多步推理碾压GPT-4o,无需训练性能提升10%!斯坦福开源通用框架OctoTools

斯坦福大学OctoTools框架通过标准化工具卡、规划器和执行器,无需训练即可显著提高LLMs处理复杂任务的能力,比其他方法平均准确率高出9.3%。
斯坦福大学OctoTools框架通过标准化工具卡、规划器和执行器,无需训练即可显著提高LLMs处理复杂任务的能力,比其他方法平均准确率高出9.3%。

Model Context Protocol(MCP)是一种新型协议,旨在标准化大型语言模型与外部工具和服务的集成。它简化了AI系统的API使用,并提供了更高效、灵活和动态的通信方式。

Python项目排行:1. 一个用于教育研究的人工智能对冲基金系统;2. 开源命令注入漏洞检测与利用工具Commix;3. 基于LLM的搜索引擎生成文章工具Storm;4. 将电子书转换为有声读物的Ebook2AudioBook;5. 提供GPT-4o和Claude-3.7-Sonnet接口以提高GitHub Copilot编码效率。
斯坦福大学开源的AI写作工具STORM能自动生成文章大纲、模拟专家对话并收集资料生成高质量文章,支持多种写作场景,目前仅支持英文。
Granite-3.2-8B-Instruct-Preview 是一款早期发布的 8B 长上下文模型,专为增强推理能力而进行微调,基于 Granite-3.1-8B-Instruct 构建,并使用开放许可开源数据集和合成数据训练。

Andrej Karpathy 在 YouTube 上发布了一段长达 2 小时的学习视频,详细介绍了如何使用大型语言模型(LLM),涵盖模型生态系统、交互示例和多种应用场景。
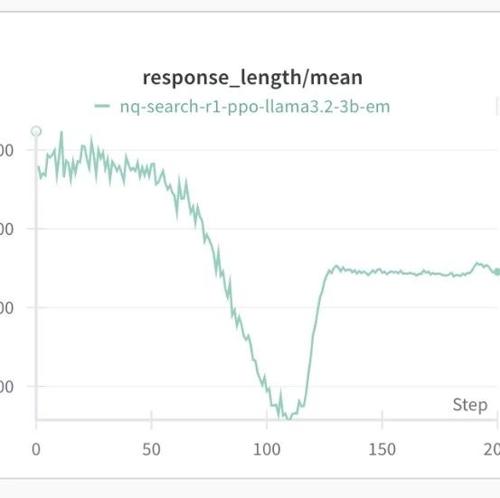
高效、可扩展的强化学习训练框架Search-R1,支持3B规模的基础LLM,通过规则化奖励机制让LLM自主学会推理和搜索,提供完整的训练流程和工具支持。