
“ 大模型应用的很多功能包括记忆管理,需要的不仅仅只是技术问题,还需要足够的工程化能力才能解决。”
众所周知,大模型是没有记忆功能的,因此记忆管理就成为大模型应用过程中必不可少的一个环节;虽然说记忆管理说起来很简单,但在实际操作中还是存在很多问题。
比如说,随着记忆的增加token成本的上升,大模型窗口的限制,记忆的存储问题等等。
因此,今天就从项目的实际操作中来详细了解一下大模型的记忆功能;开发框架是基于langchain的记忆管理模块。
大模型记忆管理问题
大模型记忆管理问题主要存在于NLP任务的对话场景中,其本质就类似于我们平常人聊天需要有一个上下文;比如说你朋友在聊天你突然过来,肯定要先问一下他们在聊什么,或者在旁边听一下他们在聊什么,这时你才知道怎么开口。
而大模型由于自身的原因导致其没有记忆功能,也就是说每次对话对大模型来说都是一次全新的交流;这玩意就类似于一个健忘症的人,上一句刚说完他就忘了刚说的是什么。
因此,大模型记忆管理就应运而生了;记忆管理说起来也很简单,就是把每次和大模型的对话记录下来,你说了什么大模型说了什么;然后每次聊天的时候把这段对话记录一起输入到大模型中(拼接到提示词中),这样大模型就可以根据这段上下文知道你们聊了什么。

在langchain中封装了一些记忆功能的模块,主要是基于内存的会话记忆;当然,也有为解决分布式场景下的存储中间件(关系型数据库,redis缓存等),本质上就是把对话记录保存下来,在每次对话时再加载出来然后拼接到提示词中。
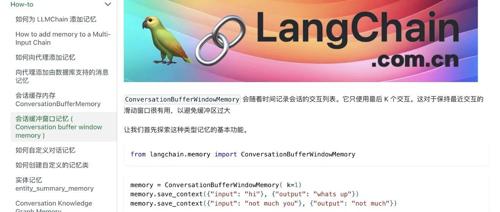
比如其中使用比较多的ConversationBufferMemory记忆,其实就是简单粗暴的把所有对话记录都保存下来;但这同样会带来一些问题,比如说随着对话次数的增长,对话记录会越来越长,这时token消耗就会越来越多;而更重要的是,大模型的窗口大小是有限制的,因此如果持续增长下去就会导致超长问题。
所以,这就有了会话缓存窗口记忆ConversationBufferWindowMemory,本质上来说就是给会话加了一个k值,目的就是只记录最近的k轮对话;比如说你对话了一百次,但我只记录最近的10次,这样既可以解决成本问题,也可以解决超长问题。
但这同样会有新的问题出现,那就是丢失了之前的对话记录,可能会导致上下文缺失;这就类似于两个人喝酒吹了两个小时的牛逼,突然说我们刚开始聊的啥,这时由于对话记录已经丢失,大模型就无法获得之前的上下文。

所以,为了解决这个问题,就设计了一个总结记忆功能;其原理就是把对话记录输入到另一个总结模型,让这个模型根据对话的内容总结其中的关键信息,这样就可以解决上下文丢失问题。
但由于需要多次访问大模型,以及随着对话的增多,总结的内容同样会增多,因此可能依然存在上下文窗口限制问题;而且由于大模型只关注文本头和尾,对文本中间内容处理效果不太好,因此依然会出现上下文缺失的情况。
所以,从以上问题来看,大模型记忆管理是一个复杂的过程,并且根据不同的场景需要选择合适的记忆管理方式。
而且在实际操作中,整个系统不可能只有一个人访问,因此需要根据不同的用户使用用户标识或者会话标识来区分不同用户的记忆数据;但同样,因为对话记录是保存在内存中或者第三方存储中间件中,但对话的时间是有限的,因此还需要做记忆的生命周期管理,也就是说用户一轮对话完成之后,可以在适当的时间清理掉不在需要的对话记录。

如以上代码,根据session_id会话id作为为每个用户都创建记忆功能,这个会话id可以根据不同的应用场景选择合适的唯一标识符;而且,在存储会话的过程中,设置一个last_active时间参数,当到达最长会话时间时,可以自动清理掉过期的会话记录。

这样就可以在技术上防止内存泄露,或者存储空间不足的问题。
当然,以上功能也仅仅只适用于部分应用场景,比如说在分布式环境下就不能使用基于内存的记忆存储,而需要借助外部存储工具,如redis等。因此,在具体的应用中,用户可以选择性地使用这些记忆工具,当然也可以完全自己开发一套记忆管理工具。
总之,大模型应用在学习过程和实际应用中还是存在一定的区别;有些问题需要通过技术本身来解决,而有些问题需要工程化的方式来避免或解决。
(文:AI探索时代)