
今天凌晨1点30,OpenAI开源了大模型GPT-oss,一共有1200亿和200亿两种参数,支持Apache 2.0商业化。
GPT-oss针对AI Agent进行了特殊训练,支持函数调用、网络搜索、Python执行等功能,可帮助用户快速开发各种安全、功能强大的智能体。
GPT-oss-120B的测试数据可与o4-mini媲美,但需要80GB GPU才能运行;GPT-oss-20B可媲美o3-mini,配置则要求很低,16GB就能使用。
根据OpenAI公布的模型数据显示,OpenAI为了训练GPT-oss,在英伟达H100上训练了超过200万小时,也是目前开源模型中消耗训练时间最多的模型之一。
开源地址:https://github.com/openai/GPT-oss
https://huggingface.co/openai/GPT-oss-120b
OpenAI联合创始人兼首席执行官Sam Altman特意发长文解读了GPT-oss模型。
GPT-oss意义重大,这是一款最先进的开放权重推理模型,在现实世界中性能强劲,可与o4-mini相媲美,而且你可以在自己的电脑上本地运行(较小规模的版本甚至可以在手机上运行)。我们认为这是世界上最出色、最易用的开放模型。
我们很荣幸能将这款凝聚了数十亿美元研究成果的模型推向世界,让尽可能多的人接触到人工智能。我们相信其带来的益处将远大于潜在的弊端。
例如,在复杂的健康问题上,GPT-oss-120b的表现与o3不相上下。我们已全力以赴缓解最严重的安全问题,尤其是生物安全方面的问题。在内部安全基准测试中,GPT-oss模型的表现与我们的前沿模型相当。
我们秉持个人赋能的理念。尽管我们认为大多数人会希望使用像ChatGPT这样便捷的服务,但人们在有需要时,应该能够直接控制和修改自己的人工智能,其隐私方面的优势显而易见。
与此同时,我们对此次发布满怀期待,希望它能催生新型研究和新型产品。我们预计,这一领域的创新速度将显著加快,而且能够开展重要工作的人也会比以往多得多。
OpenAI的使命是确保AGI造福全人类。为此,我们为世界能在一个基于美国创造的、以民主价值观为基础的开放人工智能技术栈上进行开发而感到兴奋,这一技术栈免费向所有人开放,旨在带来广泛的益处。

OpenAI开放这么强的大模型大家都很开心,但是Altman说20B的可以在手机上运行???让人持怀疑态度。
网友表示,我看到 20B 版本需要 16GB GPU,那怎么能在普通手机上运行呢?

估计这样的手机可以使用。
感谢Sam和OpenAI的所有人员,是你们赋予了我们这种超强能力。
市场迫使 OpenAI 进行开源,而他们正通过这种渲染,让这听起来像是为了人类才这么做。这只不过是这个很可能由赢家通吃的行业中又一个竞争性举措而已。
发布一款与o4-mini相当的开源推理模型意义重大。这本质上是将最先进的小型模型开源给了全世界。
Grok-2、Grok-3的开源在哪里?这下马斯克撒谎了吧?
这意义重大。我们正在实时见证一次战略性转变。开源运动刚刚获得了最大的认可。整个行业的行事准则正在被改写。
GPT-oss架构简单介绍
GPT-oss-120b是一个混合专家(MoE)模型由36层组成,总参数量达到1168亿,其中每token前向传递中活跃的参数为51 亿。相比之下,GPT-oss-20b 模型则由24层组成,总参数量为 209 亿,每 token 前向传递中活跃的参数为36亿。这种参数分布使得模型在处理复杂任务时能够更高效地分配计算资源,同时保持较高的性能表现。
GPT-oss模型的核心架构之一是MoE模块。每个 MoE 模块包含固定数量的专家,这些专家负责处理不同的输入特征。GPT-oss-120b模型的每个 MoE 模块包含 128 个专家,而GPT-oss-20b 模型的每个 MoE 模块包含 32 个专家。这些专家通过一个标准的线性路由器投影进行选择,该投影将残差激活映射到每个专家的分数。
在前向传递过程中,模型会根据路由器投影的分数选择每个 token 的前4个专家,并按路由器投影的softmax 权重对专家输出进行加权。这种设计使得模型能够根据输入数据的复杂性动态分配计算资源,从而提高处理效率和性能表现。
GPT-oss模型的注意力模块设计借鉴了 GPT-3 的架构。注意力模块在带状窗口和全密集模式之间交替,带宽为 128 个 token。这种交替模式使得模型能够在处理长序列数据时保持较高的效率和性能表现。
每层注意力模块包含 64 个查询头,每个头的维度为 64,并使用分组查询注意力技术,其中键值头数量为8。模型还应用了旋转位置嵌入(RoPE)技术,并通过 YaRN 技术将密集层的上下文长度扩展到131072 个 token。这些技术的应用显著提高了模型在处理长序列数据时的能力。
在归一化和激活函数方面,GPT-oss模型采用了根均方归一化技术。模型在每个注意力和MoE 模块之前应用 RMSNorm,以确保输入数据的分布一致性。此外,模型还使用了门控 SwiGLU 激活函数。这种激活函数的设计旨在提高模型的非线性能力和表达能力,从而更好地处理复杂的输入数据。
根据GPT-oss的测试数据显示,其推理、工具调用能力非常出色,可媲美OpenAI的前沿模型o4-mini。
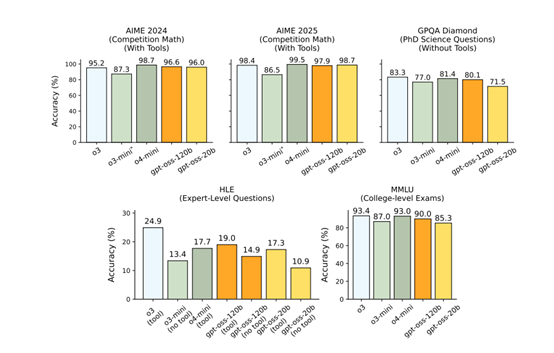
例如,在 AIME美国数学邀请赛测试中,GPT-oss-120b 模型在高推理模式下达到了 96.6% 的准确率,接近o4-mini 的 98.7%;在编程领域,GPT-oss 模型在 Codeforces 编程竞赛问题的测试中,120b 模型的 Elo 评分达到了 2622,接近o4-mini的 2719。
此外,在多语言能力测试中,GPT-oss-120b 模型在法语、德语和西班牙语等语言的测试中,高推理模式下的准确率分别达到了84.6%、83.0% 和 85.9%,表明其在多语言任务上的强大适应性。
(文:AIGC开放社区)