
谷歌新推理模型重磅来袭:百万上下文,代码执行,推理能力飙升!

木易是互联网技术产品经理,专注于分享AI知识和工具。近期谷歌发布的新模型Gemini-2.0-Flash-Thinking-Exp-01-21,具有100万tokens上下文窗口、原生代码执行等功能,助力提升推理能力和输出长度。这是AI领域内的一个重要进展。
木易是互联网技术产品经理,专注于分享AI知识和工具。近期谷歌发布的新模型Gemini-2.0-Flash-Thinking-Exp-01-21,具有100万tokens上下文窗口、原生代码执行等功能,助力提升推理能力和输出长度。这是AI领域内的一个重要进展。

大模型已成为中国AI研究主流。DeepSeek在中文语义处理方面表现出色,成功翻译了俄罗斯教授的经济学导论。DeepSeek还提供了文本生成、分类与情感分析、问答系统等多样的功能。

中国双子星DeepSeek和Kimi发布全新推理模型R1和k1.5,性能接近OpenAI o1,引发业界关注。Long2Short训练方案成为亮点,提升了短推理路径模型的性能。

两家企业DeepSeek和Kimi发布推理模型,展示了不同的技术路线。Kimi采用了长上下文扩展、在线镜像下降等策略提升性能,并创新性地提出了Long2Short训练方案。对比其他模型,其在多模态能力和推理精度上表现出色。

赶在放假前,支棱起来的国产 AI 大模型厂商井喷式发布了一大堆春节礼物。
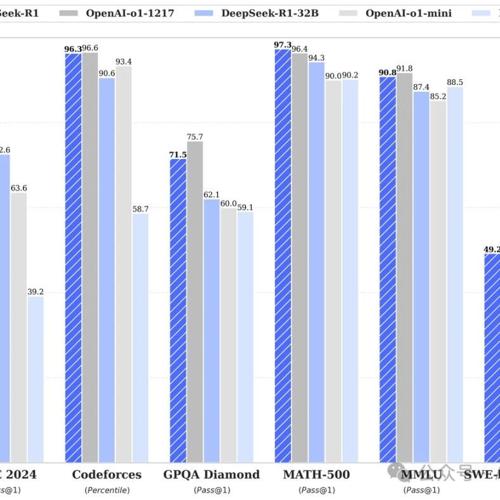
前脚 DeepSeek-R

国产大语言模型军备竞赛正式启动!DeepSeek发布DeepSeek-R1及Kimi发布k1.5,对标o1不输o1。DeepSeek和Kimi均采用增强学习技术训练,并开源其模型。
在数学竞赛AIME测试中,Qwen-1.5B模型以28.9%的成绩击败了GPT-4和Claude 3.5-Sonnet。仅1.5B参数量的它,在MATH测试中取得83.9%成绩。DeepSeek团队采用知识蒸馏技术成功将大模型智慧浓缩进更小的模型,MIT许可下开源多个版本。


