

今天是2025年8月8日,星期五,北京,雨
立秋之后,北京继续落雨了,有一种秋雨濛濛的感觉。
我们继续看技术方向,看几个点。
一个是文档ocr研发的手写体合成项目,怎么做合成数据是一个大方向,看一个工具。
一个是模态嵌入混排Benchmark,用来做多模态RAG中的评估。
一是前端界面代码转写模型ScreenCoder,这个也是多模态的范畴,也可以方向生成合成数据。
都是有趣的工作,可以看看。
一、文档ocr研发的手写体数据合成项目
线来看文档智能进展,手写体数据合成,这块是有开源项目的,在:https://github.com/saurabhdaware/text-to-handwriting,https://saurabhdaware.github.io/text-to-handwriting/**,可以自定义背景图,字体大小来合成。这类的,还有handright开源工具,https://github.com/Gsllchb/Handright,也可以指定背景去做。
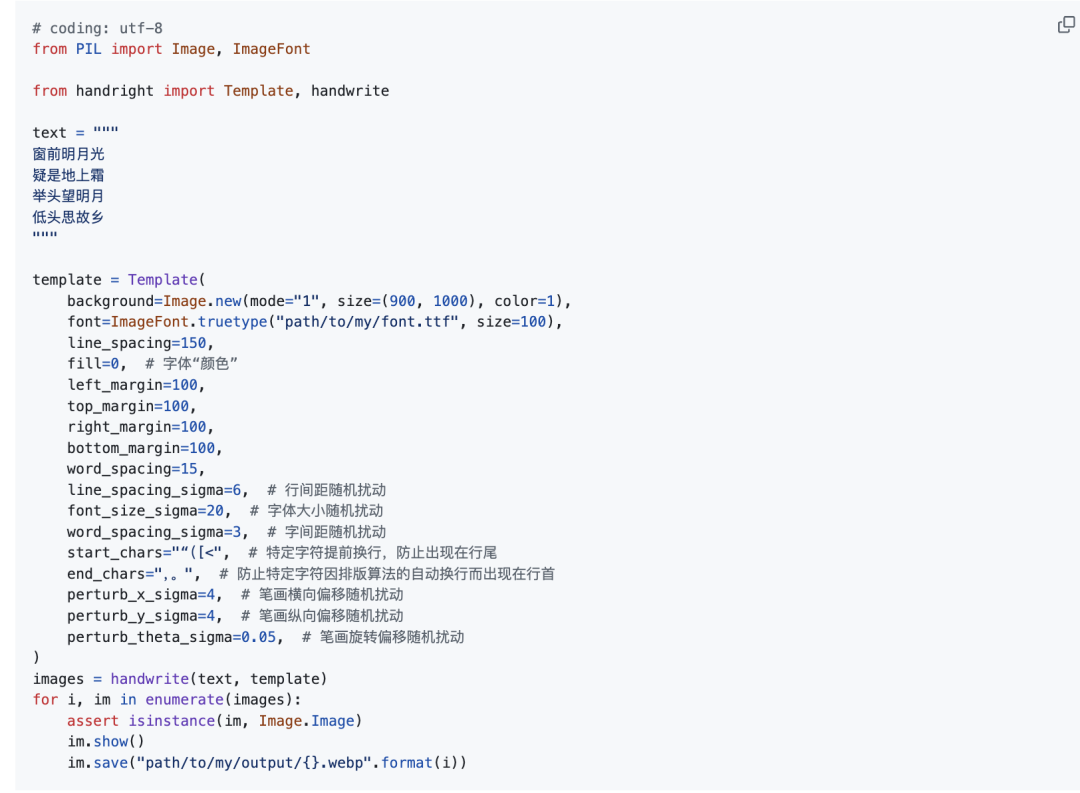
具体的操作可以见: https://github.com/Gsllchb/Handright/blob/master/docs/tutorial.md
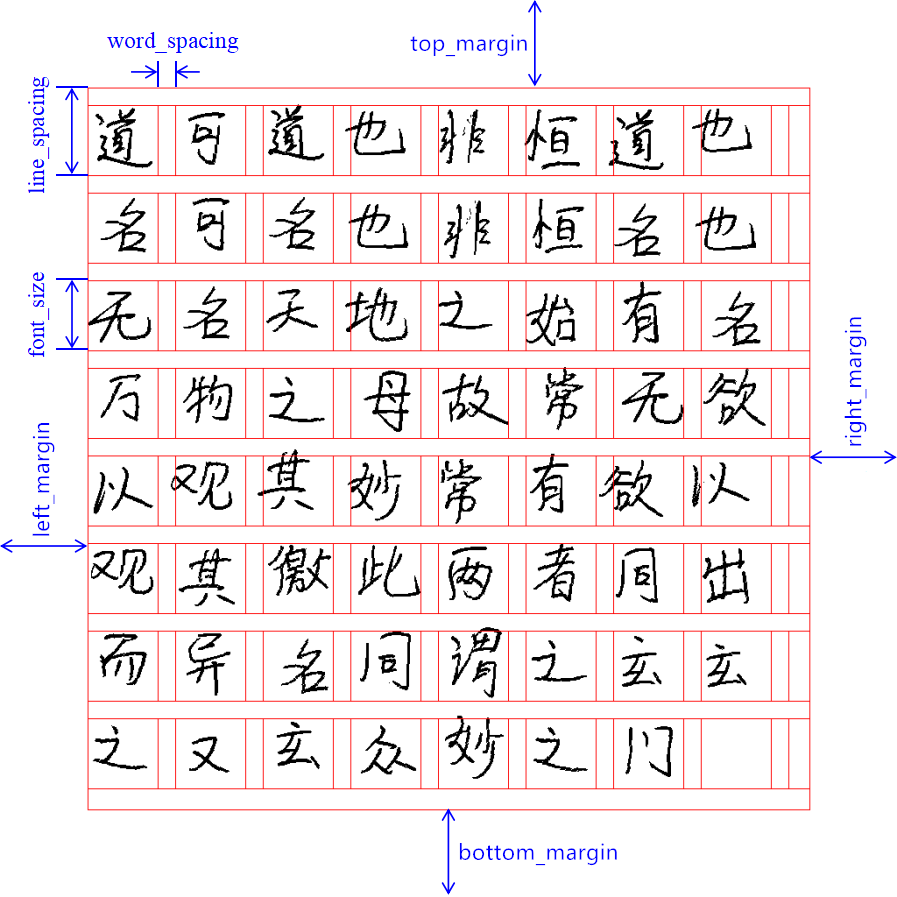
Handright建立于Pillow库之上,所以,核心点就是:背景图+手写字体ttf以及一些排版参数。
二、图文混排Benchmark
我们昨天在《再看多模态RAG中的代表Embedding:从ColPali、GME到ColQwen-Omni》,https://mp.weixin.qq.com/s/s3TiU2O9dFmg1vEeu20SzA中介绍了代表性的多模态嵌入问题。
而在真实场景中,还可以再做一下,也就是图文混排,目前大部分现有的文档检索基准(如MTEB)只考虑了纯文本。而一旦文档的关键信息蕴含在图表、截图、扫描件和手写标记中,这些基准就无能为力的问题。
因此,来看一个工作,inaVDR,图文混排文档搜索任务的基准集,https://jina.ai/news/jinavdr-new-visual-document-retrieval-benchmark-with-95-tasks-in-20-languages/,https://github.com/jina-ai/jina-vdr/,https://huggingface.co/collections/jinaai/jinavdr-visual-document-retrieval-684831c022c53b21c313b449,
在数据构建侧,收集了大量布局复杂的真实文档,来自多种语言,内部混合了图表、表格、文字和图像,文件类型也覆盖了从网页、屏幕截图、PDF 再到物理的扫描件,然后,为这些文档匹配了有针对性的文本查询。
具体执行效果,如下图所示:
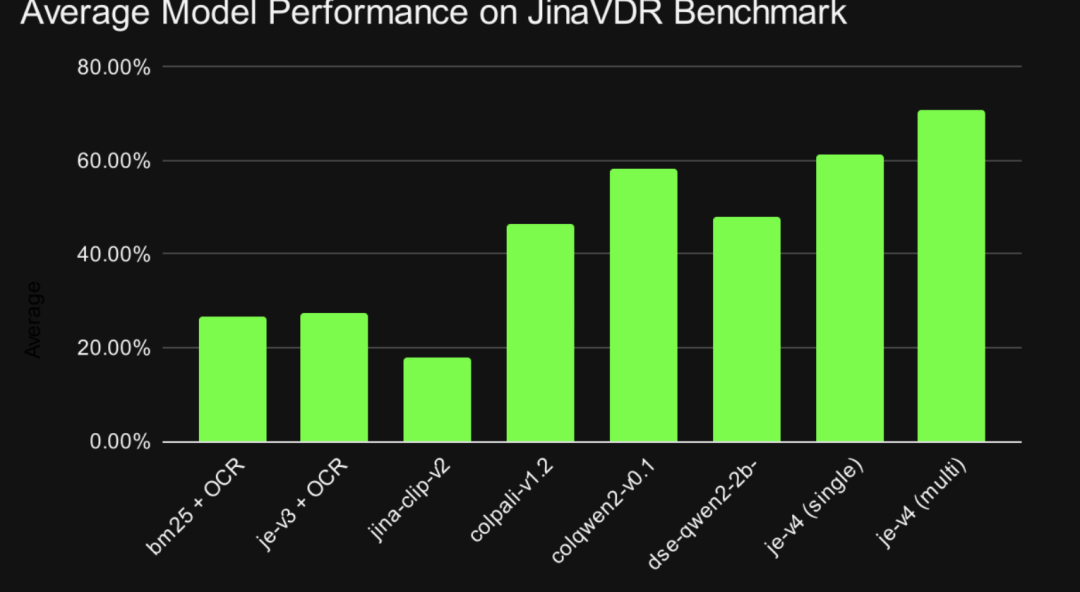 结果并不高。
结果并不高。
三、前端界面代码转写模型ScreenCoder
继续看前端界面代码转写模型进展,《ScreenCoder: Advancing Visual-to-Code Generation for Front-End Automation via Modular Multimodal Agents》,https://arxiv.org/pdf/2507.22827,https://github.com/leigest519/ScreenCoder,体验地址在https://huggingface.co/spaces/Jimmyzheng-10/ScreenCoder,是workflow传出来的一个逻辑,当然,也可以说是Agent,一个模块化多智能体框架。
从功能上看,将UI截图转换为可编辑的HTML/CSS代码,看一个具体的例子:
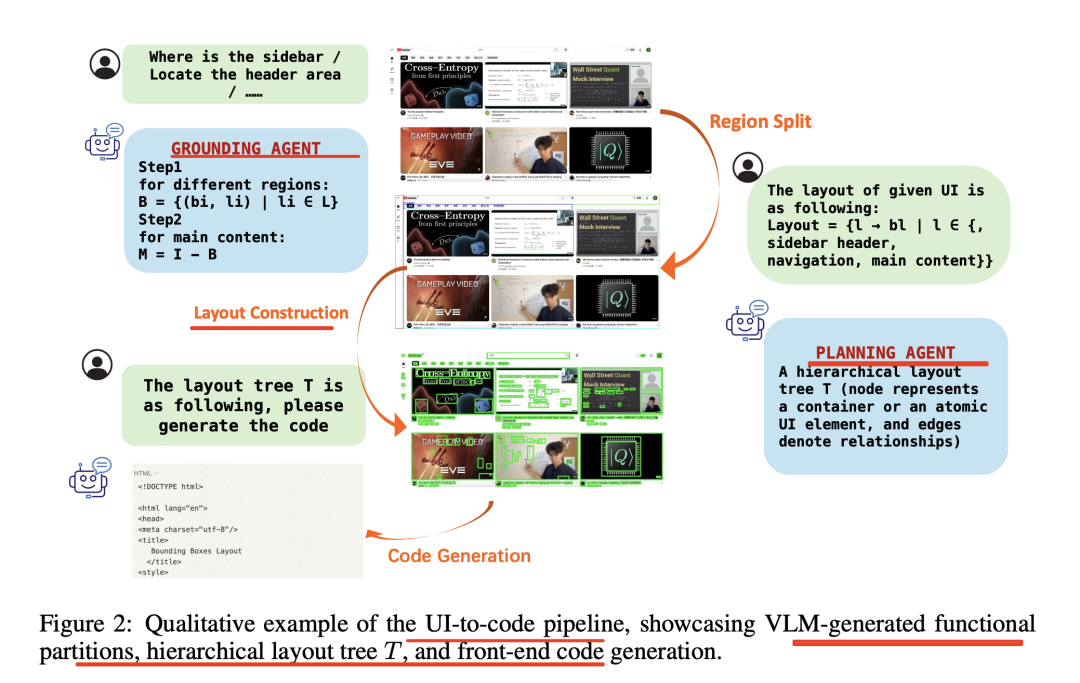
从流程上看,具体流程为:截图输入→UI元素检测→代码块生成→占位符替换→生成可用HTML/CSS,对应过去就是,将UI到代码的生成过程分解为三个可解释的阶段:定位(grounding)、规划(planning)和生成(generation)。
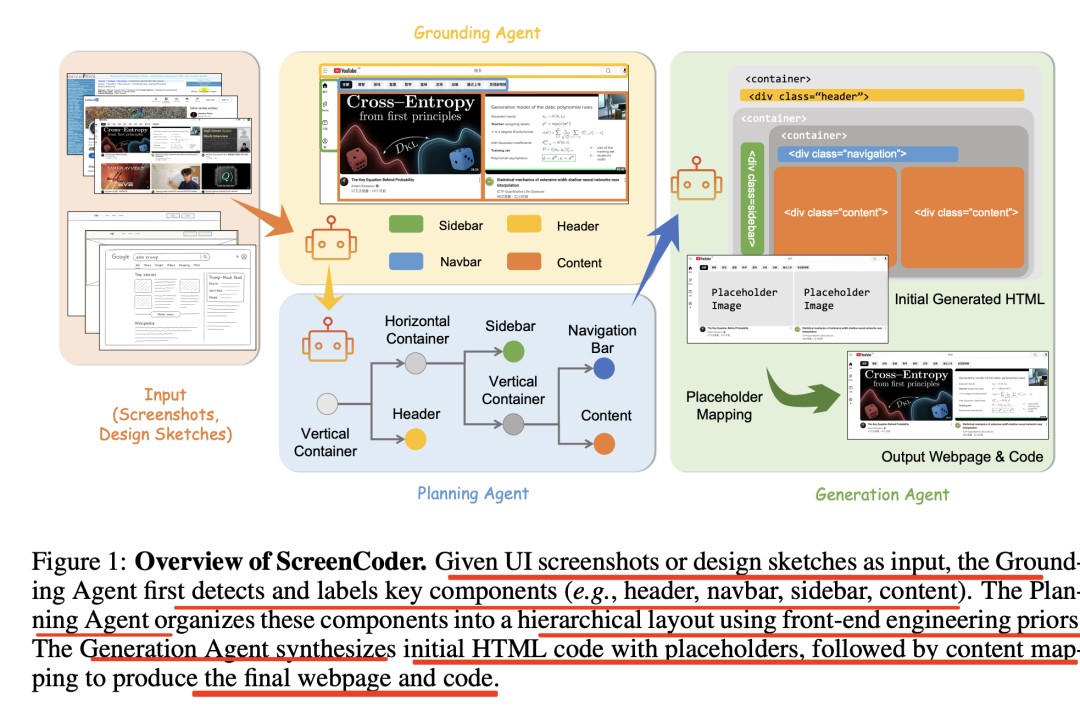
如上图所示:
定位智能体(Grounding Agent),使用视觉语言模型(VLM)检测和标记UI组件,为后续阶段提供语义标签和布局信息;
规划智能体(Planning Agent),根据前端工程的先验知识构建层次化布局,将定位阶段检测到的组件组织成树状结构;
生成智能体(Generation Agent),通过自适应提示合成HTML/CSS代码,结合布局上下文和用户指令生成代码。
但是,正如文首所说,其还可以用于数据合成,用于自动生成大规模图像-代码对,更改样式。
参考文献
1、https://github.com/Gsllchb/Handright
2、https://arxiv.org/pdf/2507.22827
3、https://jina.ai/news/jinavdr-new-visual-document-retrieval-benchmark-with-95-tasks-in-20-languages/
(文:老刘说NLP)