


宣传一下我们被 ICLR 2025 录用的工作 OSTQuant。OSTQuant 在 LLMs 不同的量化配置中(weight-only、weight-activation 和 weight-activation-kvcache)都展示了优越的性能。例如,W4A16 达到 99.5%+ 的精度保持率,在更激进的 W4A4KV4 中保持了原始性能的 96%,为 LLMs 的高效部署提供了新的技术路径。

论文链接:
论文单位:

序言
近年来,大规模语言模型(Large Language Models, LLMs)在自然语言处理领域取得了革命性进展。以 GPT 系列、LLaMA 等为代表的模型,通过千亿级参数的复杂结构展现出强大的语义理解和生成能力。
然而,大量的内存和计算需求使 LLMs 面临重大的部署挑战,推理时的计算延迟和能耗更使其难以在资源受限的边缘设备或实时系统中应用。在此背景下,后训练量化(Post-Training QuantizatPion, PTQ)技术已成为一种广泛采用关键解决方案。
PTQ 通过将模型参数从 32 位浮点数压缩至更低位宽,可在保持模型性能的同时显著降低存储需求和计算复杂度。但传统量化方法面临两个根本性挑战:
1. 分布不匹配:LLM 的权重与激活值通常具有非对称、重尾分布特征以及通道间方差差异,这些特性会扩大量化范围,导致大部分数据的可用量化比特降低,进而影响模型性能。
2. 校准数据限制:PTQ 通常依赖少量校准数据(如 1,000 个样本)优化量化参数,传统损失函数(如交叉熵)容易在小样本下过拟合,损害模型的零样本泛化能力。
现有研究主要通过线性变换方法改善数据分布,例如 SmoothQuant 通过通道间方差迁移平衡权重与激活的量化难度,Quarot 采用旋转矩阵抑制异常值。
然而这些方法存在明显局限:一方面,其变换策略依赖启发式设计,缺乏对量化空间利用效率的系统性评估;另一方面,现有方法多聚焦局部优化,未能在全局量化空间维度实现分布对齐。
这些问题导致现有量化方法在低比特场景(如 W4A4KV4)下性能损失显著,严重制约了 LLMs 低比特推理的实用化进程。
本文提出 OSTQuant(Orthogonal and Scaling Transformation-based Quantization)框架,通过三个核心创新突破上述瓶颈:
1. 建立量化空间利用率(Quantization Space Utilization Rate, QSUR)作为评估可量化性的有效指标,为量化方法设计提供理论指导;
2. 设计多个正交-缩放等效变换对,在保持模型功能等价性的同时优化全局数据分布来提高 QSUR 和量化性能;
3. 引入 KL-Top 损失函数,从模型中捕获更丰富的语义信息,同时减轻标签噪声的影响。
实验表明,OSTQuant 在 weight-only、weight-activation 和 weight-activation-kvcache 量化模式中都展示了优越的性能。在 W4A16 量化时,该方法实现了超过 99.5% 的精度保持率,而在更激进的 W4A4KV4 设置中,它至少保持了模型原始性能的 96%,为 LLMs 的高效部署提供了新的技术路径。
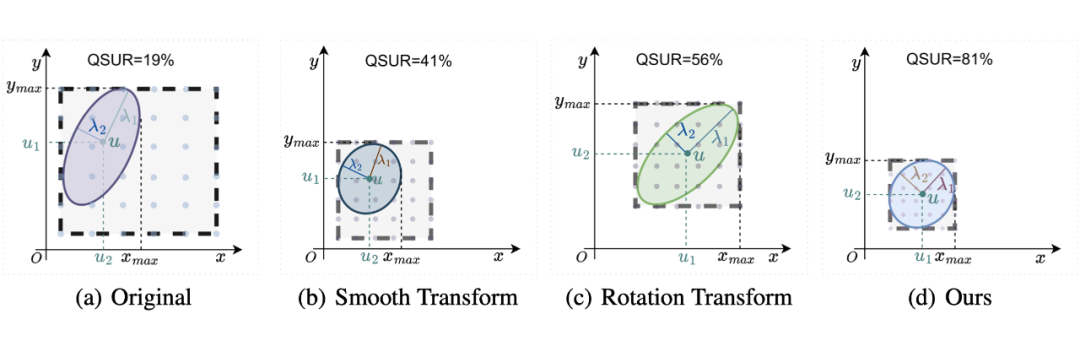
▲ 用不同的方法对一批二维数据 X~N (µ,Σ) 进行变换。特征值 λ1 和 λ2 表示特征值分解后沿主轴分布的扩展。(a)表示原始分布,(b)、(c)和(d)分别说明了基于 Smooth-base、Rotate-base 和我们基于 OST 的方法对 QSUR 的影响。椭圆内的量化点数量越高,表示分布的量化空间利用率越大。

相关工作
2.1 LLM 后训练量化
后训练量化(PTQ)因其高效性已成为 LLMs 优化的主流技术,现有方法主要分为仅权重量化和权重 – 激活量化两类。
仅权重量化:这类方法旨在降低内存使用,通过特定策略优化权重量化。GPTQ 运用基于 Hessian 的误差补偿技术,通过最小化量化误差来实现高压缩率;AWQ 和 OWQ 则着重解决激活异常值对权重量化的影响,以此提升量化性能;QuIP 和 QuIP #借助随机 Hadamard 矩阵进行非相干处理,并对权重应用向量量化,在低精度量化下仍能取得较好效果。
权重 – 激活量化:此方法旨在通过同时量化权重和激活(包括 KV Cache)来加速 LLM 推理。然而,激活量化面临着异常值主导量化范围的问题,导致大多数值的有效比特数减少,进而产生显著误差。
ZeroQuant 提出了一种对硬件友好的细粒度量化方案;SmoothQuant 通过数学变换将量化难度从激活转移到权重;OmniQuant 进一步通过训练量化参数和变换系数来提升性能;I-LLM 利用全平滑块重建和全整数算子实现了仅整数的量化和推理。
最近,QuaRot 借助随机旋转矩阵实现了 4 比特的权重和激活量化,SpinQuant 则通过学习旋转矩阵对 4 比特量化进行优化 。
2.2 黎曼优化
在优化旋转矩阵时,需遵循正交归一性约束,这等价于在 Stiefel 流形(包含所有正交矩阵)上进行黎曼优化。
Cayley SGD 依赖 Cayley 变换的迭代逼近,仅通过矩阵乘法就能有效优化任意损失函数下的旋转矩阵;RAOM 将 ADAM、ADAGRAD 和 AMSGRAD 等优化方法拓展到黎曼优化领域;Geoopt 支持基本的黎曼随机梯度下降(SGD)和自适应优化算法,便于与模型无缝集成进行全面优化。
这些技术为处理旋转矩阵的特殊性质提供了有效手段,在大语言模型量化研究中发挥着重要作用。

本文方法
3.1 量化空间利用率(QSUR)
-
:数据分布占据的超体积,由协方差矩阵 决定; -
:量化超立方体体积,由数据各维度的最大值与最小值定义。
关键推导步骤
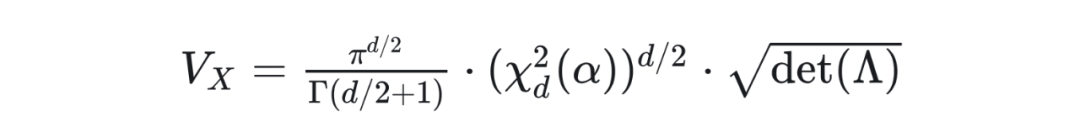
2. 量化超立方体体积计算:量化范围由数据沿主轴的极值点决定,即:
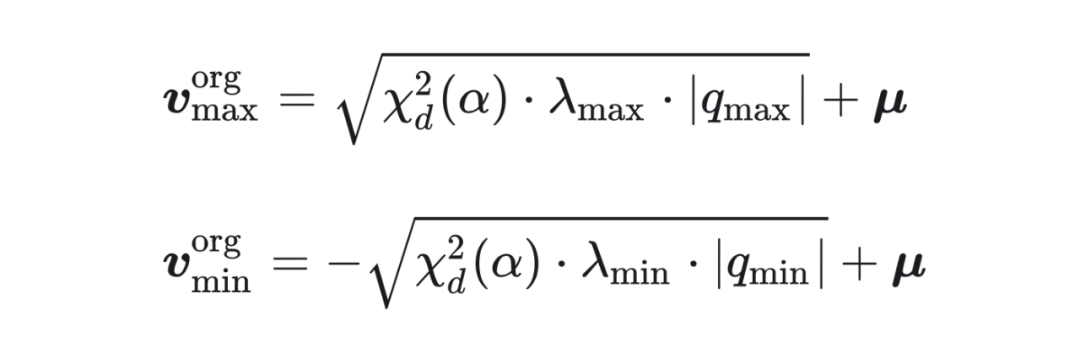
由此可得:
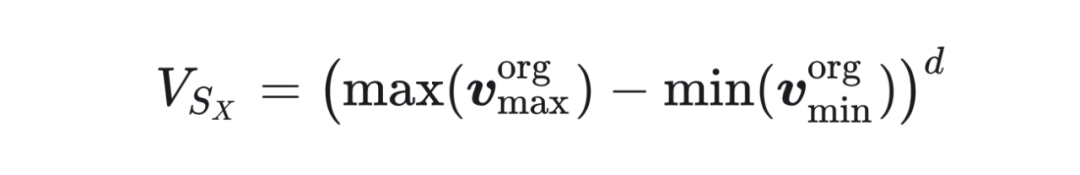
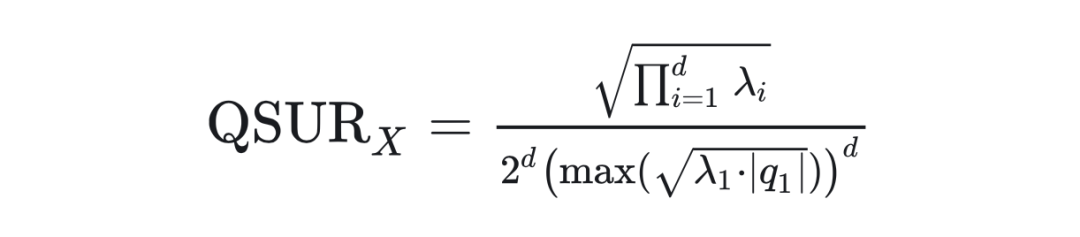
这表明 QSUR 与特征值的均衡性正相关。当所有特征值相等(即数据呈球型分布)时,QSUR 达到最大值。
最优变换矩阵的数学构造
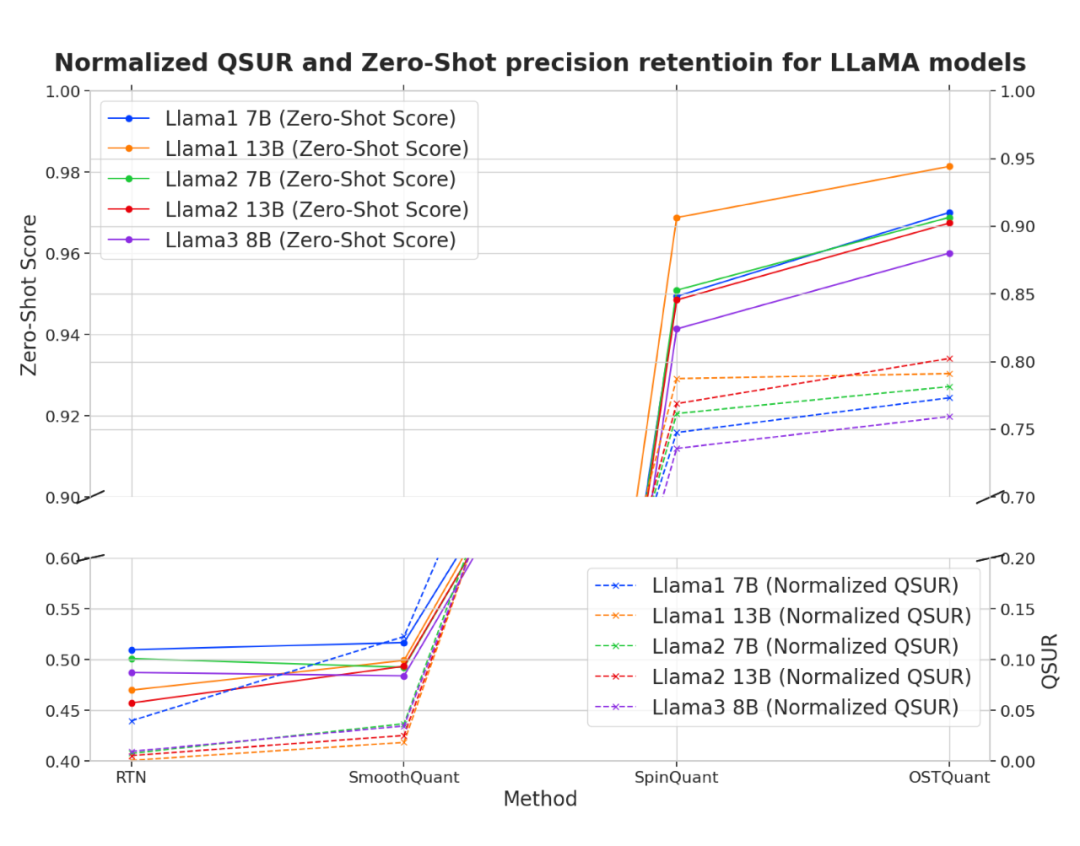
▲ QSUR 与模型量化精度呈正相关
3.2 正交-缩放等效变换
OSTQuant 的核心是通过正交变换(Orthogonal Transformation)与缩放变换(Scaling Transformation)的联合优化,实现权值和激活值分布的全局调整,以此来提高量化性能。
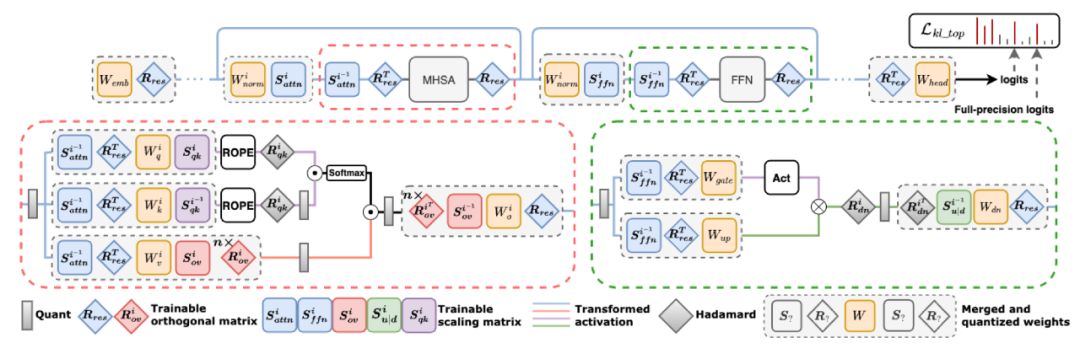
由正交变换和缩放变换组成的可学习等效变换对表示如下:

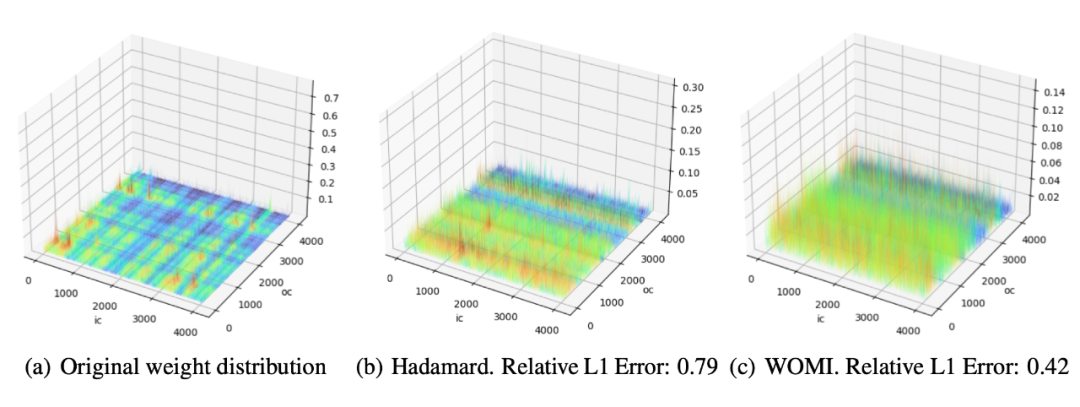
OSTQuant通过权重异常值最小化初始化(Weight Outlier Minimization Initialization, WOMI)进一步提升初始量化效果。
该方法基于权重协方差矩阵的特征分解,结合哈达玛矩阵的均匀分布特性,生成初始正交变换矩阵,有效减少权重通道间的方差差异。如图所示,WOMI 相比随机哈达玛变换,能将权重量化的相对 L1 误差降低近 50%。
此外,OSTQuant 还同时进行块间学习和块内学习。在块间学习中,正交变换通过全局矩阵 作用于嵌入层与所有残差路径并引入两个对角缩放矩阵 和 来平滑通道差异,这些变换可融入相应权重矩阵,有效学习分布变化对模型精度的影响,减轻量化误差。
在块内学习中,在每个 transformer 块的多头自注意力层引入两个等价变换对,对 Value projection()和 Out projection()进行跨层变换,为每个注意力头学习旋转变换 和缩放变换 ,针对不同注意力头独立优化,适配其独特的分布模式,以提高 Value cache 和 Out projection 的 QSUR。
在 Rotary Positional Encoding(ROPE)操作后,输出 Query 和 Key 可自然进行等价缩放变换(),还对 Query 和 Key 的应用额外的 Hadamard 变换 ,进一步提升 Key Cache 的量化效率。对于 FFN 模块,上下投影层(Up/Down Projection)的激活函数(如 SiLU)通过尺度因子 与 调整,其数学形式为:
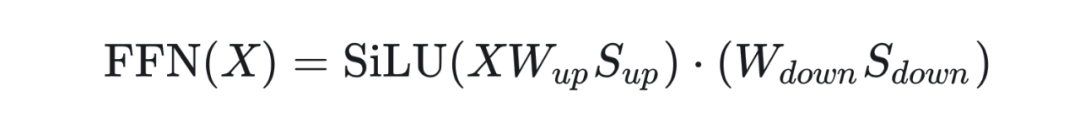
3.3 KL-TOP 损失函数
虽然 LLM 通常在大量数据集上进行训练,但 OSTQuant 优化使用小得多的校准数据集进行。在这种有限的数据环境中,直接应用原始交叉熵(CE)损失可能会导致模型过度拟合。
使用 KL 散度优化可以在量化前后对齐预测分布,以减少过拟合风险。但大语言模型词汇量往往数以万计,全精度模型的预测结果呈严重长尾分布,直接应用 KL 散度进行优化,损失可能被低概率的无信息类别主导,为训练过程引入噪声。
OSTQuant 提出 KL-Top 损失函数。该损失仅计算预测概率最高的前 个类别的 KL 散度,避免低概率噪声对梯度更新的干扰。具体而言,对于全精度模型与量化模型的输出分布 和 ,首先通过 筛选保留主要语义信息,再计算加权 KL 损失:


评估结果
4.1 量化精度对比
-
W4A16KV16:OSTQuant 超越了先前方法,在 zero-shot 任务中保持了至少 99.5% 的浮点(FP)精度。与 GPTQ 和 AWQ 等其他纯权重量化方法相比,OSTQuant 进一步缩小了与 FP 模型的差距。在最具挑战性的 LLaMA-3-8B 模型中,OSTQuant 在 zero-shot 评估中仅实现了 0.29 点的性能下降。
-
W4A4KV4:在极具挑战性的 4-4-4 设置中,我们的方法也保留了显著的性能增益。

4.2 推理效率与内存节省
OSTQuant 在 NVIDIA 3090 GPU 和 A6000 GPU 上的实测结果显示:
-
推理加速:LLaMA-30B 的预填充(Prefill)阶段速度提升 3.4 倍,解码(Decoding)吞吐量达 30.49 tokens/sec。
-
内存压缩:LLaMA-3-70B 全 4bit 量化后显存占用仅 38.41GB,可在单卡 A6000 上流畅运行。
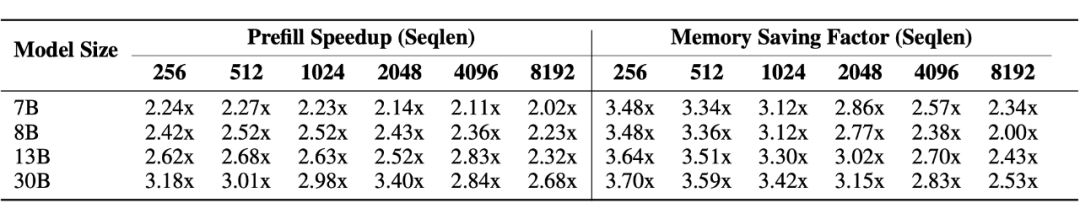
▲ NVIDIA 3090 GPU 测试结果
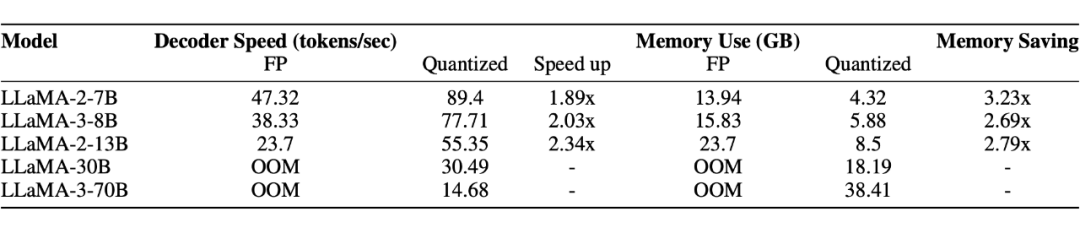
▲ A6000 GPU 测试结果
4.3 训练效率优势
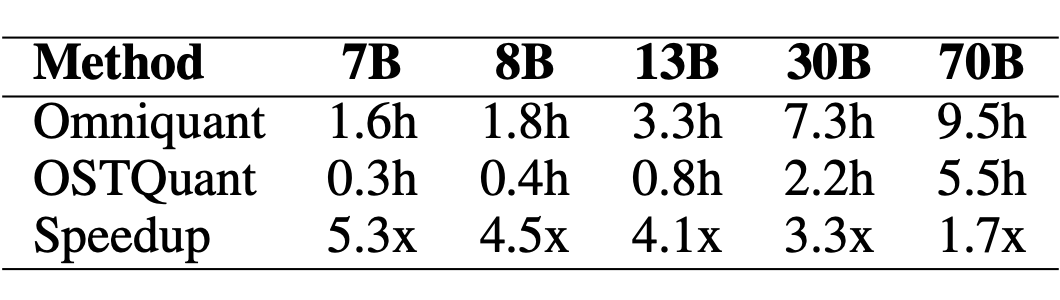
相比基于块重建的方法(如 OmniQuant),OSTQuant 凭借少量可学习参数(仅正交与缩放矩阵),将 7B 模型的优化时间从 1.6 小时缩短至 0.3 小时,加速比达 5.3 倍。

结论
在本文中,我们介绍了 OSTQuant,这是一种全新的后训练量化方法,旨在提高大语言模型(LLMs)的效率。OSTQuant 的核心是量化空间利用率(QSUR),这是我们提出的一种新指标,通过测量数据在量化空间内的空间利用率,有效评估变换后数据的可量化性。
QSUR 辅以数学推导,为在整个量化空间中优化单个数据分布提供了理论指导。基于这一见解,OSTQuant 采用了由正交变换和缩放变换组成的可学习等价变换对,来优化权重和激活的分布。
此外,我们引入了 KL-Top 损失函数,即使在通常用于后训练量化(PTQ)的有限校准数据情况下,该函数也能在优化过程中减少噪声,同时保留更丰富的语义信息。
在各种大语言模型和基准测试上进行的大量实验表明,OSTQuant 优于现有的量化方法。这些结果凸显了在量化空间中优化数据分布的有效性,也强调了 OSTQuant 在推进大语言模型量化方面的潜力,使得这些模型在资源受限的环境中部署时更高效、更实用。
(文:PaperWeekly)