
字节跳动

必看!VividTalk:阿里、南大等联合打造,一张照片+音频秒变说话头像视频黑科技

VividTalk是南京大学、阿里巴巴、字节跳动和南开大学联合开发的人工智能技术项目,通过音频驱动生成逼真的说话头像视频。该项目采用先进的3D混合先验技术和双分支运动-VAE(变分自编码器)来实现高质量的视觉效果和自然同步对话。
太惊艳!字节跳动 INFP,让虚拟对话 “活” 起来啦

INFP是字节跳动研发的一种全新的音频驱动交互式头部生成框架,它能根据双轨对话音频实时生成动态虚拟人物头像,支持多语言、唱歌模式和多种场景。研究显示其在音频-唇同步性、身份保留和动作多样性等方面表现优异。


Video Depth Anything来了!字节开源首款10分钟级长视频深度估计模型,性能SOTA

Video Depth Anything 工作解决了单目深度估计在视频领域的时序一致性问题,融合时空头、时域一致性损失函数和关键帧推理策略,实现精度、速度及稳定性三者的平衡。
ComputerUse再来重磅玩家,字节跳动开源 纯视觉驱动GUI 智能体模型 UI-TARS,桌面浏览器全支持
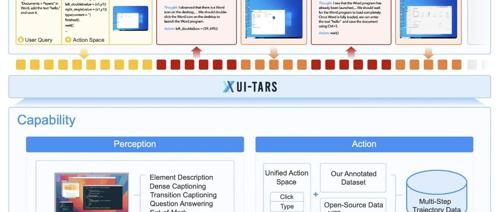
字节跳动开源UI-TARS模型,通过纯视觉驱动和端到端架构实现高效GUI自动化操作,支持多种平台,已在GitHub上发布多个版本供开发者试用。
字节的可以直接操作图形界面的原生 GUI 智能体模型UI-TARS
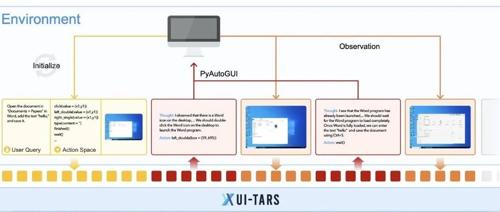
UI-TARS 是一种智能体模型,可以直接理解并操作图形界面的原生 GUI 智能体,它具有感知、行动、推理和记忆等关键能力。相比传统拼装方法,UI-TARS 使用一个“大模型”进行端到端学习,提升了灵活性与稳健性,并在某些测试上超过了 Claude 和 GPT-4。
一人能顶一个公司:字节AI编程神器Trae诞生了!
2024年推出的中文友好的AI编程IDE Trae发布,支持实时建议、代码片段生成等功能,内置Claude-3.5-Sonnet免费聊天模型,简化了项目开发和日常编码过程,特别适合英语非母语开发者。
