GiantPandaCV
GiantPandaCV




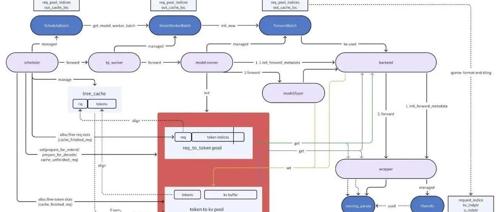
DeepSeek-V3 + SGLang: 推理优化 (v0.4.3.post2+sgl-kernel:0.0.3.post6)

DeepSeek V3 SGLang 优化
继续我们的DeepSeek V3与SGLang集成的技术


分享一个DeepSeek V3和R1中 Shared Experts和普通Experts融合的一个小技巧

R1 应用一个fuse shared experts到普通256个expert中的工作 (https