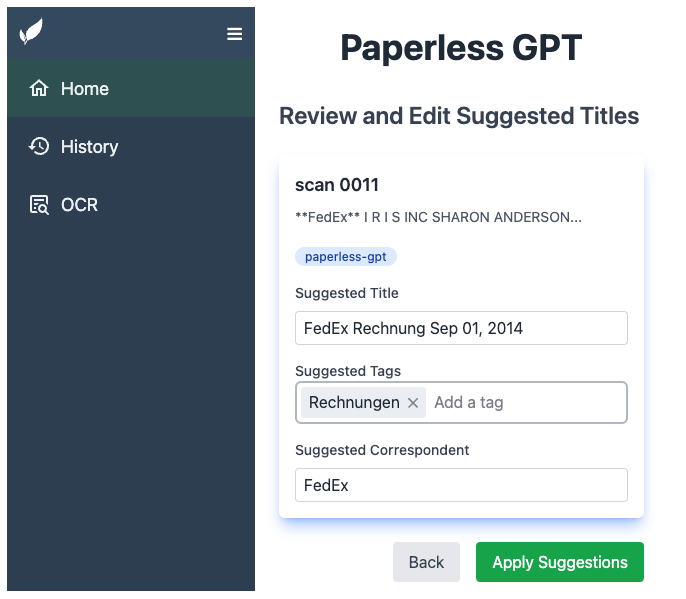
paperless-gpt 项目功能和特性总结:
-
1. LLM 增强 OCR: 使用大型语言模型 (OpenAI 或 Ollama) 实现比传统 OCR 更好的效果,能够将质量较差的扫描件转换为上下文感知的高保真文本。支持 LLM OCR、Google Document AI、Azure Document Intelligence 和 Docling Server 等多种 OCR 服务。
-
2. 自动生成标题、标签和创建日期: 通过 AI 自动完成文档命名和分类,用户可轻松审核和修改建议。
-
3. 支持 Ollama 中的推理模型: 使用
qwen3:8b等推理模型可以显著提高准确性,平衡隐私和性能。 -
4. 自动生成通信对象: 自动识别文档中的通信对象,方便跟踪和组织通信。
-
5. 生成可搜索和选择的 PDF: 生成带有透明文本图层的 PDF,该图层精确地位于每个单词上方,使文档既可搜索又可选,同时保留原始外观。
-
6. 广泛的自定义: 提供提示模板、标签选项和 PDF 处理方式的配置,以适应不同的需求。
-
7. 简单的 Docker 部署: 可以通过几个环境变量轻松与 paperless-ngx 一起部署。
-
8. 统一 Web UI: 提供手动审核和自动处理模式,方便用户管理 AI 建议。
地址:https://github.com/icereed/paperless-gpt
✨ 3: Open Deep Research MCP Server
AI驱动的深度研究报告生成器

Open Deep Research MCP Server 是一个AI驱动的研究助手,可以对任何主题进行深入的迭代研究。它结合了搜索引擎、网页抓取和AI技术,深入探索主题并生成综合报告。 该项目的主要功能和关键特征包括:
- 深度迭代研究:
通过生成有针对性的搜索查询来进行深入的迭代研究。 - 研究范围控制:
使用深度(depth)和广度(breadth)参数来控制研究范围。 - 来源可靠性评估:
对来源可靠性进行详细评分(0-1)和推理。 - 优先级排序和验证:
优先考虑高可靠性来源(≥0.7),并验证不太可靠的信息。 - 后续问题生成:
生成后续问题以更好地了解研究需求。 - 详细的Markdown报告:
生成包含发现、来源和可靠性评估的详细Markdown报告。 - MCP工具:
可作为AI代理的模型上下文协议(MCP)工具使用(目前MCP版本不询问后续问题)。 - 可选的本地Firecrawl:
可以使用本地 Firecrawl 实例,避免使用搜索 API 密钥 - 可选的可观察性:
可选使用 Langfuse 进行观测。 - 两种运行方式:
可以作为独立的CLI工具运行,也可以作为MCP服务器运行。
地址:https://github.com/Ozamatash/deep-research-mcp
✨ 4: TradingAgents
基于LLM的多智能体金融交易框架

- 多智能体框架:
TradingAgents模拟真实世界的交易公司动态,通过部署专门的、由LLM驱动的智能体,实现协同评估市场状况并辅助交易决策。这些智能体包括基本面分析师、情绪分析专家、技术分析师、交易员和风险管理团队等。 - 角色分解:
框架将复杂的交易任务分解为多个专门的角色,确保系统能够以稳健且可扩展的方式进行市场分析和决策。 - 分析师团队:
包括基本面分析师(评估公司财务和业绩指标)、情绪分析师(分析社交媒体和公众情绪)、新闻分析师(监控全球新闻和宏观经济指标)和技术分析师(利用技术指标检测交易模式和预测价格变动)。 - 研究员团队:
由多头和空头研究员组成,他们批判性地评估分析师团队提供的见解,通过结构化的辩论平衡潜在收益与内在风险。 - 交易员智能体:
综合分析师和研究员的报告,做出知情的交易决策,并确定交易的时机和规模。 - 风险管理和投资组合经理:
持续评估投资组合风险,并根据风险评估报告调整交易策略。投资组合经理最终批准或拒绝交易提议,如果批准,订单将被发送到模拟交易所执行。 - 模块化设计:
使用LangGraph构建,确保框架的灵活性和模块化。 - CLI(命令行界面)支持:
提供CLI界面,方便用户直接尝试,可以选择股票代码、日期、LLM、研究深度等。 - API支持:
支持FinnHub API获取金融数据,以及OpenAI API供所有智能体使用。 - 可配置性:
允许用户自定义配置,包括LLM的选择、辩论轮数等。 - 贡献:
鼓励社区贡献,共同改进项目。 - 用于研究目的:
声明该框架主要用于研究目的,交易业绩可能会因多种因素而异,不应作为金融、投资或交易建议。
地址:https://github.com/TauricResearch/TradingAgents
✨ 5: MAS-Zero
零监督多智能体系统设计:MAS-Zero
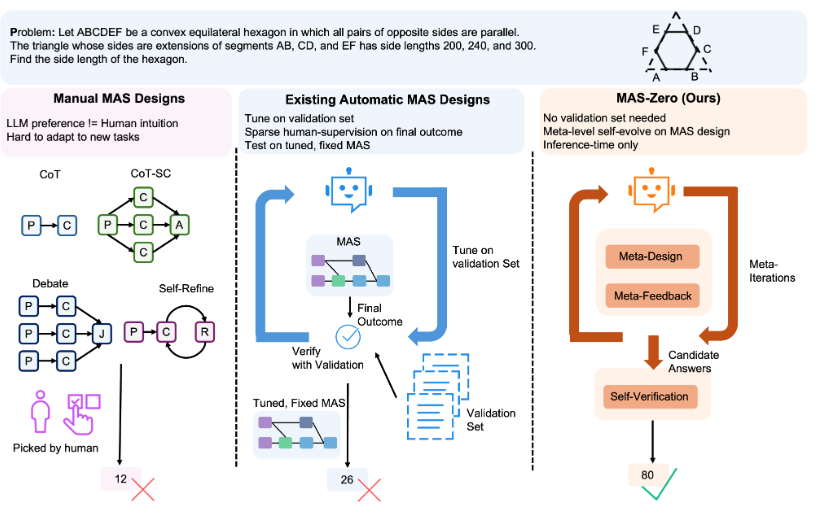
MAS-Zero项目旨在无需人工监督的情况下设计多智能体系统(MAS)。它通过一个元代理,执行设计、评估和验证等多种角色,主要包含元迭代和自验证两个步骤。元迭代包括MAS设计(将任务分解并为每个子任务提出子MAS,构建成代码生成问题)和MAS反馈(通过执行MAS代码评估生成设计的可解性和完整性)。最后,自验证从元迭代过程中生成的所有候选解决方案中选择最合适的方案。该方法无需验证集,在元级别进行自我监督,并且仅在推理时进行操作,在数学推理、研究生水平问答和代码基准测试中表现出色,且不依赖任何外部监督。项目提供了一套环境配置和训练脚本,用于使用零监督来设计MAS,并支持多种LLM。
地址:https://github.com/SalesforceAIResearch/MAS-Zero
(文:每日AI新工具)