
学术


MiniMax-01 开源即精品:破解超长文本处理难题!

MiniMax-01系列模型开源,支持400W token长文本处理。该系列通过线性注意力机制大幅降低计算成本和提高效率。MiniMax-Text-01在文本任务与多模态任务上表现优异,展示了强大的超长文本理解和处理能力。
一个关于MoE的猜想
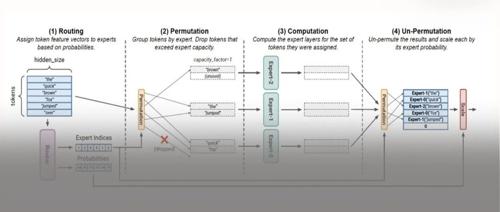
本文提出了关于如何演进MoE模型的猜想,主要是在MoE Routing的基础上再套一层构建The Mixure of Expert Group(MoEG)。文章从代数和范畴论的角度分析了MoE模型的结构,并探讨了通过两层Routing Gate来优化模型并行计算和通信效率的方法。




仅缩小视觉Token位置编码间隔,轻松让多模态大模型理解百万Token!清华大学,香港大学,上海AI Lab新突破

文章介绍了V2PE(Variable Vision Position Embedding),一种用于增强视觉-语言模型在长上下文场景表现的位置编码方法。通过实验验证了其有效性和优势,为视觉-语言模型的发展带来了新的机遇。
藏不住了!OpenAI的推理模型有时用中文「思考」

OpenAI 的 o1 模型在回答编码题时,开始使用中文思考。专家们提出了多种解释,包括训练数据的影响、语言选择的自然性以及模型自身的智能涌现等观点。