
 PaperWeekly
PaperWeekly

CVPR 2025录用结果出炉!这些方向杀疯了!
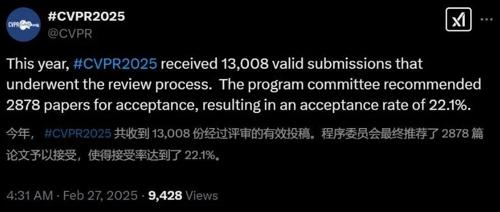
CVPR 2025录用结果出炉!今年共13008篇论文投稿,最终录取率仅为22.1%。大模型时代的研究方向集中在端到端、闭环仿真3DGS、多模态大模型和扩散模型等前沿领域。科研辅导服务帮助学生解决选题、实验设计、创新点设计等问题。
CVPR 2025录用结果出炉!今年共13008篇论文投稿,最终录取率仅为22.1%。大模型时代的研究方向集中在端到端、闭环仿真3DGS、多模态大模型和扩散模型等前沿领域。科研辅导服务帮助学生解决选题、实验设计、创新点设计等问题。







