
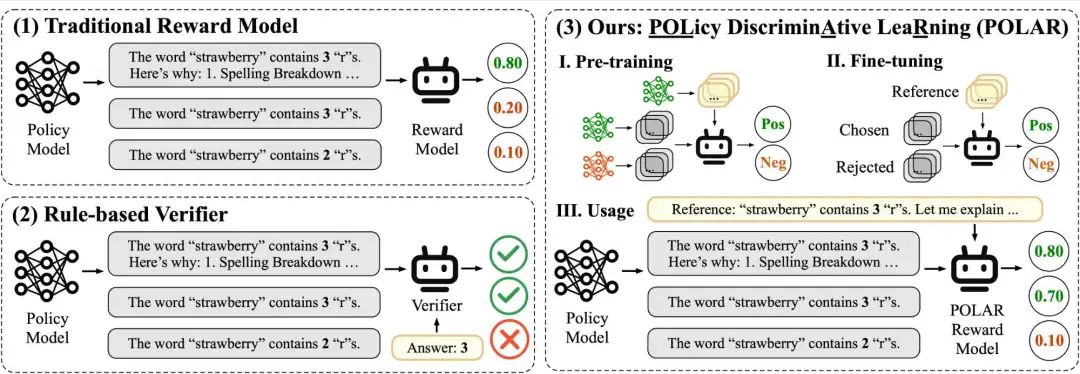
POLAR:开创性的奖励模型,为强化学习任务提供精准奖励信号。亮点:1. 创新预训练范式,通过大规模合成语料高效区分策略;2. 提供1.8B和7B参数的预训练模型,灵活适配多种场景;3. 在下游强化学习任务中表现卓越,显著降低奖励劫持现象。

参考文献:
[1] http://github.com/InternLM/POLAR
[2] https://huggingface.co/collections/internlm/polar-68693f829d2e83ac5e6e124a
[3] https://www.modelscope.cn/organization/Shanghai_AI_Laboratory
[4] https://arxiv.org/abs/2507.05197
知识星球:Dify源码剖析及答疑,Dify扩展系统源码,AI书籍课程|AI报告论文,公众号付费资料。加微信buxingtianxia21进NLP工程化资料群,以及Dify交流群。
(文:NLP工程化)