
北京交通大学

豆包团队视频生成新突破:无需语言模型,仅凭“视觉”就能学习复杂任务
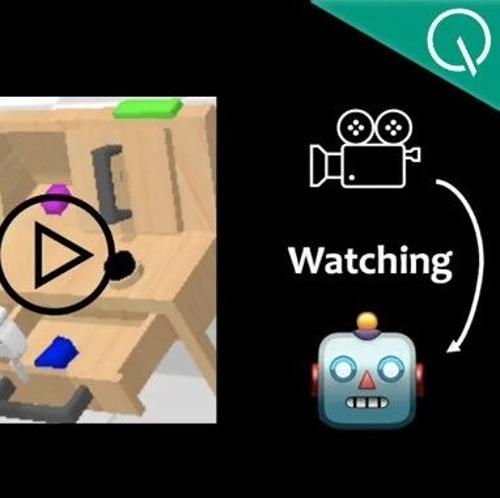
一种名为VideoWorld的模型无需依赖语言模型,仅通过视觉信号学习知识、认知世界,并能执行复杂任务。它利用潜在动态模型高效压缩视频帧间的视觉变化信息,显著提升知识学习效率和效果。
陶仁帅@北京交通大学:浅谈高质量学术论文的Rebuttal撰写体会

MLNLP社区举办学术Talk活动,特邀北京交通大学陶仁帅分享高质量学术论文Rebuttal撰写体会,涵盖技巧、策略和常见误区,帮助学生提高投稿成功率。
AAAI 2025丨2080Ti 也能 4K 图像抠图 !美图&北交大提出超高分辨率自然图像抠图算法 MEMatte
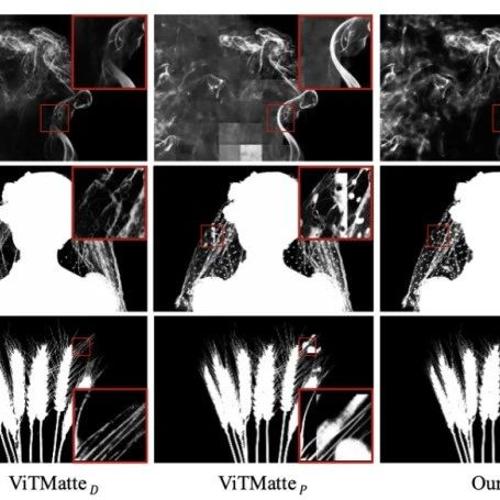
美图影像研究院(MT Lab)联合北京交通大学提出MEMatte方法,用于在显存受限的场景下进行高清图像的精细抠图。该方法通过双分支令牌路由设计显著降低模型计算开销,并在Nvidia GeForce 2080Ti上实现了4K分辨率图像抠图。
AAAI 2025 开放世界的深伪检测,北交大团队:解决好无配对数据挑战很重要

AIxiv专栏接收并发表了北京交通大学赵耀、陶仁帅团队的研究工作,提出了一种新的非配对数据下的开放世界深伪检测方法(ODDN),有效解决了社交媒体中配对数据稀缺和压缩影响带来的挑战。
北交开源o1代码版!强化学习+蒙特卡洛树搜索,源代码、精选数据集以及衍生模型通通开源
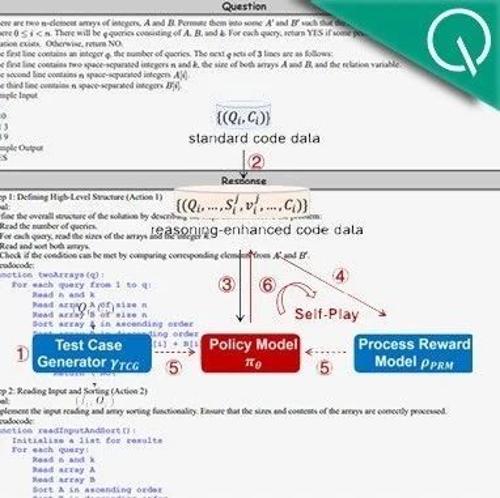
北京交通大学团队推出O1-CODER模型,专注于编码任务。该模型结合了强化学习与蒙特卡洛树搜索,显著提升了代码生成质量。研究发现,通过生成推理数据并优化策略模型,测试用例生成器的性能得到提升,平均采样通过率达到了89.2%。