

今天是2025年8月2日,星期六,无锡,雨
我们继续来看RAG的事情,来看看flowchart流程图RAG思路,其中跟文档解析也有关,怎么表示flowchart,怎么做抽取,怎么做RAG。
一、flowchart流程图RAG思路
GraphRAG进展,flowchart流程图RAG结合的思路,在电信领域的技术文档中,流程图等图像包含大量关键信息,现有视觉语言模型(VLM)直接生成流程图描述存在准确性低、信息丢失等问题。
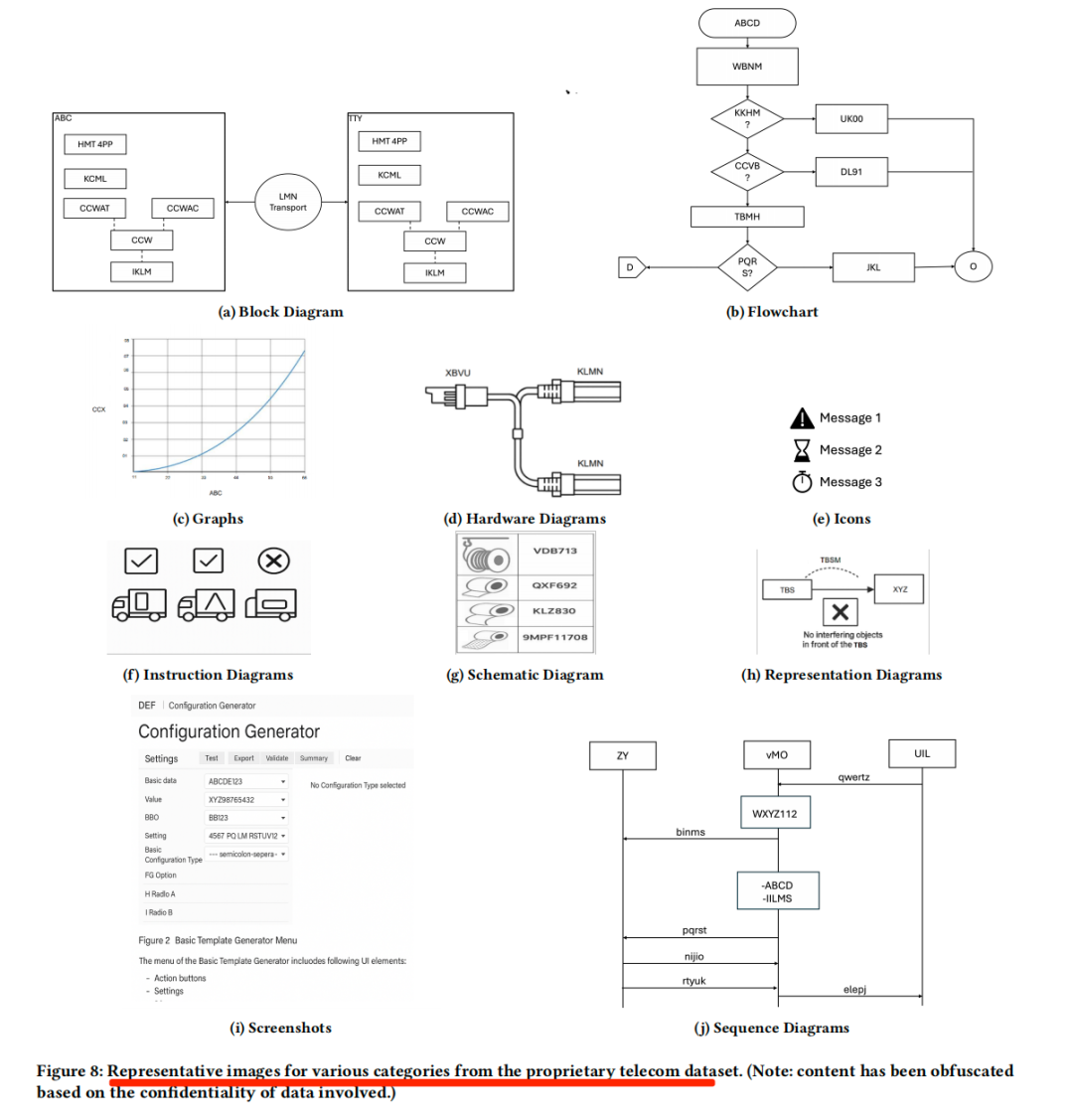
所以,看一个工作,《A Graph-based Approach for Multi-Modal Question Answering from Flowcharts in TelecomDocuments》,https://arxiv.org/pdf/2507.22938,采用的方案是基于图表示的多模态QA方法。
我们看下核心流程:
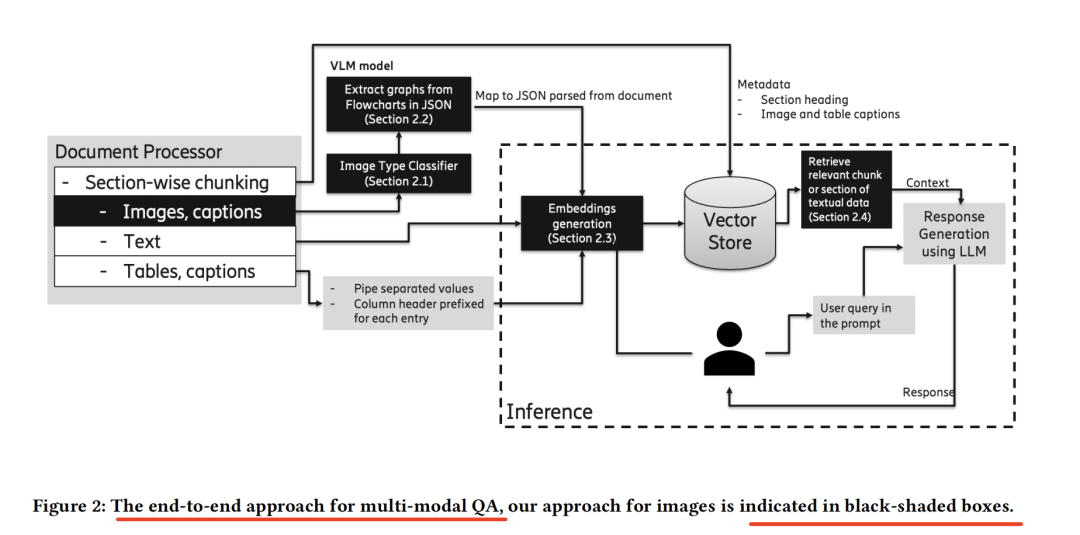
1、图像分类
使用微调的文档图像变换器(DIT)模型对从电信文档中解析出的图像进行分类,识别出流程图图像。
DIT模型在PIDocs数据集上进行微调,用于预测图像类型,对应的路线如下:

2、图表示生成
在进行实验时表现最佳的顶级开源VLM是Qwen2-VL和Llava 1.5,所以采用通过微调的VLM(Qwen2-VL)将流程图转化为带属性的有向图结构,每个块表示为一个节点,节点内的文本作为节点属性;块之间的链接表示为边,边上的文本作为边属性,使用Flowlearn数据集的合成流程图进行微调。
对应的prompt如下:

输出的数据样式如下:

既然做微调,则需要做训练数据。因此,为了应对流程图中常见的节点形状和边属性,使用Mermaid工具生成合成图像,并与现有数据集进行增强,一个合成的例子如下:

3、检索优化
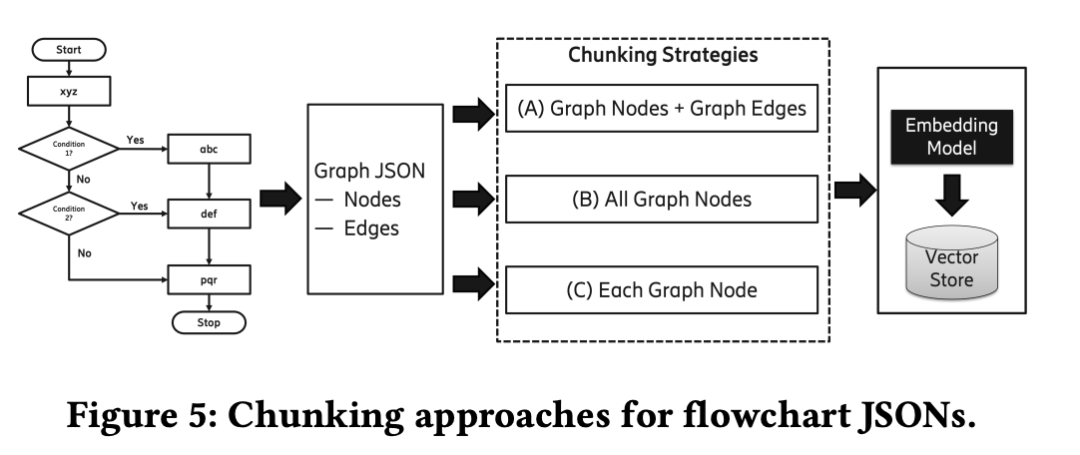
探索三种图结构分块策略,包括每个节点作为一个块、所有节点作为一个块、整个图JSON作为一个块。
使用bge-large和TeleRoBERTa两种嵌入模型。
最后,看下结果:
表5显示了不同问答类别嵌入模型的top-k检索准确率。
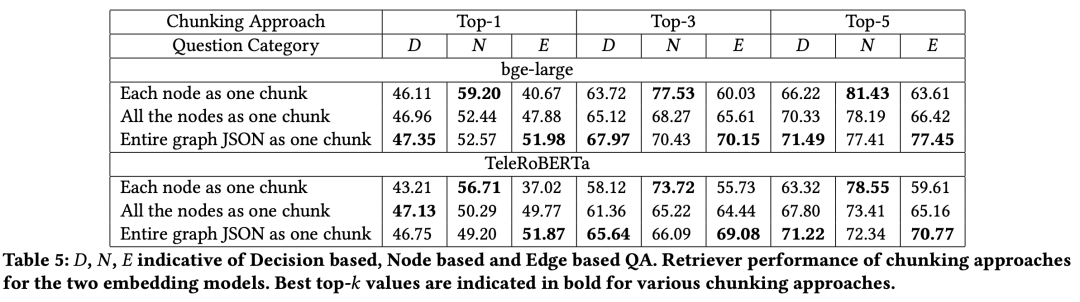
在分块策略中,当使用整个图表JSON作为一个块时,性能较高通常最为常见,对于节点相关问题,可以获得更好的性能,其次是决策相关问题,最后是边缘相关问题。
当图结构的嵌入与文本一同散布在向量存储中时,检索准确率会降低,这是预期之中的,因为在典型场景下,检索到的top-k嵌入不再仅限于图结构。
参考文献
1、https://arxiv.org/pdf/2507.22938
(文:老刘说NLP)