
开源
即将发布 QwQ-Max 的正式版本
Qwen发布了QwQ-Max-Preview模型,该模型基于Qwen2.5-Max推理模型,具有更强的数学理解、编码和代理能力。即将发布QwQ-Max正式版,并在Apache 2.0下开放源代码。
Claude 3.7 Sonnet信息卡:Claude 3.7 Sonnet 是一款混合推理模型

Claude 3.7 Sonnet 是一款混合推理模型,重点在于减少潜在伤害,通过训练和周边安全系统进行评估。
开源社区终于迎来PDF解析的”六边形战士”!百万页处理成本直降32倍!
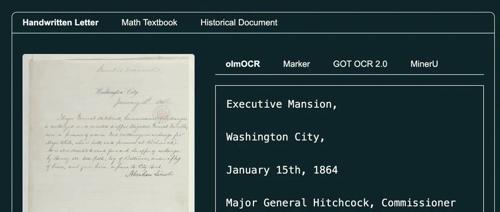
olmOCR 是由 Ai2 推出的新工具,通过 Qwen2-VL-7B-Instruct 进行训练,能高效准确地提取 PDF 文档中的纯文本,并以 Markdown 格式输出。它特别擅长处理复杂布局和手写内容,成本低且完全开源。
大模型处理PDF文档olmOCR,DeepSeek开源DeepGEMM高效的FP8矩阵乘法库,多模态推理R1-OneVision

本文介绍了五个AI工具包和模型,包括olmOCR用于处理PDF文档、DeepGEMM优化FP8矩阵乘法、R1-OneVision多模态大语言模型、Baichuan-Audio语音交互模型以及MyCoder AI编程工具。
Migician:清华、北大、华科重磅出击!多图像定位大模型,安防与自动驾驶的“破局者”
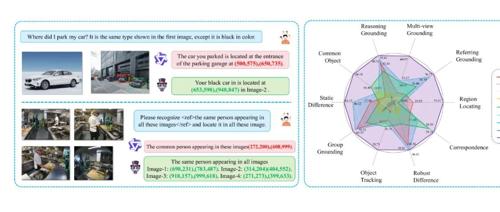
在人工智能飞速发展的背景下,清华大学联合实验室研发的Migician多模态视觉定位模型解决了复杂场景下的目标定位难题。该模型能结合文本描述和图像信息,在安防监控、自动驾驶、医疗影像分析及机器人具身智能等多个领域实现高效准确的目标定位,显著提升系统的感知与决策能力。
英伟达暴力优化DeepSeek R1,推理速度暴涨25倍!

英伟达推出DeepSeek R1在Blackwell架构上的优化,其推理性能提升了25倍,成本降低了20倍。通过使用FP4精度,DeepSeek-R1实现了更低的成本和更高的效率,可能带动API价格大幅下降。

阿里QwQ-Max-Preview:AI推理模型的“新标杆”
阿里巴巴Qwen团队发布了深度推理模型QwQ-Max-Preview,其在数学、编程及通用任务中表现出色,并支持联网搜索和思维链展示。该模型将开源,并推出Android和iOS应用程序,促进AI技术在全球范围内的传播和应用。