

机器之心编辑部
刚刚,腾讯混元团队宣布一口气开源了 4 款小模型 —— 最大的只有 7B,另外还包括 4B、1.8B 和 0.5B 三个型号。

这些小语言模型使用「消费级显卡即可运行,适用于笔记本电脑、手机、智能座舱、智能家居等低功耗场景,且支持垂直领域低成本微调。」
目前,这四个模型已在 GitHub 和 HuggingFace 上线。腾讯混元团队表示,ARM、高通、英特尔、联发科技等多个消费级终端芯片平台也都宣布支持部署这些模型。
GitHub:
-
Hunyuan-0.5B:GitHub – Tencent-Hunyuan/Hunyuan-0.5B
-
Hunyuan-1.8B:https://github.com/Tencent-Hunyuan/Hunyuan-1.8B
-
Hunyuan-4B:https://github.com/Tencent-Hunyuan/Hunyuan-4B
-
Hunyuan-7B:https://github.com/Tencent-Hunyuan/Hunyuan-7B
Hugging Face:
-
Hunyuan-0.5B:https://huggingface.co/tencent/Hunyuan-0.5B-Instruct
-
Hunyuan-1.8B:https://huggingface.co/tencent/Hunyuan-1.8B-Instruct
-
Hunyuan-4B:https://huggingface.co/tencent/Hunyuan-4B-Instruct
-
Hunyuan-7B:https://huggingface.co/tencent/Hunyuan-7B-Instruct
更重要的是,这 4 个开源模型的特点不仅是小,而且还都属于融合推理模型,具备推理速度快、性价比高的特点,用户可根据使用场景灵活选择模型思考模式:
-
快思考(fast thinking)模式提供简洁、高效的输出;
-
慢思考(slow thinking)涉及解决复杂问题,具备更全面的推理步骤。
效果上,四个模型均实现了跟业界同尺寸模型的对标,特别是在语言理解、数学、推理等领域有出色表现,在多个公开测试集上得分达到了领先水平。
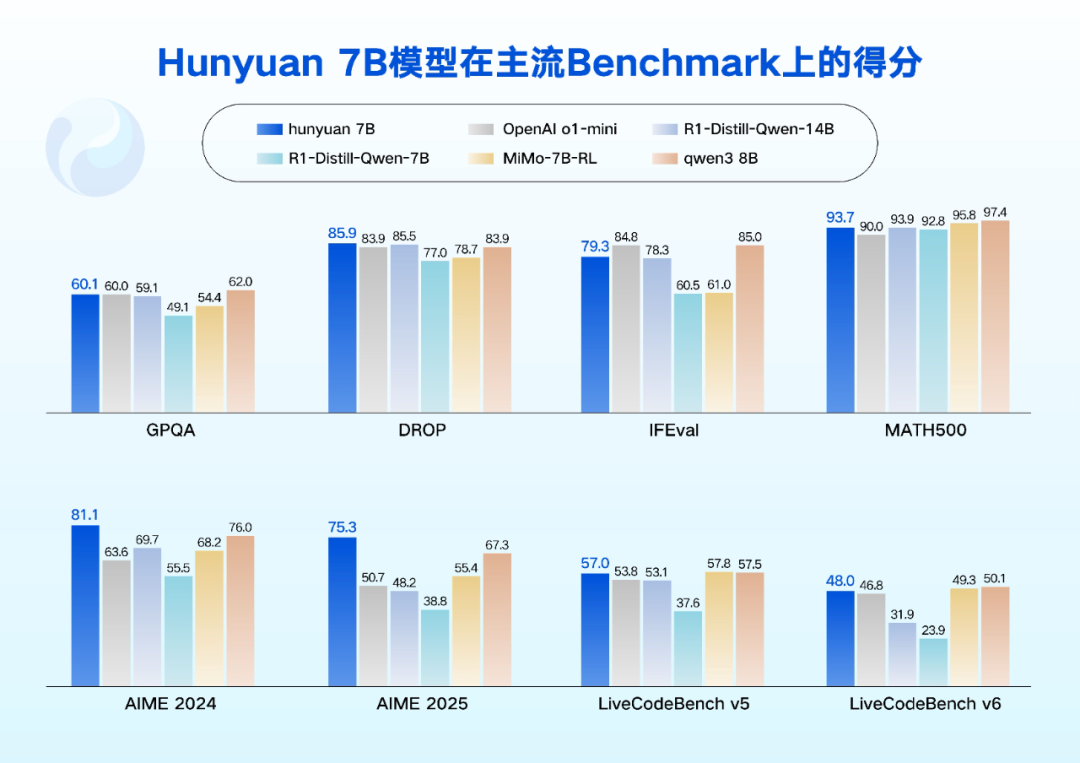
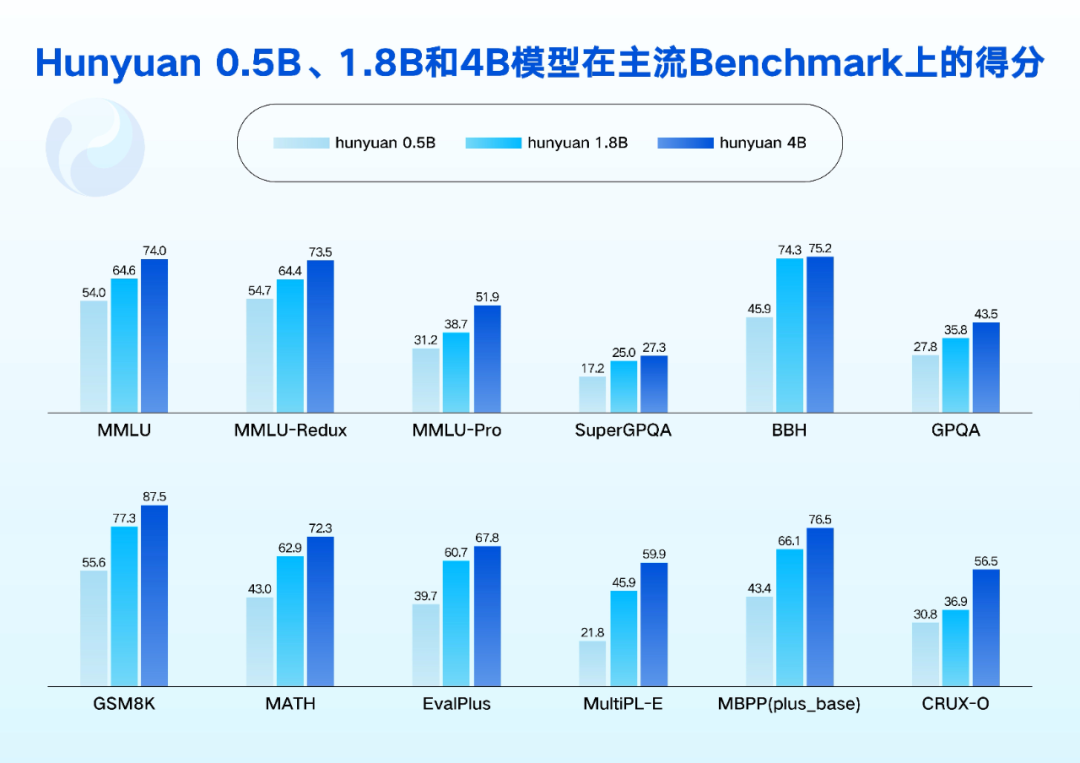
腾讯混元表示,这四个模型的亮点在于 agent 和长文能力。跟此前开源的 Hunyuan-A13B 模型一样,技术上通过精心的数据构建和强化学习奖励信号设计,提升了模型在任务规划、工具调用和复杂决策以及反思等 agent 能力上的表现,让模型实际应用中可以轻松胜任深度搜索、电子表格操作、旅行攻略规划等任务。
此外,模型原生长上下文窗口达到了 256k,意味着模型可以一次性记住并处理相当于 40 万中文汉字或 50 万英文单词的超长内容,相当于一口气读完 3 本《哈利波特》小说 ,并且能记住所有人物关系、剧情细节,还能根据这些内容讨论后续故事发展。
部署上,四个模型均只需单卡即可部署,部分 PC、手机、平板等设备可直接接入。并且,模型具有较强的开放性,主流推理框架(例如,SGLang,vLLM 和 TensorRT-LLM)和多种量化格式均能够支持。
机器之心也做了简单的尝试,其整体表现相当不错。

体验地址:https://hunyuan.tencent.com/modelSquare/home/list
已落地多元业务场景
腾讯透露,该系列模型已在内部多个核心业务中「身经百战」,其可用性和实用性得到了充分检验:
-
生产力工具:腾讯会议 AI 小助手、微信读书 AI 问书等,利用其超长上下文能力,实现对万字会议纪要、全本图书的精准理解和摘要。
-
端侧应用:腾讯手机管家利用小模型实现毫秒级的垃圾短信精准拦截,且全程保护用户隐私(隐私零上传);腾讯智能座舱则通过双模型协作架构,解决了车载环境的功耗与响应难题。
-
高并发场景:搜狗输入法、腾讯地图、微信输入法「问 AI」等产品,借助模型的快速推理和意图识别能力,显著提升了嘈杂环境下的识别准确率和用户交互体验。
-
垂直行业:在金融领域,AI 助手通过少量微调即可实现超过 95% 的意图识别准确率;在游戏领域,《QQ 飞车》手游的 NPC 对话、多语言及方言翻译也因模型的加持而变得更加智能和流畅。
中国 AI 开源浪潮中的腾讯布局
「小语言模型是智能体 AI 的未来。」—— 英伟达近期的研究《Small Language Models are the Future of Agentic AI》似乎为腾讯此次的开源行动写下了最好的注脚。
众所周知,最近的开源 AI 模型可以说是异常热闹,来自中国的玩家们已经掀起了好几股热潮。而腾讯混元也是其中一大主要「弄潮儿」,其开源模型已覆盖文本、图像、视频和 3D 生成等多个模态。
腾讯混元此前已经陆续开源了激活参数量达 52B(总参数量 389B)的 Hunyuan Large 和首个混合推理 MoE 模型 Hunyuan-A13B,这些模型凭借架构上的创新以及在性能和效果上的不错表现,在开源社区受到广泛关注。
多模态方面,混元还开放了完整多模态生成能力及工具集插件,陆续开源了业界领先的文生图、视频生成和 3D 生成能力,提供接近商业模型性能的开源基座,方便社区基于业务和使用场景定制,图像、视频衍生模型数量达到 3000 个。
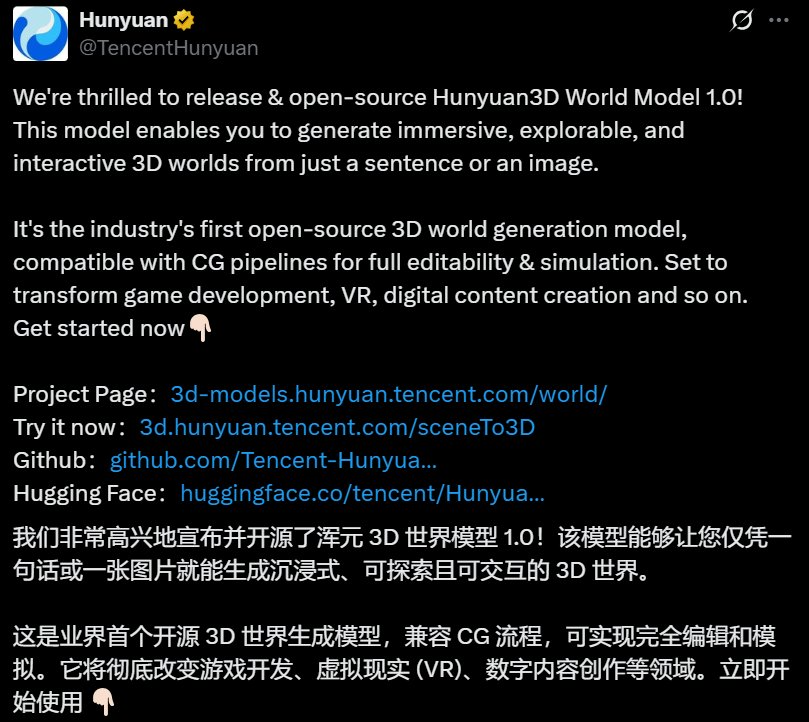
上周,腾讯发布并开源混元 3D 世界模型 1.0,这一模型一经发布即迅速登上 Hugging Face 趋势榜第二,下载量飙到近 9k,混元 3D 世界模型技术报告还拿下了 Hugging Face 论文热榜第一。
很显然,不管是科技巨头,还是创业公司,中国的 AI 模型开发者们都越来越喜欢开源了,甚至可以说已经成为一种共识。你觉得这一趋势背后的原因是什么呢?
(文:机器之心)