

BeingBeyond团队 投稿
量子位 | 公众号 QbitAI
如何让机器人从看懂世界,到理解意图,再到做出动作,是具身智能领域当下最受关注的技术重点。
但真机数据的匮乏,正在使对应的视觉-语言-动作(VLA)模型面临发展瓶颈。
尽管业界已投入大量资源构建数据平台(如马斯克主导的“数据工厂”项目),现有真机数据规模仍较模型规模定律所需的上亿级训练样本相差三个数量级。
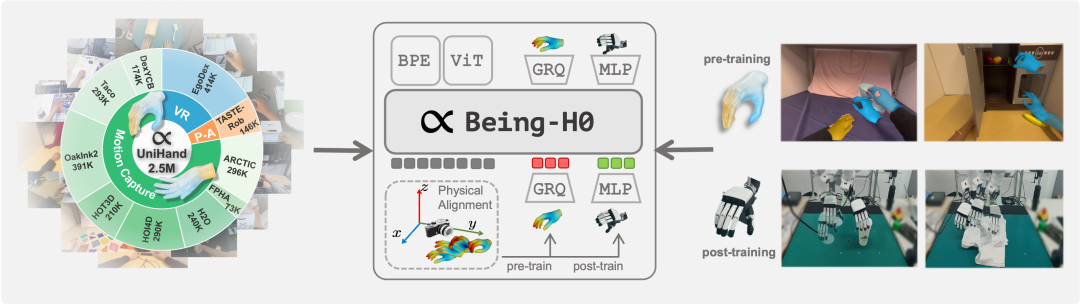
△Being-H0:基于人类视频手部数据的大规模预训练VLA模型
针对这一关键问题,北京大学&BeingBeyond卢宗青团队提出了创新性解决方案:
该研究团队利用海量人类操作视频提取手部运动轨迹,构建了规模达亿级的训练数据集。

其核心贡献在于提出了“物理指令微调”(physical instruction tuning)方法框架,实现了从人类手部运动到机器人动作空间的精确映射。
基于这一技术突破,团队成功训练出首个基于人类视频手部数据的大规模预训练VLA模型——Being-H0,并完成了真实机器人平台的验证实验。
这项研究发现:
-
人的双手可被视为各种末端执行器的标准模版(包括灵巧手、夹爪) -
通过大规模人手操作视频预训练VLA生成人手动作,能解决具身领域规模定律(Scaling Law)的“数据瓶颈” -
预训练VLA能大幅提升机器人操作任务成功率和真机样本效率
Being-H0:首个利用人类操作轨迹训练的大规模VLA模型
Being-H0的基础建立于如下关键假设:
人类手部运动可以被视为最完备的操作执行器,而现有机器人末端执行器均可视为其特定子集。上至复杂的五指灵巧手,下至结构简单的二指夹爪(可抽象为手腕-双指三节点系统),都能从人类手部运动知识中获益。
通过预训练学习人类操作轨迹,可以构建具有广泛适应性的基座模型。
值得注意的是,这类视频数据在当前的短视频时代具有极高的易获取性,且天然避免了仿真环境数采带来的“虚拟-现实”差异问题。
研究团队借鉴视觉指令微调(visual instruction tuning)的成功经验,创新性地提出了一个完整的物理指令微调框架。
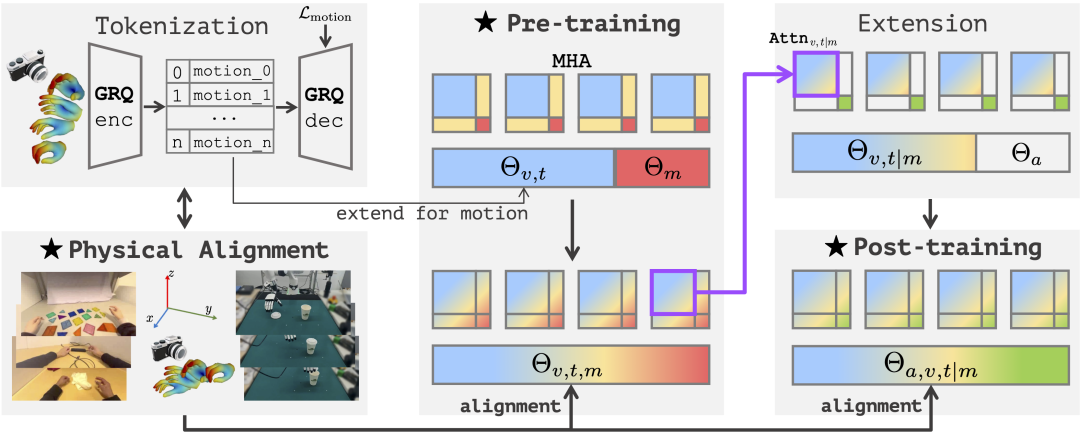
△物理指令调优训练框架
与前者不同,新框架专门针对2D多模态数据与3D机器人动作空间之间的异构性问题进行了设计——这正是现有模型在具身任务中表现不及多模态评测的主要原因——包含以下三个关键部分:
1. 预训练——从百万量级人手操作视频中学习
传统多模态大模型在向VLA迁移时面临的核心瓶颈在于,预训练阶段与下游任务之间存在显著的数据异构性。基于一维自然语言训练的模型虽擅长语言推理,基于二维图像训练的模型虽精于视觉语言推断,但二者均难以建模三维动作空间的语义。为此,该研究通过海量手部操作轨迹数据来弥合这一模态鸿沟,并设计了统一的多模态自回归架构,实现了视觉、语言与动作模态的协同表征学习与联合生成。
Being-H0采用了分部位动作编码方案: 在预训练过程中,针对手腕和手指分别设计专用编码器,采用基于分组的残差变分量化自编码器,将动作姿态重建误差控制在毫米级,有效解决了动作离散化带来的精度损失问题。
2. 物理空间对齐——消除不同数据源的异构性,进行2D视频到三维空间的物理对齐
研究引入物理空间对齐技术,通过统一的坐标系转换方法,消除了多源数据在相机参数、观测视角等方面的差异性,确保VLA模型能够有效学习空间与动作表征。
3. 后训练——从预训练模型迁移到真机
Being-H0建立了从人类动作到机器人操作的高效转换通道,确保技能迁移的有效性。
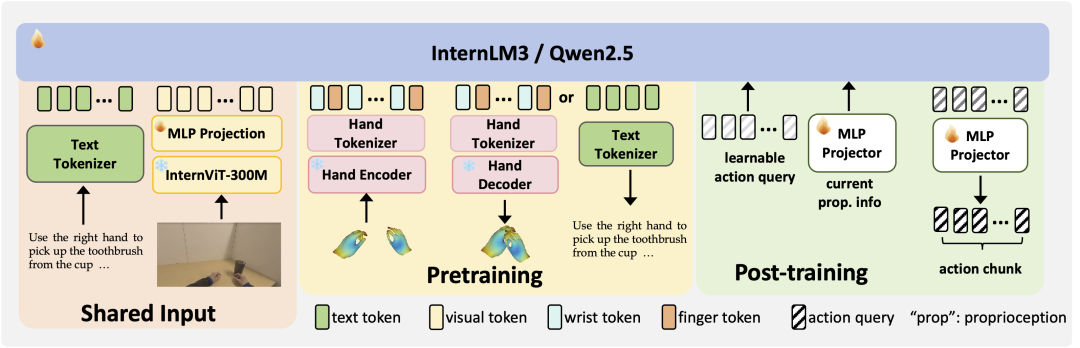
△预训练和后训练的架构细节
上亿级规模UniHand数据集
为满足物理指令调优框架对训练数据的需求,研究团队系统性地构建了一套完整的数据采集与处理流程,包括数据收集、清洗和对齐等关键环节。
基于此流程,团队构建了规模达上亿级的UniHand数据集。
该数据集整合了来自11个开源数据源的多模态数据,涵盖动作捕捉系统、虚拟现实(VR)设备采集以及常规RGB视频三种主要数据来源。
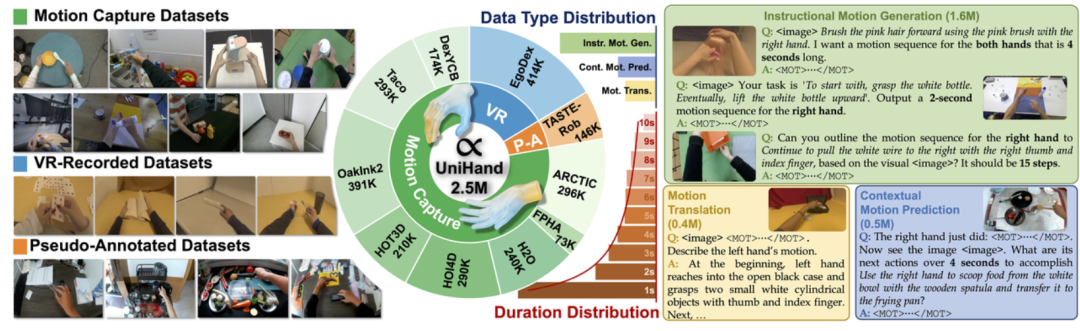
△UniHand:规模超过1.5亿的人类手势动作数据集
在任务类型方面,数据集主要包含以下三类预训练任务:
-
基于指令的手势动作生成; -
手势动作语义理解; -
上下文感知的动作预测。
经过系统整合与处理,最终构建的数据集包含1.5亿条人类手部动作指令样本。
值得注意的是,即便仅使用其中250万条样本进行预训练,模型在手势动作预测任务及下游真实机器人任务上均已展现出显著性能提升。
真实机器人实验验证
除常规预训练任务评估外,这项研究的一个重要贡献在于开展了全面的真实机器人实验以验证方法有效性。
实验结果表明,在保持下游任务训练参数一致的情况下,基于物理指令调优框架训练的Being-H0模型显著超越了其基座模型InternVL3,同时也优于同期英伟达NVIDIA开源的VLA大模型GR00T N1.5。
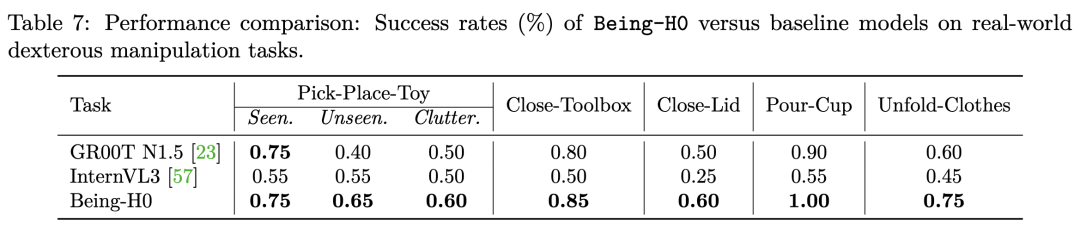
需要特别指出的是,GR00T N1.5在训练过程中同样采用了人类视频数据进行隐式动作空间学习,且其训练规模远超Being-H0当前使用的预训练数据量。
这一对比结果有力地证实了本研究数据构建策略的有效性:通过显式构建与下游任务结构高度对齐的预训练数据,能够显著提升模型从视频数据中学习人类动作知识的效果,进而提高下游任务的成功率。
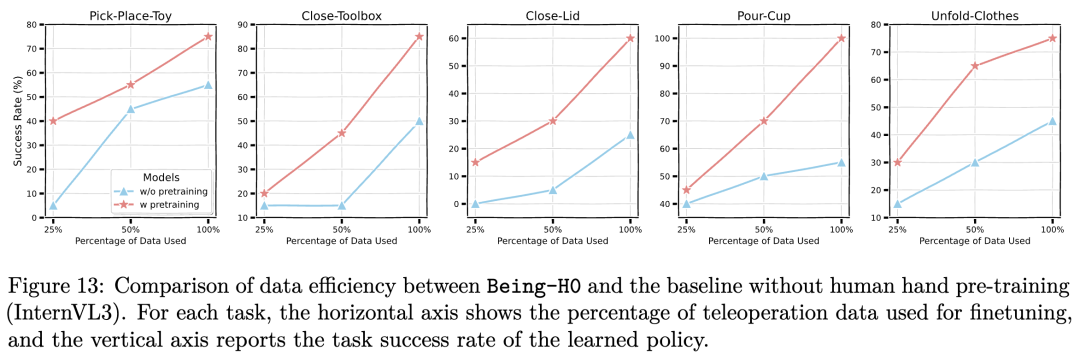
为深入验证方法的鲁棒性,研究团队进一步对比了Being-H0与未经预训练的基础模型在不同训练数据规模下的性能表现。
实验设置了从25%到100%不等的训练数据采样比例,结果表明在相同数据量条件下,Being-H0模型始终展现出稳定的性能优势。
此外,在同样成功率下,Being-H0所需要的真机数据量远少于其他模型(例如,在Pick-Place-Toy任务中,Being-H0在25%真机数据训练的性能已接近其他模型在100%数据上的性能)。
这一系列实验不仅验证了物理指令调优框架的有效性,同时也证实了该方法可以显著降低真机数据量。
下列视频展示了其中一些真机演示的例子(视频无加速剪辑)。
BeingBeyond团队
Being-H0由包括智在无界、北京大学以及人民大学的研究团队共同打造。
作为首个基于人类操作轨迹训练的大规模VLA模型,Being-H0成功突破了数据封锁的桎梏,为机器人灵巧操作研究开辟了新范式。
团队表示,正持续攻坚具身智能大模型、灵巧操作、全身运动控制等核心技术,致力于让机器人真正走进千家万户。
文章链接:https://arxiv.org/pdf/2507.15597
项目官网:https://beingbeyond.github.io/Being-H0/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)