


字节跳动Seed团队于2025年7月18日开源了Seed-X系列模型,这是一套专为多语言翻译优化的7B参数大模型,支持28种语言的双向翻译。
它通过高质量的多语言数据预训练、指令微调和强化学习相结合的方式,显著提升翻译能力,尤其在处理复杂语言模式和生硬翻译时表现出色。Seed-X在自动评估和人工评估中均表现出色,与超大型模型如GPT-4、Claude-3.5等相当甚至更好。它还推出了挑战性测试集Seed-X-Challenge-Set,涵盖互联网俚语、经典文学、成语等多种语言元素,推动翻译研究的进一步发展。

一、主要功能
(一)高效翻译
Seed-X支持28种语言的双向翻译,涵盖英语、中文、法语、德语、日语、韩语等多种常用语言,能够快速准确地完成翻译任务。
(二)多样领域覆盖
Seed-X在互联网、科技、办公对话、电子商务、生物医学、金融、法律、文学和娱乐等多个领域表现出色,能够应对不同场景下的翻译需求。
(三)推理与解释
基于链式推理(CoT)功能,Seed-X能够解释翻译的含义,帮助用户更好地理解翻译内容。
(四)强化学习优化
通过强化学习进一步提升翻译质量和泛化能力,尤其在处理复杂语言模式和生硬翻译时表现更佳。
二、技术原理
(一)预训练
Seed-X的预训练阶段使用了大规模的多语言数据,包括单语和双语数据,涵盖28种语言。单语数据用于提升语言理解能力,双语数据用于对齐不同语言的语义。预训练分为三个阶段:
1. 通用阶段:主要对主要语言进行预训练,如中文和英文。
2. 多语言主导阶段:增加多语言数据的比例,提升多语言覆盖能力。
3. 并行数据阶段:仅使用高质量的双语数据进行微调,进一步优化翻译性能。
(二)指令微调(SFT)
基于人工标注的翻译数据和数据增强技术,生成高质量的指令数据集,提升模型的翻译能力。引入链式推理(CoT),让模型在翻译时逐步思考,解释翻译的逻辑和过程,提升翻译的准确性和可解释性。
(三)强化学习(RL)
基于人类偏好数据训练奖励模型,为候选翻译分配评分,评估翻译质量。使用近端策略优化(PPO)算法对模型进行优化,基于多轮迭代提升翻译性能,特别是在低资源语言对上表现优异。
(四)数据优化
使用数据清洗和增强技术,去除低质量数据,提升数据质量,进一步优化模型性能。通过多轮迭代优化双语数据,逐步提升数据质量和模型的翻译能力。
三、应用场景
(一)跨语言信息检索
研究人员可以将中文技术论文翻译成英文,快速检索到全球相关领域的最新研究成果。
(二)多语言内容创作
自媒体作者可以将中文博客翻译成多种语言,发布到国际平台,吸引全球读者。
(三)在线教育
在线编程课程可以将英文教程翻译成中文、西班牙文和阿拉伯文,帮助不同国家的学生学习编程。
(四)电子商务
电商平台可以将中文商品描述翻译成英文、法文和德文,提升国际用户的购物体验。
(五)社交媒体
微博平台可以将用户的中文帖子翻译成英文、日文和韩文,方便国际用户阅读和互动。
四、性能表现
Seed-X在Flores-200和WMT-25等基准测试中表现出色,其平均BLEURT和COMET分数均接近甚至超过了一些超大型模型,如GPT-4和Claude-3.5。
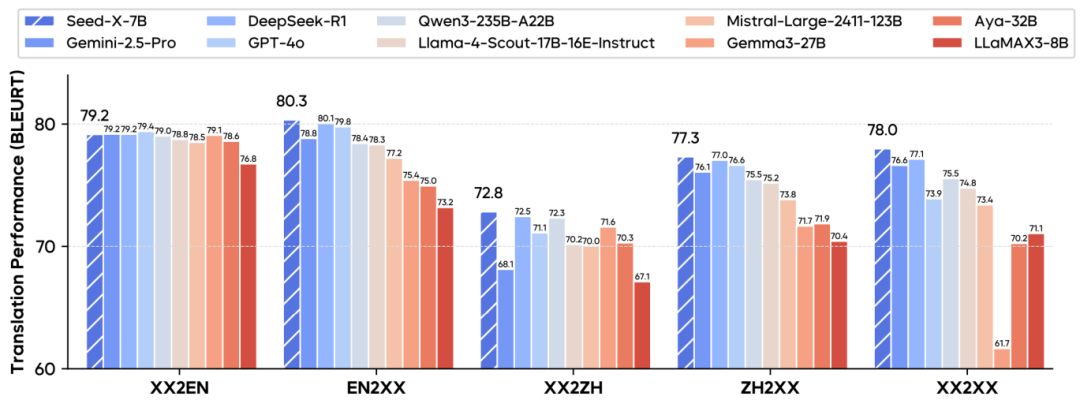
在Seed-X-Challenge-Set的人工评估中,Seed-X在多个语言对上的表现与GPT-4和Claude-3.5相当,甚至在某些语言对上表现更好。另外Seed-X在低资源语言对上的表现尤为突出,例如印尼语到阿拉伯语的翻译,其BLEURT分数达到77.2,显示出强大的泛化能力。
五、快速使用
(一)环境准备
conda create -n seedx python=3.10pip install vllm==0.8.0 transformers==4.51.3git lfs installgit clone https://huggingface.co/ByteDance-Seed/Seed-X-PPO-7B
(二)单句翻译示例
from vllm import LLM, SamplingParams, BeamSearchParamsmodel_path = "./ByteDance-Seed/Seed-X-PPO-7B"model = LLM(model=model_path,max_num_seqs=512,tensor_parallel_size=8,enable_prefix_caching=True,gpu_memory_utilization=0.95)messages = [# without CoT"Translate the following English sentence into Chinese:\nMay the force be with you <zh>",# with CoT"Translate the following English sentence into Chinese and explain it in detail:\nMay the force be with you <zh>"]# Beam search (We recommend using beam search decoding)decoding_params = BeamSearchParams(beam_width=4,max_tokens=512)# Greedy decodingdecoding_params = SamplingParams(temperature=0,max_tokens=512,skip_special_tokens=True)results = model.generate(messages, decoding_params)responses = [res.outputs[0].text.strip() for res in results]print(responses)
六、结语
Seed-X以其“7B参数挑战千亿模型”的亮眼成绩,为开源社区树立了一个高效、易用、可商用的翻译大模型新标杆。无论你是研究者、开发者还是产品经理,都可以基于其开放的权重、详尽的论文与代码,快速构建多语言创新应用。
项目地址
GitHub仓库:https://github.com/ByteDance-Seed/Seed-X-7B
HuggingFace模型库:https://huggingface.co/ByteDance-Seed/Seed-X-PPO-7B
技术论文:https://arxiv.org/pdf/2507.13618
(文:小兵的AI视界)