

Anthropic CEO Dario Amodei 在最新的采访中声称:几年内将出现月费10万美元的AI模型,支持1亿词上下文窗口。
这个预测确实有些惊人,但也并不是完全为了忽悠投资人,而是AI 正在进入前所未有的推理时间扩展阶段。
Dario Amodei 在采访透露:
「模型实际上会在上下文窗口中学习,而不改变权重。」

如果你有一些机器学习的基本知识,就会感觉这听起来似乎有些违背常理——
在神经网络尤其是LLM的学习中,「学习」通常是意味着通过梯度下降并更新权重,怎么权重不变时还能继续学习呢?
Hinton 老爷子可能都得表示好奇啊!

这就很有必要来说下Google Research 上周发布的一篇题为《Learning without training: Then implicit dynamics of in-context learning》的最新论文了,它正好解释了为什么这种超长上下文成为可能:
LLM能在不改变权重的情况下,通过「临时便签」机制实现真正的学习。

也许Dario 是在采访前刚看完了Google Research 这篇论文吧
下面,我们就一起来看看这篇论文讲了什么。
临时便签机制
这里我们用个好理解的临时便签来做例子。
想象一下,你平时做饭手艺超高且喜欢加麻加辣,但有天你家里来了位不能吃辣的美女说要尝尝你的手艺……
你自然不会直接把先前天天用的菜谱直接撕个粉碎再临时重新制作一个(毕竟没准下次来的就是个川妹子了呢),而是在「加五勺辣椒」的地方贴上「不放辣椒」的便签做临时标记。
LLM的上下文学习也是这样工作的。

研究团队发现了一个优雅的数学机制:
第一步:上下文通过自注意力层
当你输入提示词和上下文时,自注意力层会产生两种输出:
-
A(x):只有查询x时的输出
-
A(C,x):有上下文C和查询x时的输出
这两者的差异 ΔA = A(C,x) – A(x) 就包含了上下文的所有信息。
第二步:数学等价转换
论文的核心发现是,当这个差异ΔA经过MLP层时,整个计算在数学上等价于给MLP的权重矩阵W加上了一个rank 1的「便签」ΔW。
这个便签的公式是:
ΔW = (W·ΔA)·A(x)ᵀ / ||A(x)||²
而为什么rank 1 会如此重要呢?

我们想象一个4096×4096的权重矩阵,需要约1700万个数字存储。但rank 1更新只需要两个4096维的行向量+列向量,约8000个数字——
足足缩小了2000倍!
第三步:等价性的神奇之处
虽然实际计算时模型仍使用原始权重W和完整输入[C,x],但论文证明了:
使用原始权重W + 输入[C,x] = 使用更新权重(W+ΔW) + 仅输入x
这就意味着上下文的全部作用被「压缩」进了权重更新ΔW中。
一旦前向传播结束,这个临时更新就消失了,原始权重保持不变。
即在处理当前任务时,模型表现得就像权重被更新了一样。
但这个「便签」只在当前计算中有效,就临时用一下,一旦任务完成,便签就被丢弃,原始权重保持不变。
数学原理解释
论文提供了详细的数学公式:

这里我们继续用上面的例子进行解释:
-
W:原始的权重矩阵(菜谱)
-
ΔA:上下文带来的变化(不要放辣椒)
-
A(x):当前的查询表示(你正在炒一份不放辣椒的菜)
整个更新就是:
便签内容 = (原始权重处理的上下文变化) × (当前任务的特征)

这个机制的巧妙之处在于,它完美模拟了梯度下降的效果,却不需要真正的反向传播。
也就是,不需要更新模型的权重。
实验验证
研究团队设计了一个简单但有说服力的实验:训练一个小型transformer学习线性函数映射。

实验评估了两个模型:
-
使用完整提示词序列的模型
-
只使用计算出的rank 1「便签」的模型
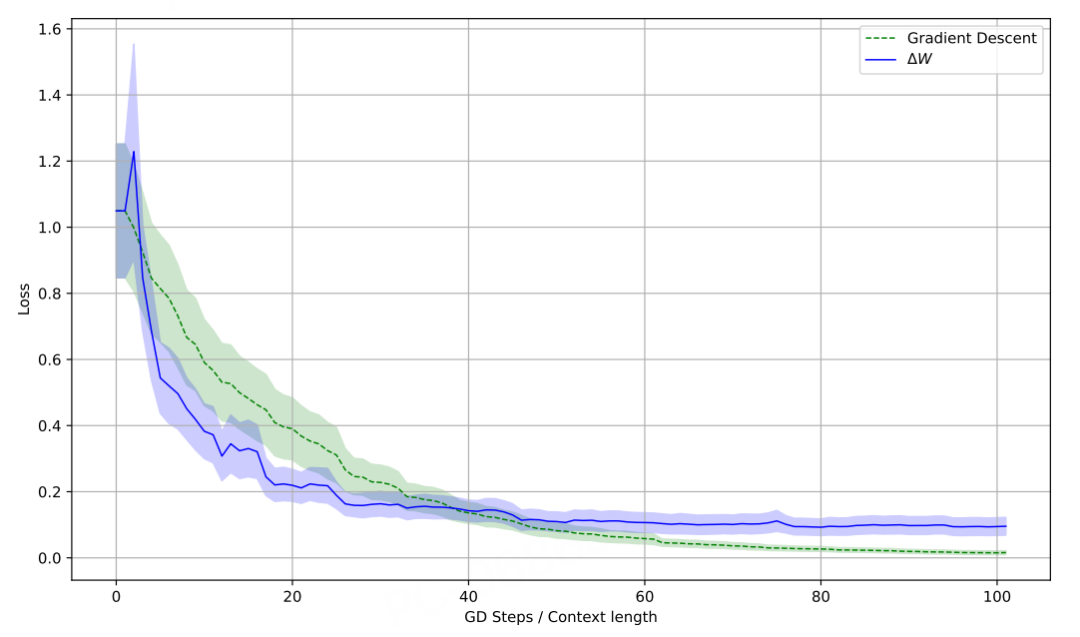
结果显示,两者的损失曲线几乎完全重合,在100个训练步骤中保持高度一致。
而值得注意的是,当他们比较传统梯度下降微调和这种「便签」机制时,发现两种方法都能有效降低测试损失,但「便签」方法完全避免了反向传播。
这个结论可以说是,极其关键!
通向10万美元模型的道路
而回到Dario Amodei的预测,这种「临时便签」机制解释了为什么超长上下文窗口在技术上是可行的:
1. 内存效率极高:rank 1更新比完整权重更新节省2000倍空间
2. 计算可并行化:每个token的「便签」可以独立计算
3. 无需重新训练:模型能即时适应新任务,不需要昂贵的GPU训练
看到这里,你可能会想:看来,AGI/ASI 真的不远了!
但,几事都有两面性……
一位略带阴谋论的reddit网友指出:
随着Gemini Deepthink、Grok Heavy、ChatGPT计划中的每月2万美元模型等产品的出现,消费者将失去接触AI技术前沿的机会。
这个新的技术可能反而会加剧AI的「阶级分化」:当企业级模型支持1亿词上下文、能进行多天思考时,消费级模型可能还在处理几千词的简单任务。
而当新模型架构在推理能力上越来越强,我们终有一天会看到10万美元的模型,普通人根本无法触及。
未来的AI时代线可能是这样的:
-
2025-2027:月费1万美元的模型,支持1000万词上下文
-
2028-2030:月费10万美元的模型,支持1亿词上下文,能进行多天深度思考
-
2030年代中期:AI公司停止对外销售最先进模型,转为内部使用百万美元级别的推理系统
该网友警告称:AI 模型正在正式分化为消费级和「精英」企业级两条路线。
更令人担忧的是,这种分化意味着我们将每年跳跃2个模型版本而不是1个,2030年对于大型企业和私人科技公司来说,实际上相当于2035年。
最后,AI公司或将停止向企业出售他们的最高级推理模型,转而私下运行每月成本100万美元的推理模型,并在秘密中悄无声息得到了ASI——
而身为普通人的我们,却将还天真的认为AI只是个玩具。
不得不说,这是真敢想,但也不是太离谱
Google Research论文:Learning without training: The implicit dynamics of in-context learning: https://arxiv.org/abs/2507.16003
[2]Dario Amodei采访完整视频: https://www.youtube.com/watch?v=mYDSSRS-B5U
(文:AGI Hunt)