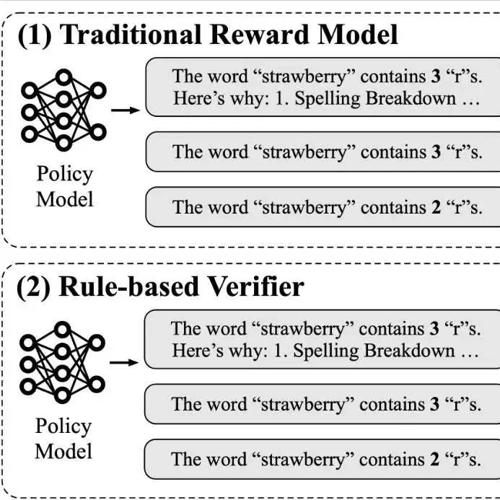
POLAR:开创性的奖励模型,为强化学习任务提供精准奖励信号 2025年7月10日8时 作者 NLP工程化 POLAR提出创新的奖励模型,通过大规模合成语料预训练生成高效策略区分模型,适用于多种场景并显著降低奖励劫持现象。