


今日凌晨,Qwen3终于发布。
网友直呼“等得好苦”。
我也想说,明知道大家都在等着,你今天才发布,咋不等五一大家都放假了再发布呢?????
Qwen系列也是超越众多模型再次登顶开源王座。
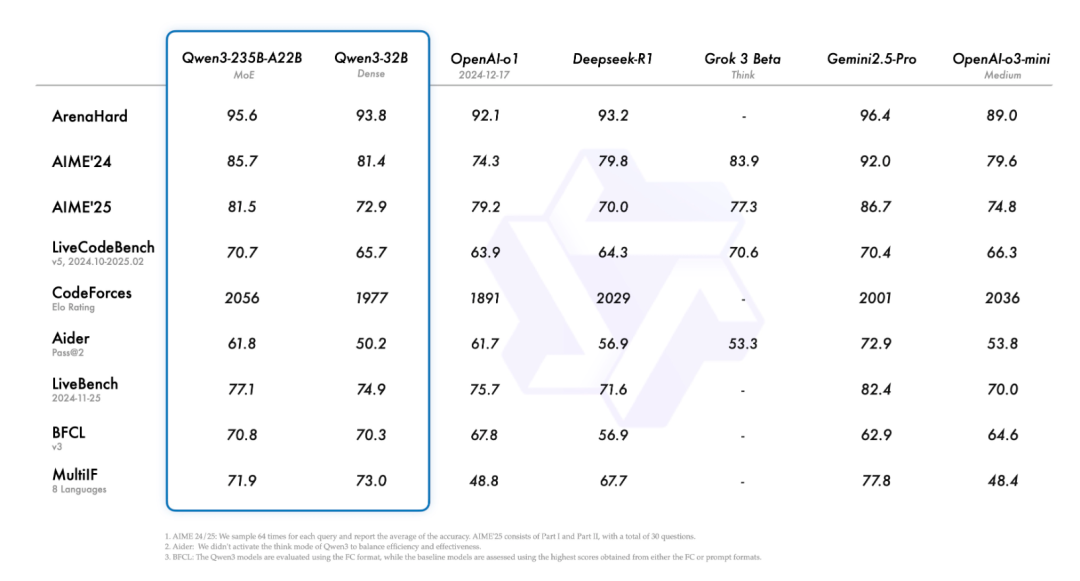
旗舰模型 Qwen3-235B-A22B 在代码、数学、通用能力等方面,已经超越 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等模型。
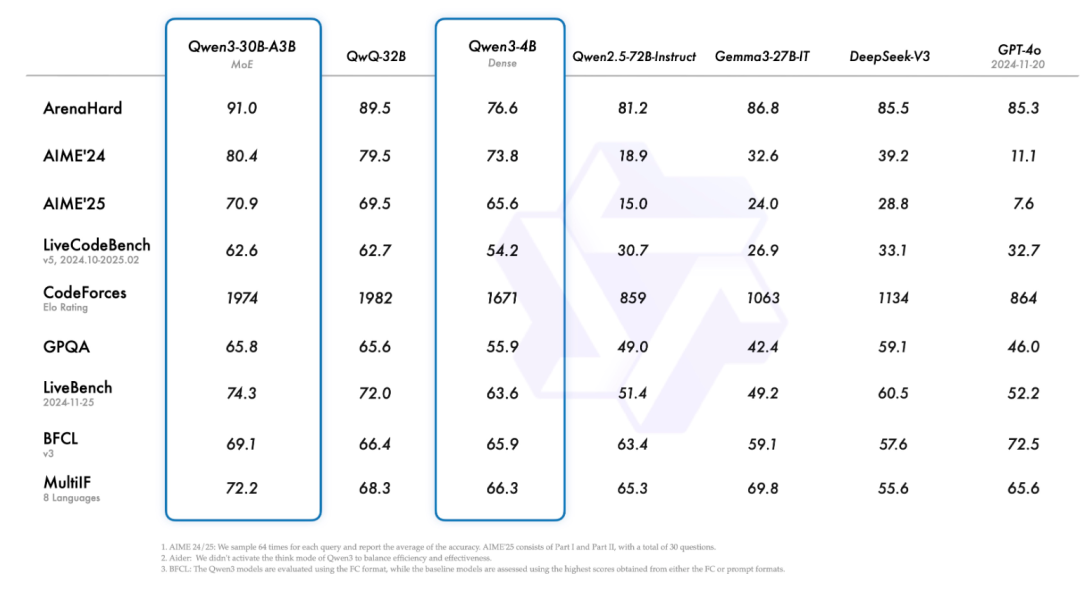
Qwen3-4B,这样一个小模型,也能跟 Qwen2.5-72B-Instruct 性能匹敌。
不啰嗦,争取用最少字数,讲清楚所有亮点。
扫码加入AI交流群
获得更多技术支持和交流
(请注明自己的职业)

模型型号
两个MOE模型
Qwen3-235B-A22B 总参数量 2350 亿,激活参数量 220 亿。
Qwen3-30B-A3B 总参数量 300 亿,激活参数量 30 亿。
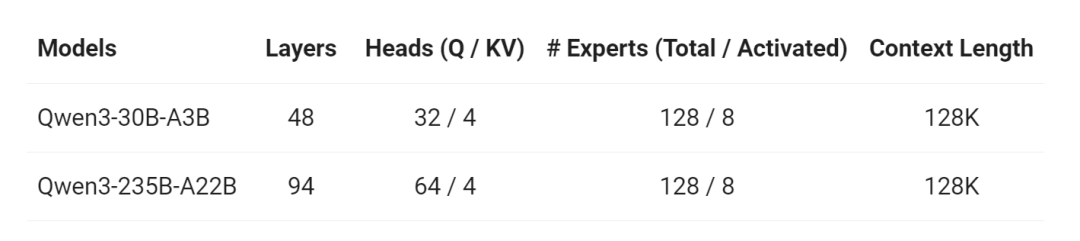
六个密集模型
Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B和Qwen3-0.6B。

三大亮点
Qwen3是国内首个混合推理模型。
· 混合思维模式
Qwen-3引入了独特的“混合思维模式”,包括“思考模式”和“非思考模式”,根据任务需求灵活切换,在成本效率和推理质量之间的平衡更好把握。
思考模式:专为需要深度推理的任务设计,例如数学证明、战略规划或复杂问题解决。模型会逐步分析问题,提供详细的逻辑过程。
非思考模式:针对简单查询,提供快速、直接的回答。

· 多语言支持
Qwen3 模型支持119 种语言和方言。
之前的多语言能力不够好,所以我平时在开发中还是会用Gemini、GPT这些模型,现在多了一种选择。

· 增强代理能力
Qwen3优化了编程和Agent能力,增强了MCP(多角色扮演),能够更好地在复杂交互场景中发挥作用。
Qwen-3训练
预训练
Qwen-3的预训练使用了36万亿个token的数据集,相比Qwen2.5的18万亿token翻了一倍。
这一数据集涵盖119种语言,来源包括网络文本、PDF文档以及通过Qwen2.5-VL和Qwen2.5生成的合成数据,特别针对数学和编程进行了优化。
预训练分为三个阶段:
-
S1阶段:使用30万亿token,上下文长度为4K,建立基础语言理解能力。
-
S2阶段:专注于知识密集型任务,使用5万亿token,提升模型在专业领域的表现。
-
S3阶段:针对长上下文理解,使用32K上下文长度,适用于处理长文档或复杂对话。
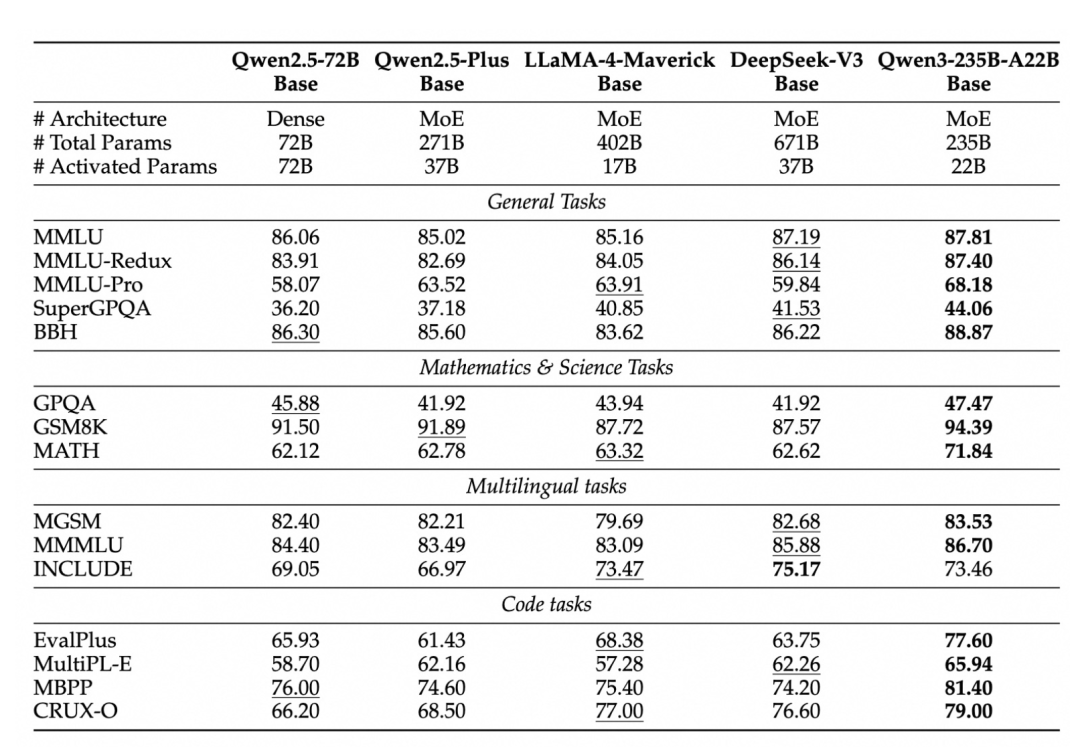
MoE模型仅激活10%的参数,大幅降低了计算成本,同时保持高性能。
后训练
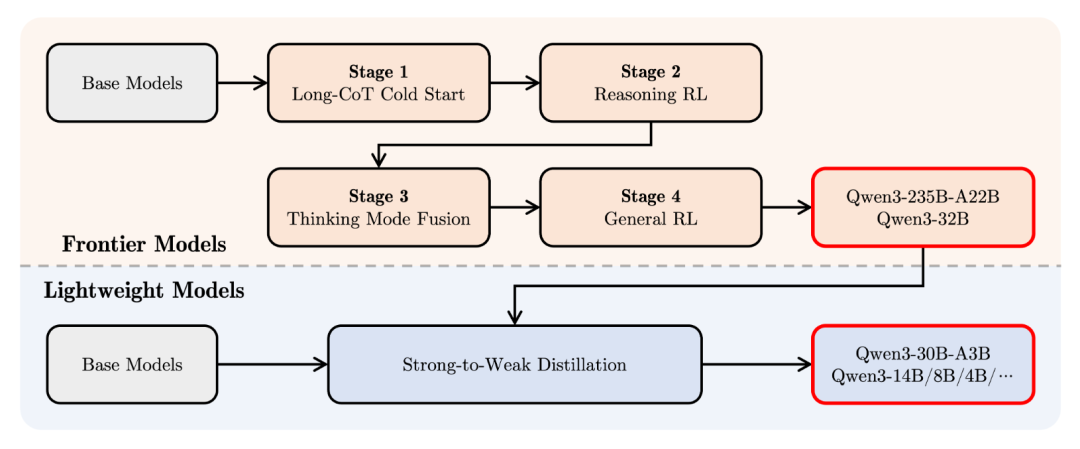
Qwen-3的后训练采用四阶段流程:
-
阶段1:长链式推理(CoT)冷启动:专注于复杂推理任务,训练模型处理多步骤问题。
-
阶段2:基于推理的强化学习(RL):通过强化学习优化推理能力,提升逻辑严密性。
-
阶段3:思考模式融合:将思考和非思考模式无缝整合,确保模式切换顺畅。
-
阶段4:一般强化学习:在20多个任务上(如指令遵循、对话生成)进行微调,提升通用性。
Think Deeper, Act Faster
Qwen3再次用技术,把全球开发者聚在一起。
更多的语言支持,更强的性能,更快的速度,更低的成本,Qwen3再次让全球AI开源项目不得不考虑加入支持。
模型链接
https://huggingface.co/Qwen
文档链接
https://qwen.readthedocs.io/en/latest/
关注「开源AI项目落地」公众号
(文:开源AI项目落地)