
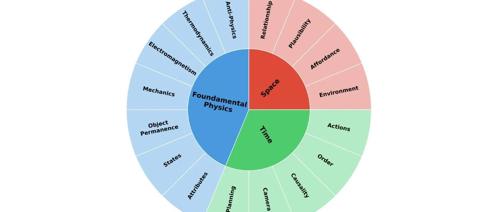
推理延展到真实物理世界,英伟达Cosmos-Reason1:8B具身推理表现超过OpenAI ο1
答案的情况,比如以下例子:
根据视频中本车的动作,它接下来最有可能立即采取的行动是什么?
A:右转,
答案的情况,比如以下例子:
根据视频中本车的动作,它接下来最有可能立即采取的行动是什么?
A:右转,

AI 大神 Andrej Karpathy 比喻训练大型语言模型 (LLM) 的过程就像教育学生,以教科书的结构阐述了当前 LLM 训练现状和未来方向。他将预训练、监督式微调和强化学习分别比作背景信息、例题及解答和练习题,强调需要更多的实践来提升 LLM 能力。
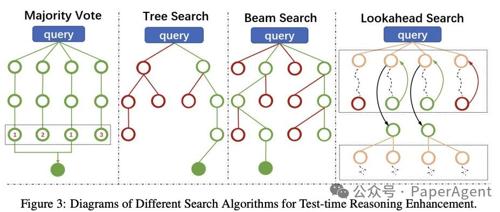
本文回顾了大型语言模型在推理能力方面的最新进展,从SFT到RLHF,再到ORM和PRM等技术的演变,讨论了测试时扩展的重要性,并介绍了各种增强LLMs推理能力的技术方法。