GiantPandaCV
GiantPandaCV

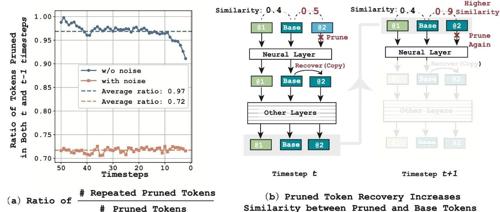
【Efficient AIGC】SiTo_ Similarity-based Token Pruning (AAAI-2025)
在这里插入图片描述
在这里插入图片描述
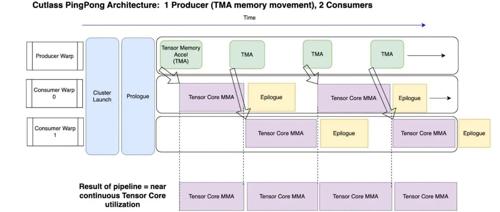
SiTo: Training-Free and Hardwa


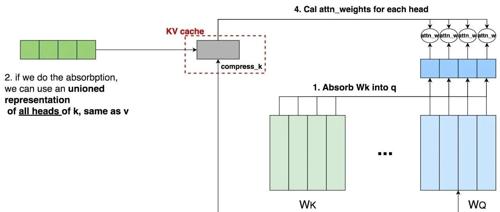
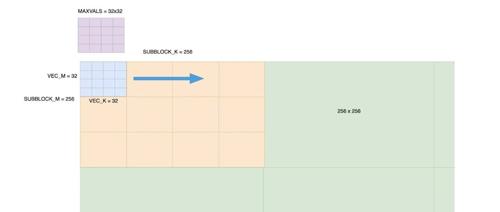
书生·浦语大模型升级,突破思维密度,4T数据训出高性能模型

上海人工智能实验室对书生大模型进行了升级,推出了InternLM3.0版本,通过精炼数据框架提升了数据效率和思维密度,节约了75%以上训练成本,并实现了常规对话与深度思考能力融合。