

前言
我们在一个采用 13×8 H800 DGX SuperPod 节点的解耦(分离)式大语言模型(LLM)推理架构中,评估了在服务等级目标(SLOs)约束下(即 TTFT < 2s,ITL < 50ms)的最大 prefill 与 decode 吞吐率(goodput)[^6]。系统在多种服务器端解耦配置下(如 (P3x3)D4 (i.e., 3 组 P3, 1 组 D4)、P4D9、P4D6、P2D4、P4D2、P2D2),达到了约 130 万 tokens/秒 的输入吞吐率和 2 万 tokens/秒 的最大输出吞吐率。在多数情况下,prefill 阶段构成性能瓶颈,导致较高的 TTFT。
参考 DeepSeek 工作负载推导出的解码节点与 prefill 节点的比例(1.4)[^9],为提升服务器端 goodput,我们尝试了更大的 prefill 节点组(如 P=3)和更小的张量并行(TP)规模(TP=24)。性能评估使用了 SGLang 的 bench_one_batch_server.py 基准脚本 [^1] 来测试 URL API 接口的响应能力,并在后续使用 genai-bench [^10] 对不同并发度下的输出吞吐进行了更可靠的测量。
在客户端,我们通过 evalscope [^2] 对 OpenAI 接口兼容的 API(通过 API key 验证)进行了在线观测与评估。在小输入请求场景下,系统在并发度为 50 时可维持 2.5 万 toks/sec 的输出吞吐,在并发度为 150 时可达到 5.5 万 toks/sec。我们观察到,当 batch size × 输入长度 超过某个阈值(如因 KV 缓存传输限制所致)[^7],TTFT 会急剧上升。
此外,为获得更高的 goodput,建议保持 输入序列长度(ISL)与输出序列长度(OSL)为特定比例,最佳为 4:1。因此,当 batch size 和序列长度增大以实现高吞吐时,总延迟往往由 TTFT 主导。为了保持高 GPU 利用率与 goodput,建议将并发度控制在 128 以下,以避免 TTFT 急剧上升。这种平衡策略在 H800 DGX SuperPod 系统上尤为有效。过高的 TTFT 会导致输出吞吐不稳定,并显著降低服务器端的 goodput 表现。
作者 : LEI WANG(https://github.com/yiakwy-xpu-ml-framework-team) (yiakwang@ust.hk ,公众号:聪明的汽车), Yujie Pu (yujiepu@ust.hk), Andy Guo (guozhenhua@hkgai.org), Yi Chao (chao.yi@hkgai.org), Yiwen Wang (yepmanwong@hkgai.org), Xue Wei (weixue@ust.hk)
编辑:GiantPandaLLM ,本文对应的编辑版本markdown见:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/large-language-model-note/sglang%26lightllm/SGLang%20v4.8.0%20PD%E5%88%86%E7%A6%BB%E6%80%A7%E8%83%BD%E7%A0%94%E7%A9%B6.md 。
动机与背景
在 Prefill-Decode 聚合的大模型推理架构中,vLLM 在 2024 年第二季度(https://github.com/vllm-project/vllm/issues/3861) 之前实现了一种将 prefill token 和 decode token 交错调度方案,随后通过连续调度(continuous scheduling)机制进行了改进,从而提升了整体 GPU 利用率 [^3]。
然而,由于 prefill 阶段和 decode 阶段在计算特性上的显著差异,将未切块的完整 prefill token(来自新请求)与正在运行请求的 decode token 一起持续批处理,会显著增加 decode 延迟。这会导致较大的 Token 间延迟(ITL),进而降低系统的响应性。
为了解决这个问题,PR#3130 中引入了 chunk-prefill 功能 [^4],使得新请求的 prefill token 在被切块后,能与正在运行请求的 decode token 一同批处理。该功能在同构部署系统中如图所示,有助于改善 ITL 并提升 GPU 利用率:

然而,chunked-prefill 并未真正考虑到 prefill 和 decode 两个阶段在计算特性上的本质差异。
解码过程通常通过 CUDA Graph 来捕捉多轮生成计算,以此提升效率。因此当解码任务与 chunked prefill 一同批处理时,CUDA Graph 便无法使用,反而会引入额外开销。
此外,正如 DistServe [^4][^5][^6] 在 13B 稠密模型上的观察结果,以及我们在 671B MoE 模型实验中的验证,在 colocated 服务系统中,一旦 batch_size × output_length 超过某个阈值(如 128(bs) × 128(OSL)),prefill 的计算成本将显著上升,与 chunked prefill 的切分大小无关。
因此,文献 [4] 中提出了解耦部署架构(disaggregated serving architecture)。DeepSeek 在此基础上进一步通过 DeepEP 和 MLA 技术降低延迟、提升吞吐,并迅速集成至 SGLang 中。在 P4D18 这种部署单元上,系统在满足 SLOs 的前提下达到了惊人的 73.7k toks/node/sec(输入)和 14.8k toks/node/sec(输出)。
然而,很多人误解认为 P 节点数量不应超过 D 节点数量,而实际上 DeepSeek 在其博客中并未公开 P 与 D 节点的真实比例 [^8]
根据其公布的数据 —— 每日服务总量为 608B 输入 token 和 168B 输出 token,结合其 prefill/decode 的 token 处理速度,可估算其总共使用的 prefill 节点数为:
总的 decode 节点数量为:
据此计算的 Decode/Prefill 节点比例约为 1.4 = 1314 / 955,而 P4D18 的组配置比例则为 3.27 : 1 = (955 / 4) : (1314 / 18)。因此 (P3x2)D4, (P3x3)D4 and (P4x2)D4 成为备选的测试配置。对于 H800 13×8 DGX SuperPod P/D分离架构,根据我们的实验分析 Prefill 节点 更容易成为系统瓶颈,因此限制 TP size 最多4, 因为更大 的 TP size 会降低推理速度,而过小的 TP size 会导致 KV cache 预留空间不足。
因此,在 H800 13×8 DGX SuperPod 上推荐使用如下 P/D 解耦配置:
1. (P3x2)D4
2. (P3x3)D4
3. (P4x2)D4
4. P4D6
由于我们分析得出 prefill 更可能成为系统瓶颈,因此我们将 TP 大小限制为 4,因为更大的 TP 大小会降低推理速度,而更小的 TP 则可能导致 KV cache 预留空间不足。
在我们的测试中,(P3x3)D4 和 P4D6 配置在 TTFT 上明显优于 P9D4,主要因为其采用更小的 TP 设置,同时 prefill 计算能力更强:
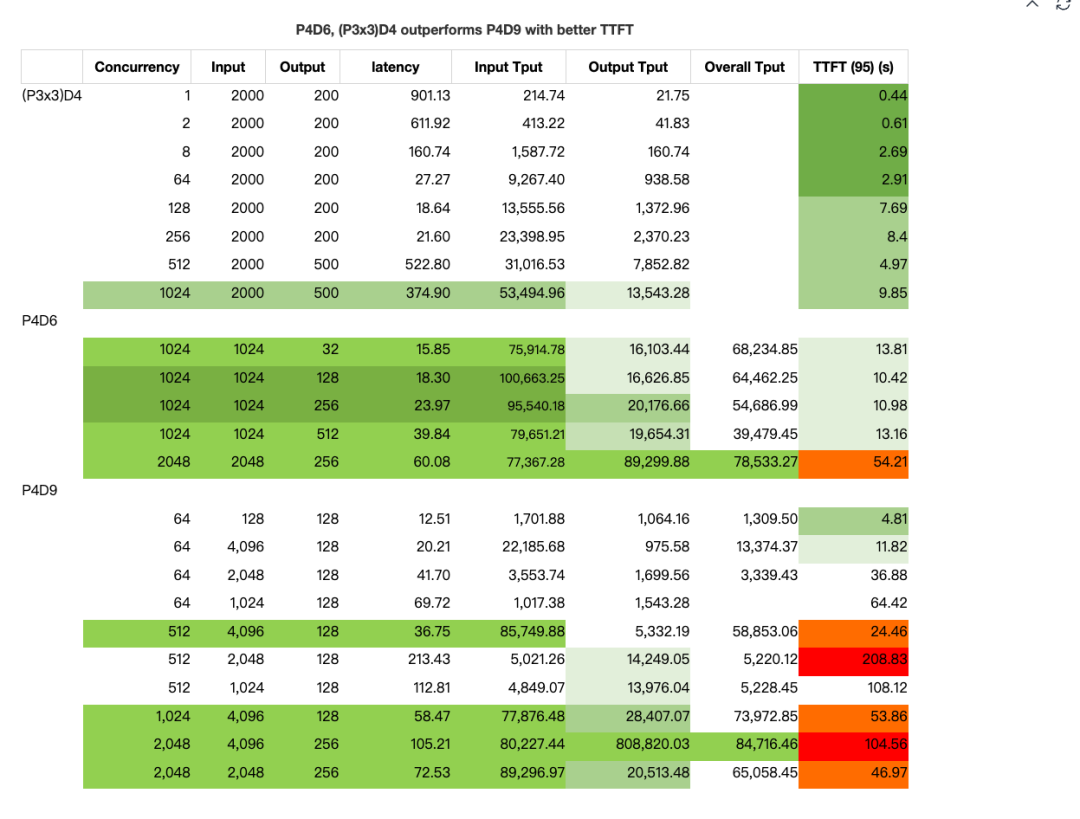
我们在 SGLang v0.4.8 中,使用我们自己微调的类 DeepSeek V3(0324)模型,进行了聚合式和解耦式推理部署的实验,并在较大规模下验证了效果。
给定输入序列长度(in_seq_len: 128 ~ 4096)和较短的输出序列长度(out_seq_len: 1 ~ 256),通过对不同 batch size(bs) 的调优,我们得出以下结论:
-
在 聚合式(aggregated)LLM 推理架构 中,Prefill goodput 的最大值 通常出现在某个特定的 batch_size (bs) × output_length (out_seq_len);
-
在 解耦式(disaggregated)LLM 推理架构 中,Prefill goodput 的最大值 则出现在特定的 batch_size (bs) × input_length (in_seq_len);
-
Prefill 更容易成为系统瓶颈,因此推荐使用更多的 prefill 节点, 根据下面测试数据可以使用更多的Prefill分组((P3)x3),Prefill
WORLD_SIZE和Decode WORLD_SIZE比值在 0.75(P3D4) ~ 1.0 (PXDX) 之间;
与在 DistServe [^4][^5][^6] 中部署 13B 稠密模型不同,部署 671B 大规模 MoE 模型(启用 256 个 expert 中的 8 个,并额外配置 P * 8 的冗余 experts)时,其 prefill goodput 会受到 output_length × batch_size 的乘积大小影响,并在达到最大值之前持续下降。详细的统计分析请见附录。
H800 x 2 测试:Prefill 与 Decode 的同机部署架构
在 H800 x 2 (DGX SuperPod) 测试配置中,每个节点通过 InfiniBand 互联,输入吞吐量(input throughput)最大值约为 20k toks/sec:
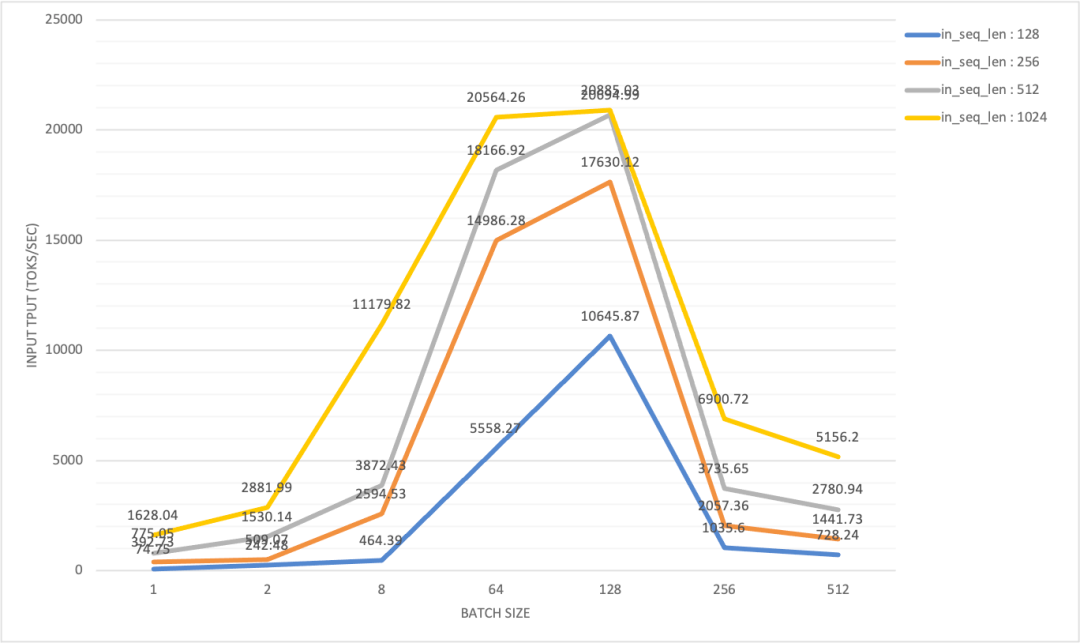
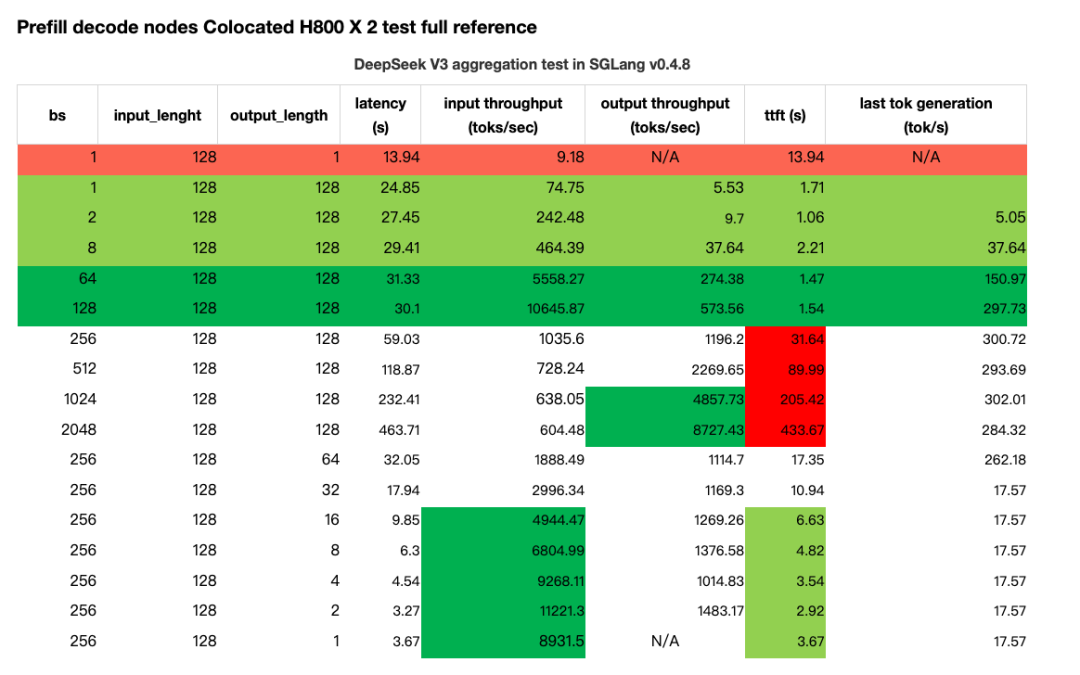
当批大小与输出长度的乘积超过 128(bs)×128(OSL) 时,我们观察到输入吞吐量显著下降,同时 TTFT(首次响应时间)突然且急剧上升。相比之下,输出吞吐量则随着批大小的增加逐渐上升,并最终达到峰值:
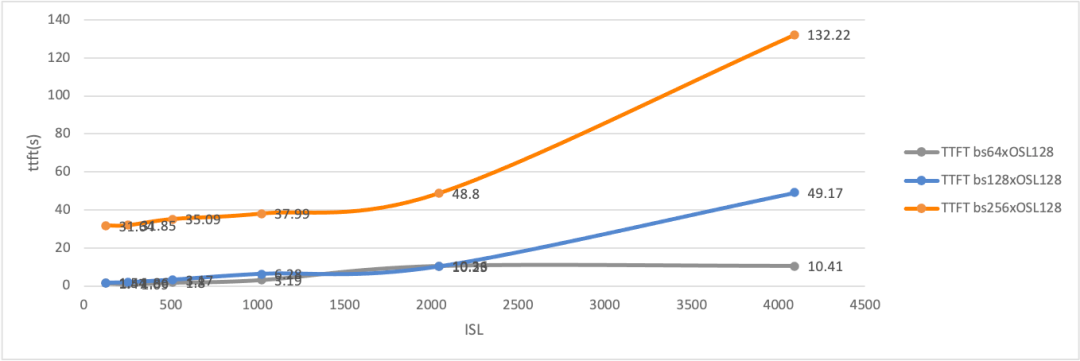
所有这些统计数据表明,要分别达到预填和解码的最大吞吐量,所需的工作负载模式是不同的。
直观来看,在一个解耦式(Disaggregated)部署架构中,Prefill节点的有效吞吐率(goodput)在设定合适的 chunk-prefill 大小与 TP(张量并行)规模后,会受限于某一批大小(batch size),因为 KV 缓存的传输速度存在瓶颈 [^7]。
SGLang P/D 分离如何工作
SGLang 的 Loader Balancer 服务现在支持多预填节点(Prefill,简称 P)配置(支持多个 P 节点的 master 地址),以及多解码节点(Decode,简称 D)配置(支持多个 D 节点的 master 地址):
# start_lb_service.sh
...
docker_args=$(echo -it --rm --privileged \
--name $tag \
--ulimit memlock=-1:-1 --net=host --cap-add=IPC_LOCK --ipc=host \
--device=/dev/infiniband \
-v $(readlink -f $SGLang):/workspace \
-v $MODEL_DIR:/root/models \
-v /etc/localtime:/etc/localtime:ro \
-e LOG_DIR=$LOG_DIR \
--workdir /workspace \
--cpus=64 \
--shm-size 32g \
$IMG
)
# (P3x3)D4 setup
docker run --gpus all "${docker_args[@]}" python -m sglang.srt.disaggregation.mini_lb \
--prefill "http://${prefill_group_0_master_addr}:${api_port}" \
"http://${prefill_group_1_master_addr}:${api_port}" \
"http://${prefill_group_2_master_addr}:${api_port}" \
--decode "http://${decode_group_0_master_addr}:${api_port}" \
--rust-lb
用户还可以调整 TP(张量并行)规模,因为 P 节点可以设置比 D 节点更小的 TP 规模,以获得更优的 TTFT(首次 token 时间)。
目前提供了两个负载均衡器:RustLB 和旧版 MiniLoadBalancer。它们遵循相同的 HTTP 接口,用于将 HTTP 请求分别重定向到 prefill 和 decode 服务器:
# load balance API interface
INFO: 10.33.4.141:41296 - "GET /get_server_info HTTP/1.1" 200 OK
INFO: 10.33.4.141:41312 - "POST /flush_cache HTTP/1.1" 200 OK
INFO: 10.33.4.141:41328 - "POST /generate HTTP/1.1" 200 OK
它们在内部的实现方式也相同,用于处理传入的请求:
# Rust : sgl-pdlb/src/lb_state.rs
pub async fn generate(
&self,
api_path: &str,
mut req: Box<dyn Bootstrap>,
) -> Result<HttpResponse, actix_web::Error> {
let (prefill, decode) = self.strategy_lb.select_pair(&self.client).await;
let stream = req.is_stream();
req.add_bootstrap_info(&prefill)?;
let json = serde_json::to_value(req)?;
let prefill_task = self.route_one(&prefill, Method::POST, api_path, Some(&json), false);
let decode_task = self.route_one(&decode, Method::POST, api_path, Some(&json), stream);
let (_, decode_response) = tokio::join!(prefill_task, decode_task);
decode_response?.into()
}
SGLang 负载均衡器的问题在于:它在选择一对 prefill 服务器和 decode 服务器时并不是基于流量或负载的。因此,无法保证各 prefill 服务器之间的负载均衡。
在请求处理过程中,prefill 服务器总是最先返回结果,以完成 KV cache 的生成:
参考 Dynamo 的工作流程 [^11],我们草拟了一个基于 SGLang RustLB 的 P/D 架构简化流程图,以便后续优化工作流程时有更清晰的理解:
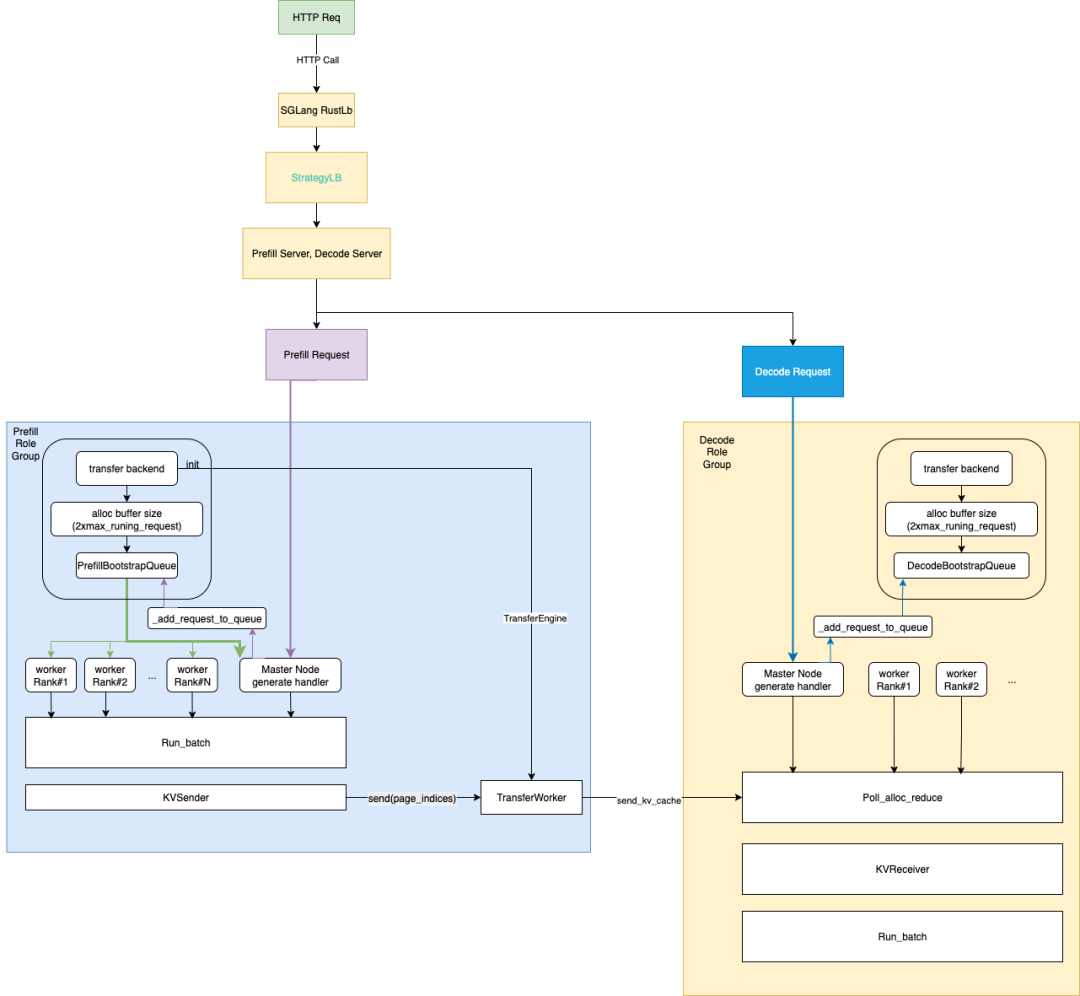
每个 P/D 进程都会启动一个后台线程,运行一个永久的事件循环,用于收集请求,将其输入以及必要的 KV cache 组成一个 batch,以开始执行推理任务。
测试方法
我们在 13 台 H800 DGX SuperPod 服务器上对所有可行的 P/D 解耦部署配置进行了系统性调研,并深入分析了 SGLang v0.4.8 中的解耦部署模式,分别从服务端与客户端两个角度进行了在线 P/D 解耦推理评估。
为测试做准备时,我们首先将硬件和软件环境对齐至最新的开源社区标准,并参考 SGLang 团队的官方指南 [1] 完成了配置文件的准备工作:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
完成配置文件的准备并正确设置测试脚本后,我们通过 CURL API 发送若干批次的查询请求对服务进行预热 —— 因为 SGLang 的事件循环工作线程在冷启动时需要较长时间进行 JIT 内核编译。服务预热完成后,便可开始正式采集测试统计数据。
硬件 和 软件
本次实验所使用的 H800 SuperPod 硬件按机架(racks)组织部署:
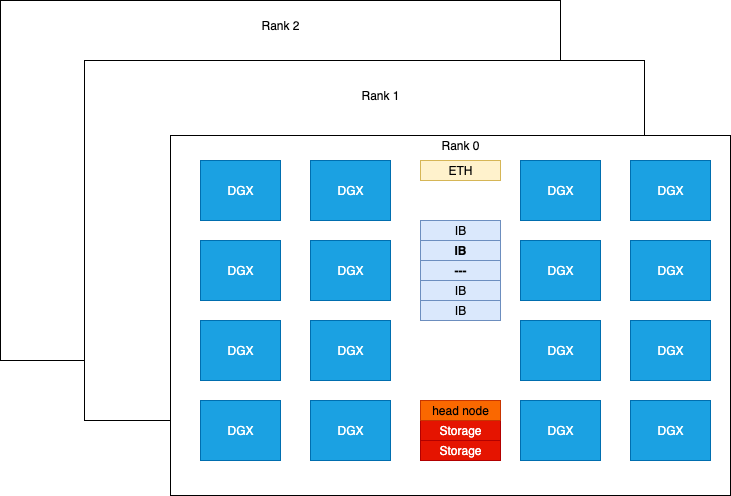
NVIDIA H800 DGX 在计算性能方面与 H100 DGX 相当,唯一区别在于 FP64/FP32 数据类型的处理能力较弱,以及由于 NVLINK 配置减少,其通信带宽大约为后者的一半。每张 H800 卡连接一张 Mellanox CX-7(MT2910)网络卡,通过 InfiniBand 交换机互连,峰值双向带宽可达 50 GB/s。
在单节点 NCCL 测试中,nccl_all_reduce 的bus带宽为 213 GB/s;在双节点测试中,该带宽为 171 GB/s;在跨机架测试(所有 GPU 通过同一个 InfiniBand 链路跨机架连接)中,带宽为 49 GB/s。
在 P/D 解耦测试中,大多数通信功能由 DeepEP 和 NVSHMEM 驱动完成。DeepEP 自 SGLang 核心团队于 2025 年 5 月进行 P/D 实验以来已有较大改动。因此,我们在自定义 Docker 环境中从零构建了 DeepEP。
Deepep : deep-ep==1.1.0+c50f3d6
目前我们选择 Mooncake 作为解耦(disaggregation)的后端,但未来会尝试其他后端:
# optional for disaggregation option
disaggregation_opt=" \
$disaggregation_opt \
--disaggregation-transfer-backend mooncake \
"
We require the latest transfer engine as it is 10x faster ( see PR#499(https://github.com/kvcache-ai/Mooncake/pull/499) and PR#7236(https://github.com/sgl-project/sglang/pull/7236) ) than that was used in May 2025.
mooncake-transfer-engine==v0.3.4
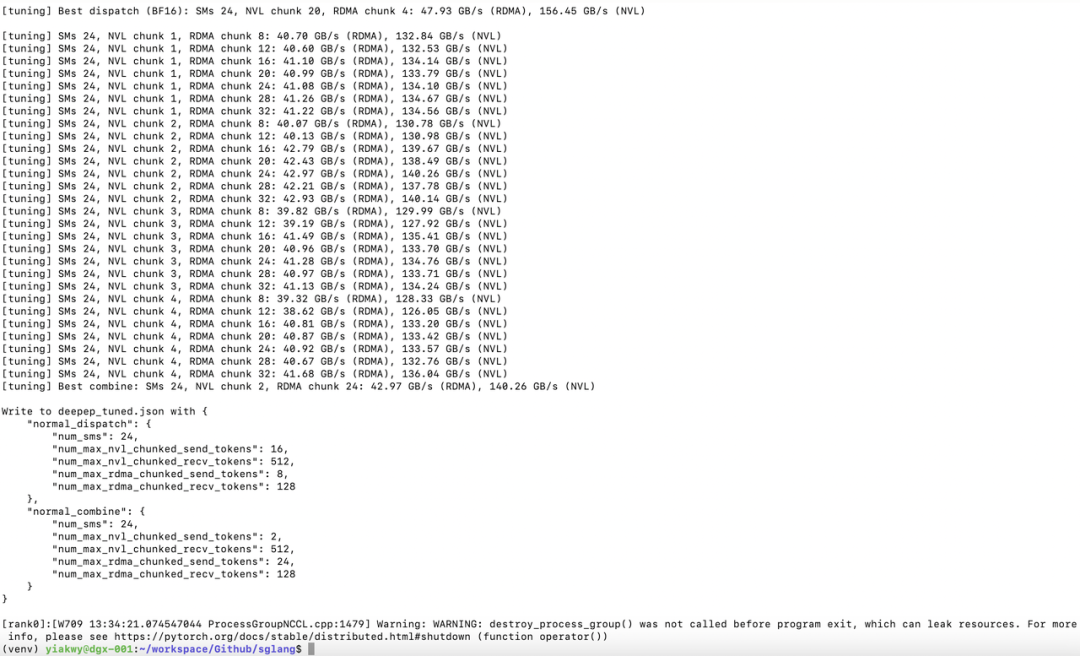
调优 DeepEP 是我们测试的第一步。预填节点数为 2、3(直接使用 3 个预填节点在当前 SGLang v0.4.8 配置中可能会导致问题)和 4:
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
在本次实验中,DeepEP 测试显示 bf16 的性能远高于 OCP fp8e4m3。我们尝试了不同组合的 NCCL、NVSHMEM 环境变量,但由于与 libtorch 的兼容性问题,只有少数组合测试成功:
# env - nccl 2.23, nccl 2.27 symmetric memroy branch
export NCCL_IB_HCA=mlx5_0,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_9,mlx5_10,mlx5_11
# traffic class for QoS tunning
# export NCCL_IB_TC=136
# service level that maps virtual lane
# export NCCL_IB_SL=5
export NCCL_IB_GID_INDEX=3
export NCCL_SOCKET_IFNAME=ibp24s0,ibp41s0f0,ibp64s0,ibp79s0,ibp94s0,ibp154s0,ibp170s0f0,ibp192s0
# export NCCL_DEBUG=DEBUG
# export NCCL_IB_QPS_PER_CONNECTION=8
# export NCCL_IB_SPLIT_DATA_ON_QPS=1
# export NCCL_MIN_NCHANNELS=4
# NOTE Torch 2.7 has issues to support commented options
# env - nvshmem
# export NVSHMEM_ENABLE_NIC_PE_MAPPING=1
# export NVSHMEM_HCA_LIST=$NCCL_IB_HCA
# export NVSHMEM_IB_GID_INDEX=3
# NOTE Torch 2.7 has issues to support commented options, see Appendix
成功调优后应看到如下表现:
在 SGLang v0.4.8 中,默认情况下 DeepGEMM 未启用,且没有针对 H800 上运行的融合 MoE Triton 内核的调优配置。
因此,我们对融合 MoE Triton 内核进行了微调,生成了适用于 H800 的 Triton 内核配置,并最终启用了DeepEP, DeepGEMM 的 JIT GEMM 内核加速 prefill。
由于 H800 系统内存限制,Prefill 和 Decode 的部署单元需从以下选项中选择:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
在我们的测试脚本中,我们将配置分类为:扩展配置(scaling config)、模型信息(model info)、服务器信息(server info)、基础配置(basic config)、解耦配置(disaggregation config)、调优参数(tuning parameters)以及环境变量(environmental variables)。
Common Basic Config
#### Scaling config
RANK=${RANK:-0}
WORLD_SIZE=${WORLD_SIZE:-2}
TP=${TP:-16}# 32
DP=${DP:-1}# 32
#### Model config
bs=${bs:-128}# 8192
ctx_len=${ctx_len:-65536}# 4096
#### Basic config
concurrency_opt=" \
--max-running-requests $bs
"
if [ "$DP" -eq 1 ]; then
dp_attention_opt=""
dp_lm_head_opt=""
deepep_moe_opt=""
else
dp_attention_opt=" \
--enable-dp-attention \
"
dp_lm_head_opt=" \
--enable-dp-lm-head \
"
# in this test, we use deep-ep==1.1.0+c50f3d6
# decode is in low_latency mode
deepep_moe_opt=" \
--enable-deepep-moe \
--deepep-mode normal \
"
fi
log_opt=" \
--decode-log-interval 1 \
"
timeout_opt=" \
--watchdog-timeout 1000000 \
"
# dp_lm_head_opt and moe_dense_tp_opt are needed
dp_lm_head_opt=" \
--enable-dp-lm-head \
"
moe_dense_tp_opt=" \
--moe-dense-tp-size ${moe_dense_tp_size} \
"
page_opt=" \
--page-size ${page_size} \
"
radix_cache_opt=" \
--disable-radix-cache \
"
##### Optimization Options
batch_overlap_opt=" \
--enable-two-batch-overlap \
"
#### Disaggregation config
ib_devices="mlx5_0,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_9,mlx5_10,mlx5_11"
disaggregation_opt=" \
--disaggregation-ib-device ${ib_devices} \
--disaggregation-mode ${disaggregation_mode} \
"
这些适用于 Prefill 和 Decode 解耦角色的通用配置包含可调参数:WORLD_SIZE、TP、DP、max_running_request_size 和 page_size。
其中,max_running_request_size 影响批处理大小和缓冲区大小,page_size 影响传输的 token 数量。我们建议将 max_running_request_size 设置为 128,page_size 设置为 32。
For Prefill node, deepep_mode is set to normal, while in decode node, is set to low_latency:
对于 Prefill 节点,deepep_mode 设置为 normal;而在 Decode 节点,设置为 low_latency:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
此外,prefill 节点最好设置较小到中等的 chunk-prefill 大小,以减少 TTFT。
除此之外,除了 prefill-decode 配置外,还应配置专家并行(expert parallel)的负载均衡:
#### expert distribution options
if [ "$stage" == "create_ep_dis" ]; then
create_ep_dis_opt=" \
--expert-distribution-recorder-mode stat \
--disable-overlap-schedule \
--expert-distribution-recorder-buffer-size -1 \
"
expert_distribution_opt=""
else
create_ep_dis_opt=""
expert_distribution_opt=" \
--init-expert-location ${EXPERT_DISTRIBUTION_PT_LOCATION} \
"
fi
ep_num_redundant_experts_opt=" \
--ep-num-redundant-experts 32 \
"
#### EP Load balance - Prefill
deepep_opt=" \
--deepep-config $DEEP_EP_CFG \
"
eplb_opt=" \
--enable-eplb \
--eplb-algorithm deepseek \
--ep-dispatch-algorithm dynamic \
--eplb-rebalance-num-iterations 500 \
$ep_num_redundant_experts_opt \
$deepep_opt \
"
#### EP Load balance - Decode
deepep_opt=""
eplb_opt=" \
$ep_num_redundant_experts_opt \
"
所以测试中的完整配置如下:
#### Full basic config
basic_config_opt=" \
--dist-init-addr $MASTER_ADDR:$MASTER_PORT \
--nnodes ${WORLD_SIZE} --node-rank $RANK --tp $TP --dp $DP \
--mem-fraction-static ${memory_fraction_static} \
$moe_dense_tp_opt \
$dp_lm_head_opt \
$log_opt \
$timeout_opt \
$dp_attention_opt \
$deepep_moe_opt \
$page_opt \
$radix_cache_opt \
--trust-remote-code --host "0.0.0.0" --port 30000 \
--log-requests \
--served-model-name DeepSeek-0324 \
--context-length $ctx_len \
"
#### Prefill Config
chunk_prefill_opt=" \
--chunked-prefill-size ${chunked_prefill_size} \
"
max_token_opt=" \
--max-total-tokens 131072 \
"
ep_num_redundant_experts_opt=" \
--ep-num-redundant-experts 32 \
"
prefill_node_opt=" \
$disaggregation_opt \
$chunk_prefill_opt \
$max_token_opt \
--disable-cuda-graph
"
# optional for prefill node
prefill_node_opt=" \
$prefill_node_opt \
--max-prefill-tokens ${max_prefill_tokens} \
"
#### Decode Config
decode_node_opt=" \
$disaggregation_opt \
--cuda-graph-bs {cubs} \
"
环境变量
现在 SGLang 支持来自 DeepGEMM 的 GEMM 内核。正如我们观察到的,当批量大小超过某个阈值时,prefill 总是系统吞吐的瓶颈,因此我们默认启用来自 DeepGEMM 的更快速 GEMM 实现, 并设置 moon-cake (0.3.4) 作为默认版本。
这些配置通过环境变量进行控制。
#### SGLang env
MC_TE_METRIC=true
SGLANG_TBO_DEBUG=1
export MC_TE_METRIC=$MC_TE_METRIC
export SGLANG_TBO_DEBUG=$SGLANG_TBO_DEBUG
export SGL_ENABLE_JIT_DEEPGEMM=1
export SGLANG_SET_CPU_AFFINITY=1
export SGLANG_DEEPEP_NUM_MAX_DISPATCH_TOKENS_PER_RANK=256
export SGLANG_HACK_DEEPEP_NEW_MODE=0
export SGLANG_HACK_DEEPEP_NUM_SMS=8
export SGLANG_DISAGGREGATION_BOOTSTRAP_TIMEOUT=360000
# env - nccl
export NCCL_IB_HCA=mlx5_0,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_9,mlx5_10,mlx5_11
export NCCL_IB_GID_INDEX=3
export NCCL_SOCKET_IFNAME=ibp24s0,ibp41s0f0,ibp64s0,ibp79s0,ibp94s0,ibp154s0,ibp170s0f0,ibp192s0
参数调试.
基本调优参数是 prefill 节点和 decode 节点的 WORLD_SIZE,即 P{D}。我们通过不同的 P/D 解耦配置进行迭代,寻找合理的服务器端划分,以在客户端基准测试中观察到的吞吐率达到优化。
虽然我们未能在 SLOs 下达到 DeepSeek 的性能,但发现 P4D6 和 (P3x3)D4 在吞吐率表现上优于 P4D9。以批量大小 1024,输入长度 1K / 输出长度 256 为例,系统可实现约 95k tokens/sec 的输入吞吐量,20k tokens/sec 的输出吞吐量,最高传输速率达到 356 MB/sec,TTFT 在 9~10 秒左右,占总延迟的不到 30%。
#### Scaling config
RANK=${RANK:-0}
WORLD_SIZE=${WORLD_SIZE:-2}
TP=${TP:-16}# 32
DP=${DP:-1}# 32
#### Model config
bs=${bs:-128}# 8192
# ctx_len=${ctx_len:-65536}
ctx_len=4096
#### Tunning info
EXPERT_DISTRIBUTION_PT_LOCATION="./attachment_ep_statistics/decode_in1000out1000.json"
# NOTE (yiakwy) : create in 'create_ep_dis' stage
moe_dense_tp_size=${moe_dense_tp_size:-1}
page_size=${page_size:-1}
cubs=${cubs:-256}
memory_fraction_static=${memory_fraction_static:-0.81}
其他选项
MTP
在我们的初步尝试中(感谢 Yujie Pu),使用 DeepSeek 草案模型的 MTP 解码并未提升整体吞吐率,我们会在后续继续调查这个问题。
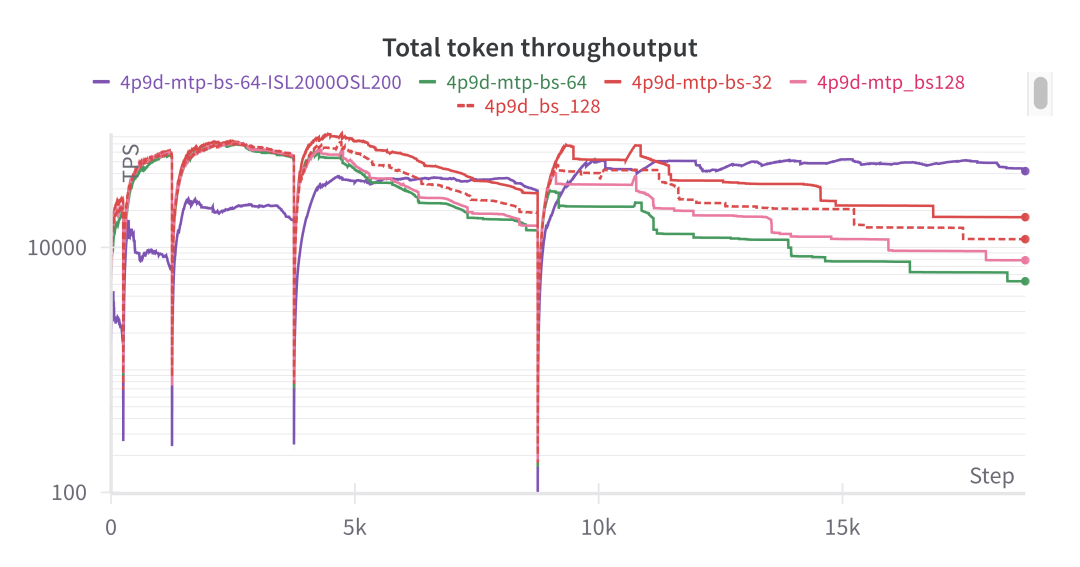
Benchmarking of P/D
P2D2
对于 P2D2 配置,由于 KV 缓存保留空间有限(P 节点 HBM 利用率为 65 GB / 79 GB,D 节点为 70 GB / 79 GB),我们在客户端经常遇到批量大小为 1024 时的 KV 缓存内存溢出(OOM)问题。当批量大小 × 输入长度超过 128 时,我们观察到 TTFT 急剧增长,并且 SGLang 中的输出吞吐率测量变得不可靠:
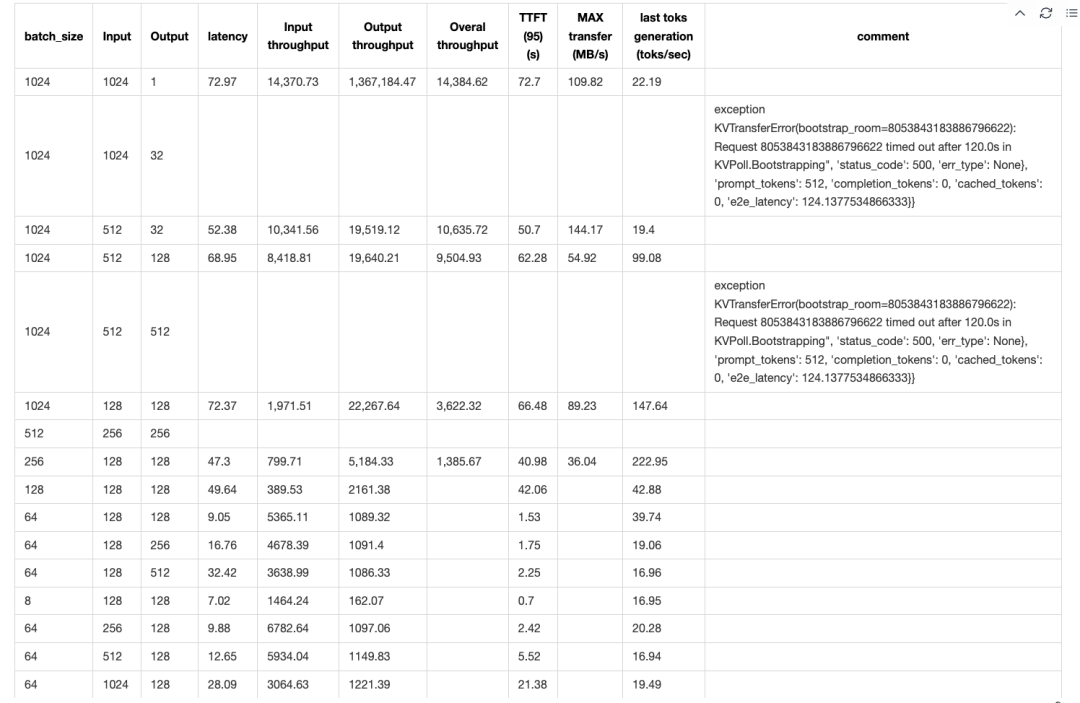
基于以上观察,我们后来将用户侧在线测试的输入分为两类:
-
短查询(输入序列长度 in_seq_len < 128),以实现最多128并发下的高吞吐率;
-
长查询,追求最大吞吐量,且最长返回时间为120秒。
当批量大小 × 输入长度超过 128 × 128(以 P2D2 配置为例)时,KV 缓存传输成为推理速度的瓶颈,导致整个系统在数据平面变成网络 I/O 受限。
Mooncake 开发团队在 PR#499 中定位到传输引擎的性能问题,并迅速将新的批量传输功能集成到 SGLang v0.4.8(同时需要安装 transfer-engine==0.3.4),见 PR#7236。
尽管传输引擎带来了10倍的性能提升,数据平面中的网络 I/O 受限问题在不同的 P/D 配置中仍然普遍存在。
如果不考虑 SLOs 下的吞吐率,很容易获得最大输入吞吐率 45k toks/sec。正如我们之前分析的,输出吞吐率受限于 TTFT,因此测量结果并不准确。
值得注意的是,当输入序列长度与输出序列长度的比率为 4:1 时,在这台 H800 SuperPod 机器上,GPU 利用率达到最佳,且最后一个 token 的生成速度达到最大值:

P2D4/P4D2
在 P2D4 和 P4D2 测试中,目标之一是确定扩展方向,以减少 TTFT 并提升最大吞吐率。正如我们在动机部分讨论的,减少 TTFT 的一个方法是减小 Chunk-prefill 大小,同时降低 Prefill 节点的数据并行度。
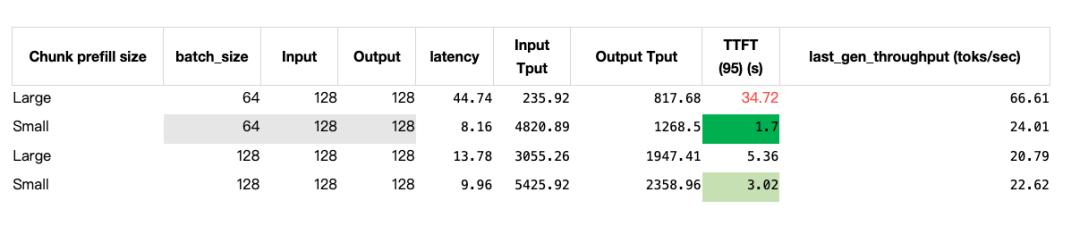
数据并行(Data Parallel)和数据并行注意力机制(DP Attention,DP > 1)必须开启,否则我们会观察到 TTFT 和吞吐率显著下降:
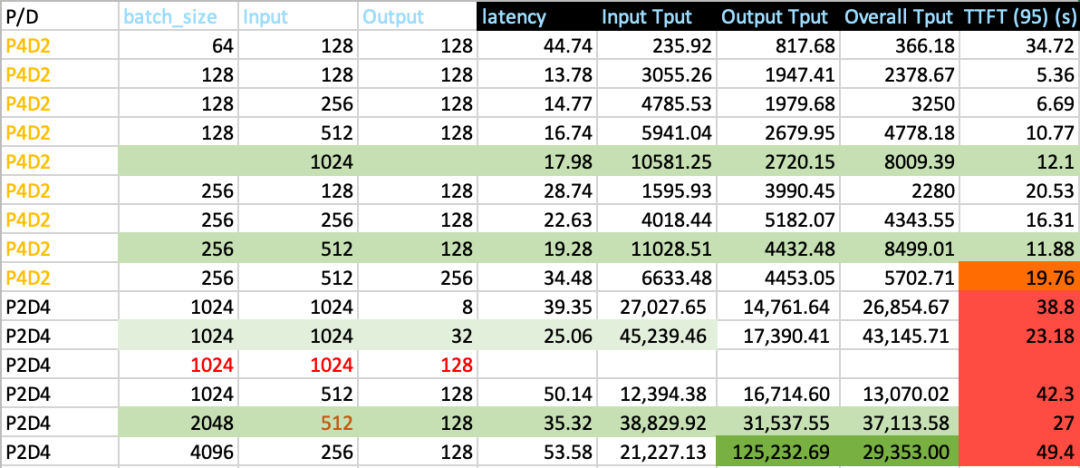
根据上述统计数据,我们得出结论:在 P2D4 配置下,要支持超过 1024 的输入序列长度,大部分运行时间都花费在预填充(prefill)阶段,因此 TTFT 非常接近整体延迟。
因此,我们考虑增加预填充节点的比例 r(r > 1,且 r < 2)。
P4D6

在 P4D6 解耦测试中,平均首个生成token时间(TTFT)升高至 10 秒左右;当批次大小 × 输入长度超过 2048 × 1024 时,TTFT 以陡峭的斜率迅速增长。
P4D9
P4D9 是 SGLang 团队推荐的黄金配置 [^8],但在我们的测试中,它未能产生令人满意的吞吐率,且在输入长度为 4K、输出长度为 256 时,其整体吞吐量被限制在 8 万token/s。

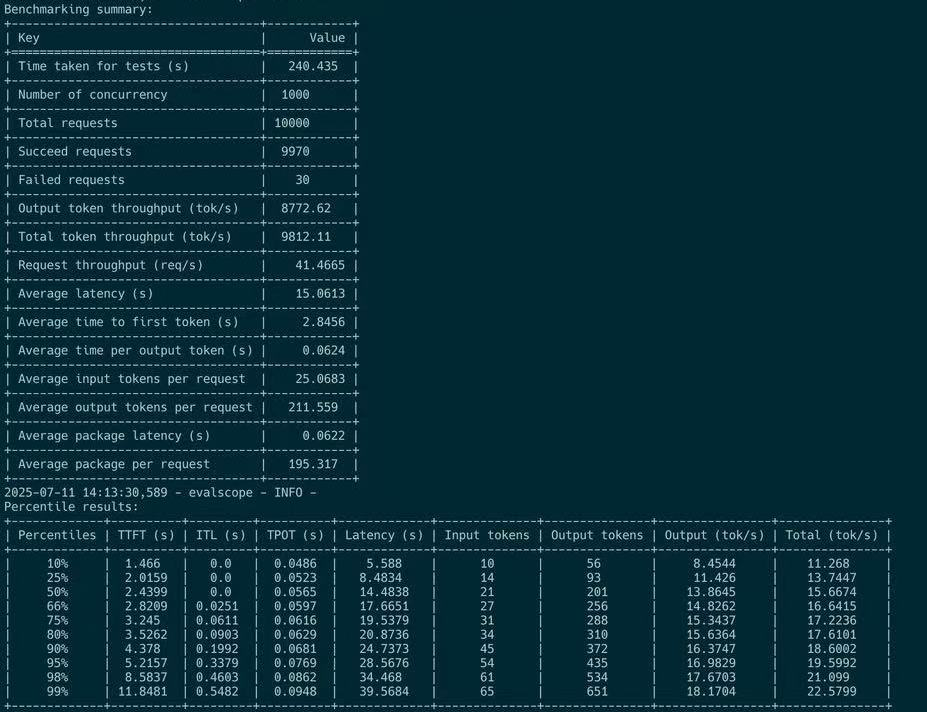
我们在用户侧的在线测试中验证了 P4D9 解耦配置。对于短查询,用户侧(用户的 SDK)观察到的总输出token吞吐量仅为 8 千token/s:
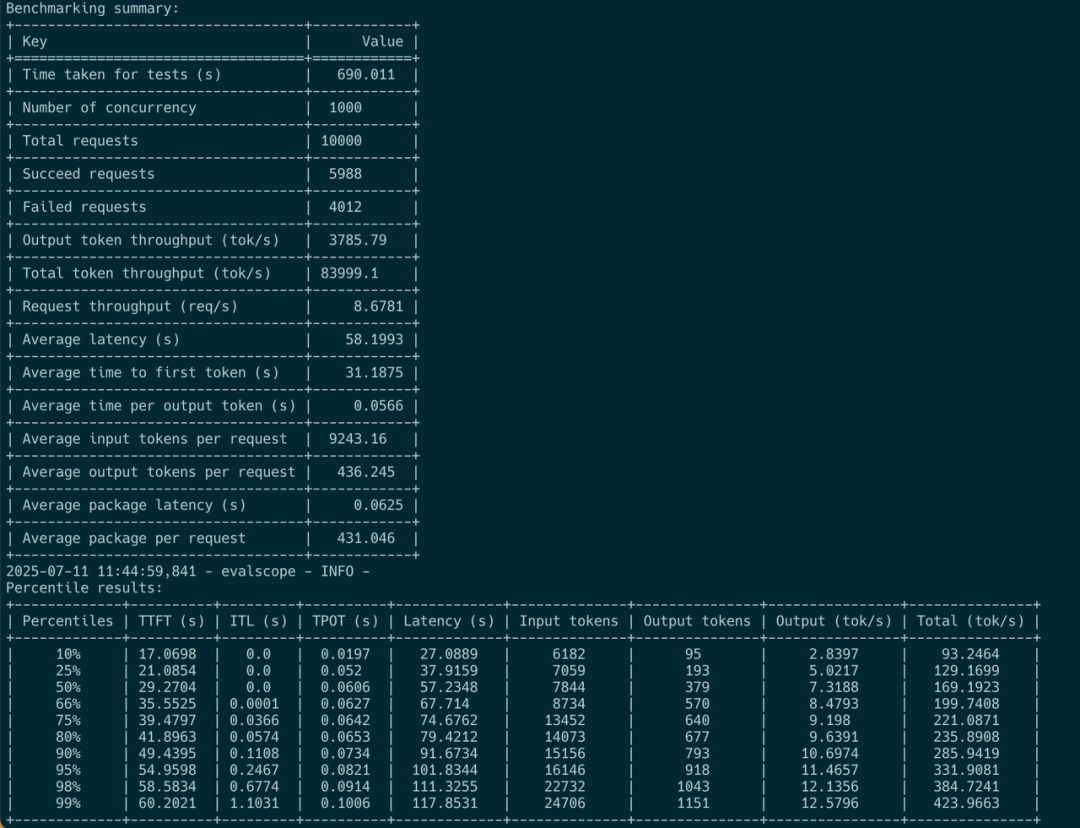
对于长查询,用户侧(用户的 SDK)仅观察到最大 400 token/s的吞吐量:
结论
我们对在 13×8 H800 SuperPod 上,使用 SGLang V0.4.8 以分离式架构托管 DeepSeek V3 671B 类模型进行了全面研究。
首先,我们总结并验证了较大的 Prefill 组(最好 Prefill 与 Decode 组的比例为 3:1)以及较小的 TP 大小(最好 Prefill 节点与 Decode 节点总数比例为 1:1)能够带来更好的 TTFT 和更高的 goodput。
其次,我们验证了大规模 MoE 模型的 P/D 设置,发现当输入长度乘以批次大小超过某个阈值时,TTFT 会急剧上升,因此在实际部署中应限制 max_running_request_size。
为提升 Prefill 节点的 TTFT 和计算效率,我们选择了更小的 chunked-prefill 大小。
该配置在短查询场景下实现了接近 8 万 tokens/秒的整体 goodput,并在用户侧观察到约 8 千 tokens/秒的吞吐率,相较于 2xH800 共享部署单元最大 1 万 tokens/秒的整体 goodput,有了显著提升。
Future Work
分离式服务架构将多个节点作为一个部署单元进行暴露。它充分利用了 Prefill 阶段和解码阶段计算特性的差异,相较于传统的同机部署架构,整体吞吐量(goodput)有显著提升。
然而,更大的部署单元也带来了更高的风险——即便只有一块卡需要维修,整个单元都可能受到影响。因此,在保证有竞争力的吞吐量的同时,合理选择部署单元的规模对于该方案在实际应用中的成功至关重要。
接下来,我们将聚焦通信层级的库,挖掘 Prefill 节点的潜力,进一步降低首次返回时间(TTFT)。
Acknowledgement
感谢 Mr Yiwen Wang (yepmanwong@hkgai.org) 和 Prof Wei Xue (weixue@ust.hk) 对本文的支持与建议,感谢 Andy Guo (guozhenhua@hkgai.org) 负责用户侧测试,感谢 Yu Jiepu (yujiepu@hkgai.org) 负责部署以验证 MTP 和 (P3x3)D4 的有效性,感谢 Yi Chao (chao.yi@hkgai.org) 协助资源安排。
我们在自有的 H800 DGX SuperPod 机器上独立复现了 P/D 解耦部署的性能表现,并向 SGLang 核心团队及社区致以最诚挚的感谢,感谢他们在工程实现、复现建议以及对报告的快速反馈方面所做出的贡献。
附录
Prefill decode nodes Colocated H800 X 2 test full reference
参考文献
[^1]: Instruction for Running DeepSeek with Large-scale PD and EP, https://github.com/sgl-project/sglang/issues/6017, retrieved on 12 July 2025.
[^2]: Evaluation Framework for Large Models, ModelScope team, 2024, https://github.com/modelscope/evalscope, retrieved on 12 July 2025.
[^3]: Orca : A Distributed Serving System for transformer-Based Generative Models, https://www.usenix.org/conference/osdi22/presentation/yu, Gyeong-In Yu and Joo Seong Jeong and Geon-Woo Kim and Soojeong Kim and Byung-Gon Chun, OSDI 2022, https://www.usenix.org/conference/osdi22/presentation/yu
[^4]: SARATHI : efficient LLM inference by piggybacking decodes with chunked prefills, https://arxiv.org/pdf/2308.16369
[^5]: DistServe : Disaggregating Prefill and Decoding for Goodput-optimized large language model serving, Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, Hao Zhang, 6 Jun 2024, https://arxiv.org/pdf/2401.09670
[^6]: Throughput is Not All You Need : Maximizing Goodput in LLM Serving using Prefill-decode Disaggregation, Junda Chen, Yinmin Zhong, Shengyu Liu, Yibo Zhu, Xin Jin, Hao Zhang, 3 March 2024, accessed online on 12 July 2025.
[^7]: MoonCake transfer engine performance : https://kvcache-ai.github.io/Mooncake/performance/sglang-benchmark-results-v1.html, accessed online 18 july 2025
[^8]: https://lmsys.org/blog/2025-05-05-large-scale-ep/, accessed online on 12 July 2025
[^9]: DeepSeek OpenWeek : https://github.com/deepseek-ai/open-infra-index?tab=readme-ov-file
[^10]: SGLang genai-bench : https://github.com/sgl-project/genai-bench, accessed online on 18 July
[^11]: https://github.com/ai-dynamo/dynamo/blob/main/docs/images/dynamo_flow.png, accessed online on 18 July
(文:GiantPandaCV)