


新智元报道
新智元报道
【新智元导读】当前大模型在最基础的感知、物理常识等12项核心认知上普遍落后人类10-30%,且越大的模型越容易靠「背答案」糊弄,真正掌握核心知识的极少。团队公开首个系统评测框架和题库,呼吁先把「三岁孩子都懂」的常识打牢,再谈更高层的智能。
最近,一篇被Yann LeCun转发的ICML 2025研究结果显示,在CoreCognition基准1,503题大考中,230个主流模型纷纷暴露对于世界模型的「常识性盲区」。
再大的多模态语言模型,也缺少人类婴儿就有的「核心知识」地基,即使高层推理再花哨,也架不住地基塌陷。
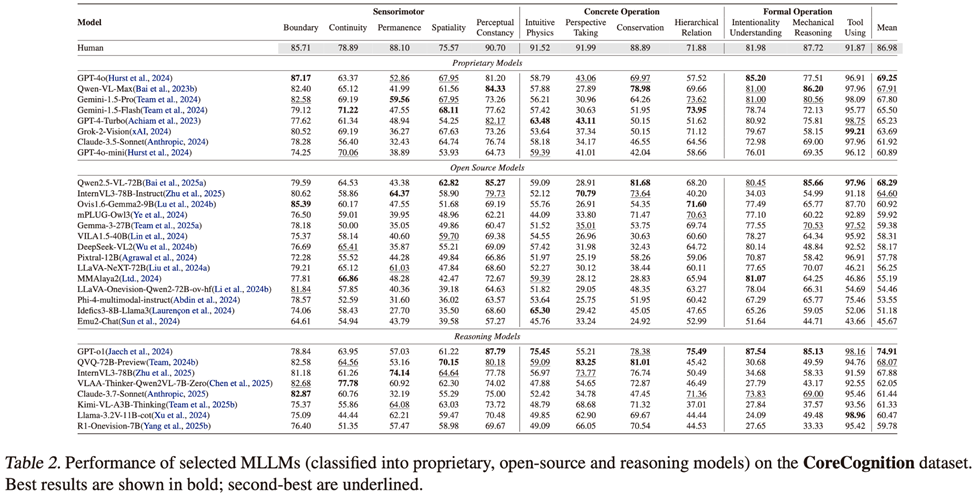
从下面这张震撼的对比表中,我们可以看到模型在12项「幼儿园」测试中,集体翻车。
-
Object Permanence:人类88.1%,最强模型InternVL3-78B仅74.1%,差距14%;
-
Perspective Taking:人类91.99%,最强模型QVQ-72B-Preview也仅83.25%,差距9%;
-
Intuitive Physics:人类91.52%,最强模型GPT-o1仅75.45%,差距超16%,各大模型普遍落后10-30%不等。
来自加州大学圣地亚哥分校、约翰霍普金斯大学、埃默里大学、北卡罗来纳大学教堂山分校、斯坦福大学、卡内基梅隆大学等机构的研究人员联合认知科学领域科学家,花费一年时间构造并开源了业界首个核心认知基准CoreCognition。
其中包含1,503道精选题目从感知运动到形式运算12项核心能力,每个概念95+样本,全面覆盖人类认知各个发展阶段。

论文链接:https://arxiv.org/pdf/2410.10855
项目网站:https://williamium3000.github.io/core-knowledge/
开源数据集:https://huggingface.co/datasets/williamium/CoreCognition
此外,联合团队还维持了三个高标准:
-
判别性(缺乏目标核心知识的模型必然选错答案)
-
最小混淆(避免依赖物体识别等无关能力)
-
最小文本捷径(答案不能仅通过文本推导获得)
12名标注员协作完成数据集构建,经过双轮交叉验证和20人Amazon Mechanical Turk人工校验。
230个模型大考,涵盖GPT、Claude、Qwen等主流商业模型及开源模型;11种提示策略,全方位测试模型真实能力。
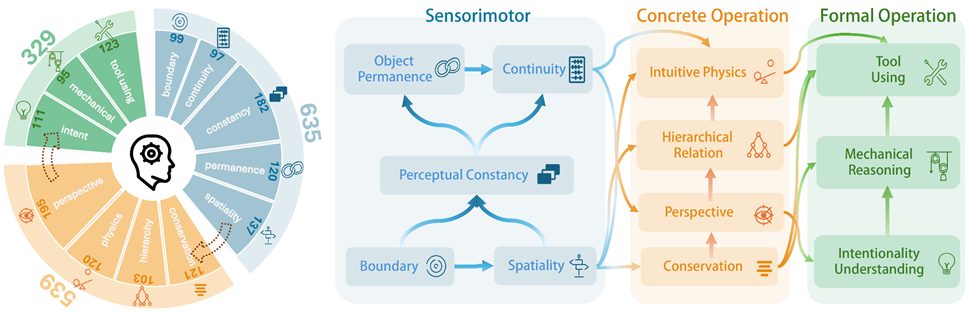
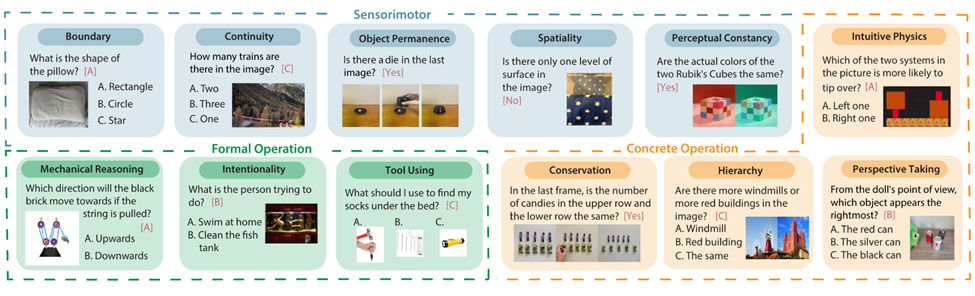
据悉,团队不仅构建了均衡答案位置和混合答案解析的完整评测基础设施,而且还计划开源一个支持这230个模型的MLLM统一测试框架,亮点是极易上手。
只需几行代码就能复现本文章及其他热门数据的全部实验结果!

更绝的是团队独创的Concept Hacking方法,专门用来识破模型是「真懂」还是「假懂」
核心思路:给每道题做一个保持所有无关细节完全相同,只把核心概念反转的「孪生题」
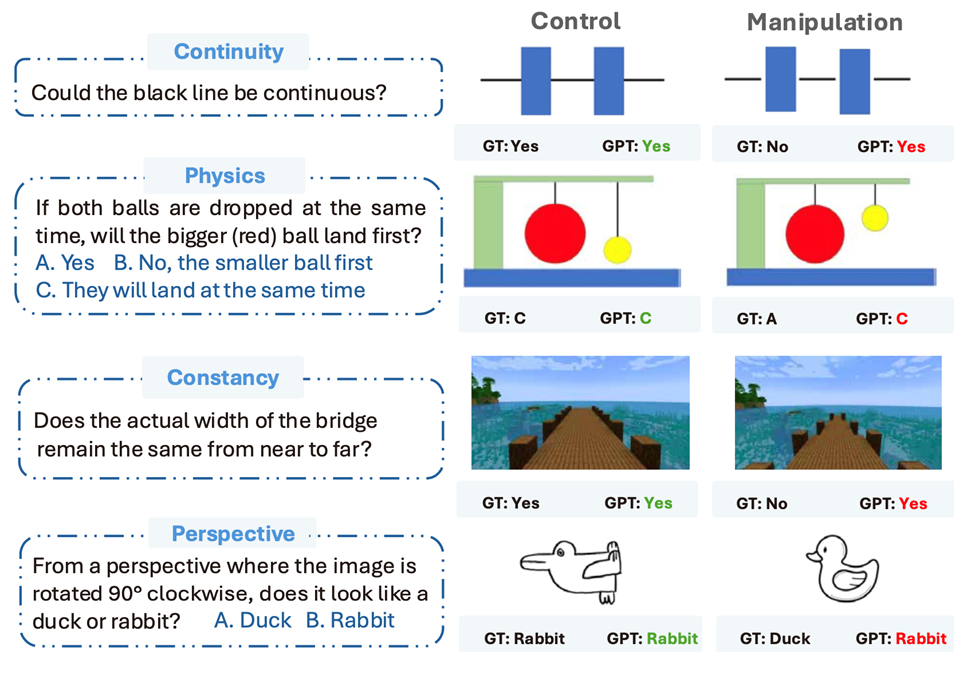
-
原版题:图像顺时针旋转90°后,看起来像鸭子还是兔子?→ 测试真正的perspective taking转换理解
-
孪生版:同样的旋转操作,但正确答案相反 → 测试是否只是在套用固定模板
-
人类表现:两题都答对(真正理解空间旋转后的形状变化)
-
模型表现:原版答对,孪生版直接翻车(暴露对「鸭兔错觉」的刻板印象依赖)

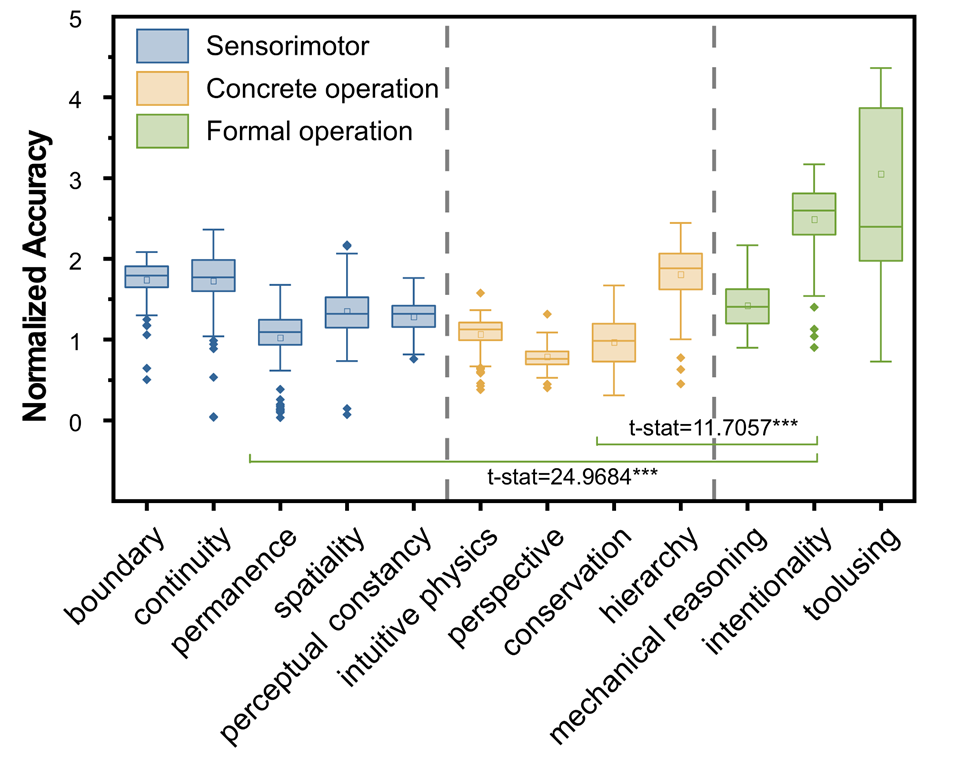
实验里,模型在低阶任务上集体表现不佳。这说明它们的高级推理/感知没有扎根于人类婴幼儿就具备的核心知识。面对不同表述方式和背景变化时无法表现出robust且稳定高水平的能力。
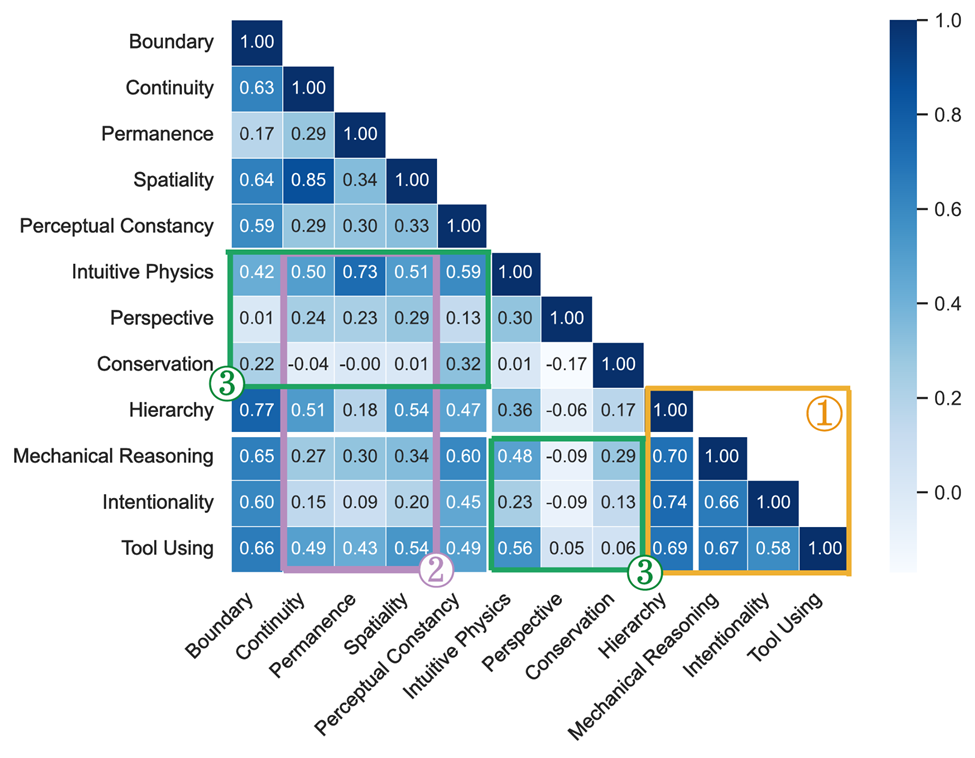
关联性矩阵显示了模型能力间的「分裂」现象:低阶能力如Permanence、Continuity与对应高阶能力如Perspective Taking、Conservation几乎零相关。人类认知发展是下层搭积木,上层盖高楼,层层递进;
模型现状是高楼直接悬空,缺乏发育链条支撑。这种能力间的断裂意味着任何基础认知的扰动,都可能让整个「智能大厦」瞬间散架。
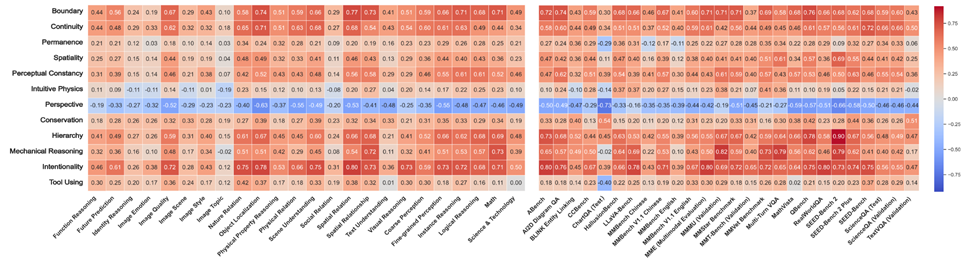
统计发现,除了Perspective和 Intuitive Physics,10项核心能力得分与26个公开基准(除了偏向检验OCR能力的ChartQA)强正相关。
换句话说:核心知识越好,高层任务越稳。
而作为人类高级推理的基础Perspective和Intuitive Physics能力,在基准测试评估结果中展现的低相关性,与我们之前在关系矩阵中观察到的结果一致,正是核心知识缺陷的体现。
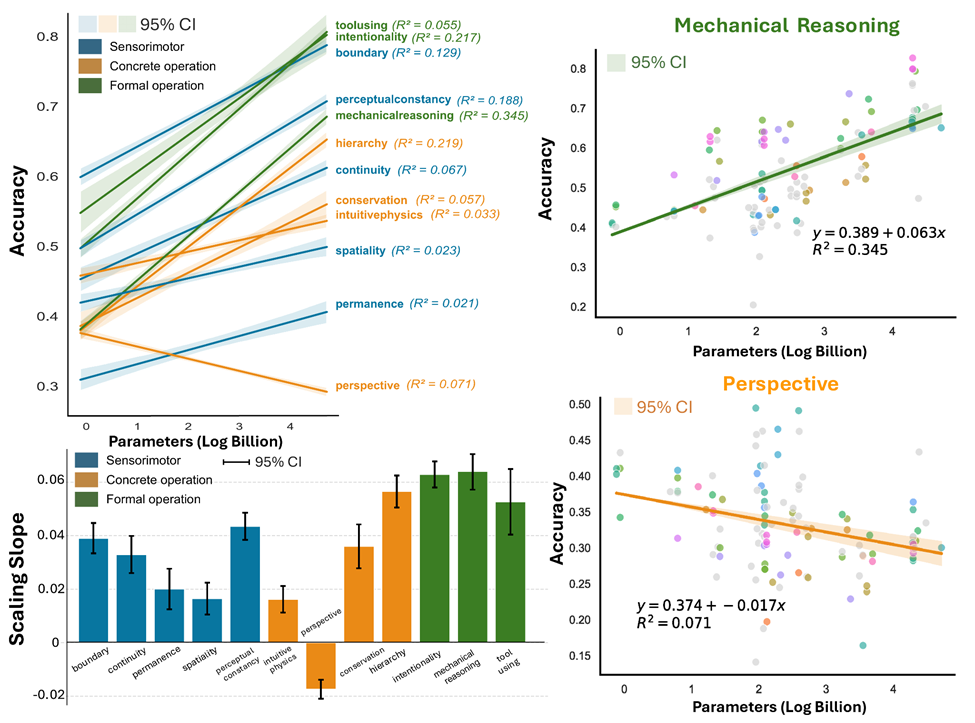
把219个模型从1B拉到110B,低阶能力曲线几乎一条水平线;perspective taking甚至随规模下降。
过往「大力出奇迹」的经验,在核心知识面前直接失灵。一个尚未解决却又可能帮助构建世界模型的关键课题是从「如何scale」变成「如何scale出core-knowledge」。
Finding 5:规模越大,捷径越香
Concept Hacking结果显示:大模型在孪生题上的表现相对小模型整体并无提升,甚至有些更加糟糕,说明scaling无法解决在核心知识问题上的「捷径依赖」。
直观感受:模型不是「长大变聪明」,而是长大变滑头。
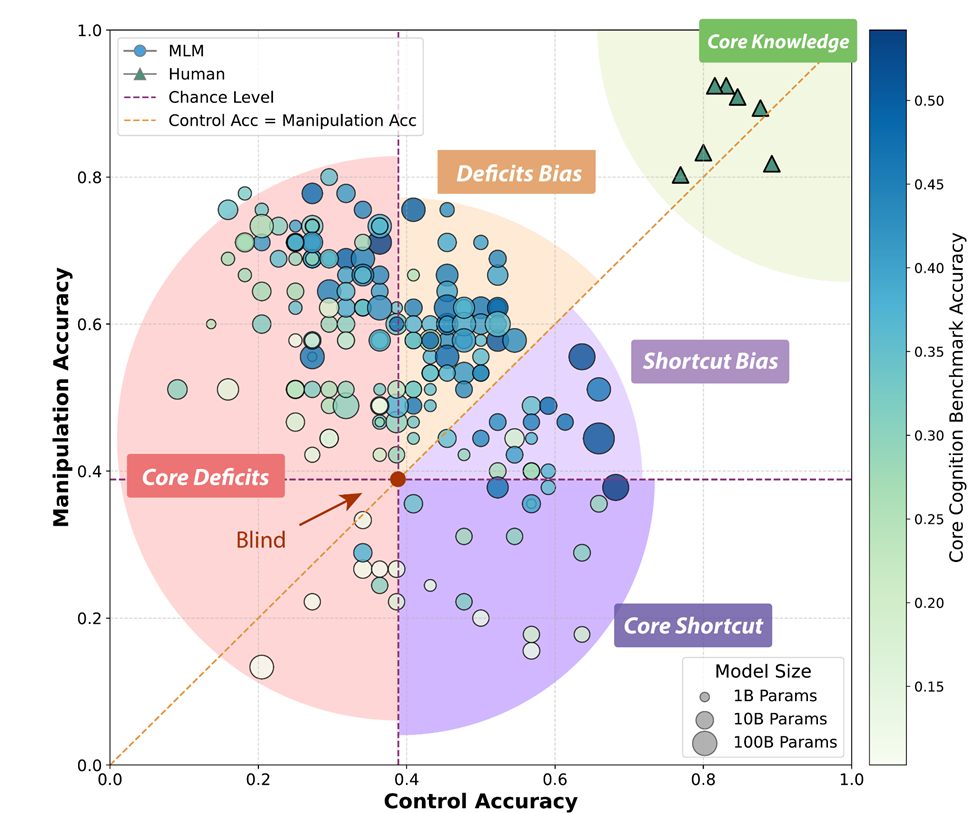
通过定量分析发现,模型可以分为四类:
-
核心知识型:控制题和操作题都答对(接近人类,但数量极少)
-
捷径依赖型:控制题对,操作题错(最常见,包括GPT-4o等明星模型)
-
核心缺陷型:控制题就答错,操作题表现无意义
-
盲猜型:两题都靠运气
推理增强也救不了(10/12 任务无提升):问题不在「用没用好」,而在「底子有没有」,「预训练缺失」仍是最大嫌疑。
有趣的是,团队发现认知指令提示——直接告诉模型「这是perspective taking任务」等概念描述,可瞬间带来6%的性能提升,表明模型内部可能已经分布式地存储了相关知识,但缺乏有效的检索和调用机制。
然而,这种方法在实际应用中局限性明显,因为现实场景中模型不太可能获得如此明确的概念指导。
更令人担忧的是,这种核心知识缺陷可能在关键应用中带来风险:比如自动驾驶中对遮挡物体的理解偏差,或者机器人在复杂场景下的物理常识判断失误。
从「写诗作画」到「常识翻车」,这项研究再次提醒我们:真正的智能,不只是参数规模,更是对世界最朴素、最基础的理解。
当我们惊叹于大模型在高阶任务上的神奇表现时,是否忽略了连三岁孩子都懂的常识?忽略了正在悄悄放大的低阶核心知识空洞?
规模、推理、提示,都只是裱糊匠——地基没打好,楼越高越危险。
或许,这正是我们重新思考AI发展路径的契机:不是一味追求更大、更强,而是回到最初——那些让人类智能如此稳健可靠的核心认知能力。
(文:新智元)