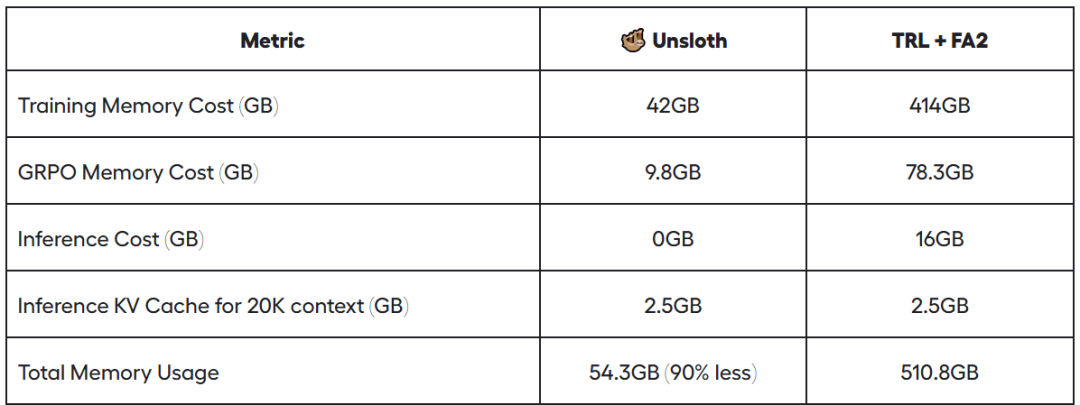
unsloth在微调一个Qwen2.5-1.5B 模型只需要5GB显存 2025年2月22日8时 作者 NLP工程化 unsloth 又优化了他们的微调(fine-tuning)框架,现在微调一个Qwen2.5-1.5B 模型只需要5GB显存了。之前需要7GB。 参考文献:[1] https://unsloth.ai/blog/grpo (文:NLP工程化)