

作者:企鹅火烈鸟🦩
原文链接🔗:https://research.colfax-intl.com/cutlass-tutorial-sub-byte-gemm-on-nvidia-blackwell-gpus/
欢迎来到关于NVIDIA Blackwell架构上GEMM研究的系列文章第三部分。在第一和第二部分中,我们探讨了新的Blackwell张量核心UMMA指令的张量内存和2 SM功能,以及如何在CUTLASS中处理这些功能。在本部分中,我们将介绍低精度计算,然后讨论Blackwell GEMM如何执行低精度计算,特别关低精度(6位和4位)格式,以及这些格式如何影响数据的内存布局设置。主要结论是,对于f8f6f4类型的混合输入UMMA(即支持8位、6位和4位操作数的任意组合),UMMA需要以某种未打包格式读取数据,而TMA可以在从GMEM到SMEM的内存加载过程中处理这种正确的未打包格式。然而,这对允许的瓦片大小、领先维度和GMEM中数据的地址对齐施加了一些额外的约束。在编写CUTLASS内核代码时,可以基于第一和第二部分中建立的理解,进一步加入f8f6f4混合输入的情况,我们将展示这一点。
Blackwell还支持块缩放格式,包括遵循OCP规范的mx类型或NVIDIA自有的nvf4数据类型。有关Blackwell支持的低精度类型的全面列表,请参阅此CUTLASS文档。我们将块缩放的讨论推迟到下一篇文章中。
为什么要使用低精度?
低精度通常指使用比1985年IEEE 754标准化的32位单精度浮点数更少位数的数据类型。在许多人工智能工作负载中,低精度类型比单精度更受欢迎,因为它们能显著减少模型大小和计算负载。近年来,硬件和软件在低精度方向上的发展紧密相关:
-
NVIDIA的Volta架构于2017年推出,配备了支持半精度(FP16)矩阵乘法的张量核心,并以FP32进行累加。 -
2018年,谷歌Brain设计了bfloat16格式,该格式得到谷歌TPU的原生支持。与FP16不同,BF16具有8位指数位,使其动态范围与FP32相同,但精度较低。其他芯片,如NVIDIA Ampere架构,很快也开始支持BF16。 -
Ampere还引入了TF32,一种19位格式,具有FP32的范围和FP16的精度。 -
INT8量化是人工智能中长期使用的一种技术,特别是在推理阶段,起源于数字信号处理领域。然而,整数计算的范围和精度与浮点数有显著差异,使得整数格式不太适合训练,并且需要在推理期间对模型训练进行重大调整以获得成功。针对这一问题,Micikevicius等人(2022)提出了两种用于人工智能应用的8位浮点格式:一种具有4位指数和3位尾数,另一种具有5位指数和2位尾数。NVIDIA Hopper架构为这两种格式提供了加速的矩阵乘法原语。 -
最近,Blackwell架构引入了对6位和4位浮点数的子字节精度支持。这些格式已被人工智能研究人员迅速采用,以实现更小的模型大小和更高的计算吞吐量。
使用低精度格式通常涉及混合精度计算,即使用多种数据类型的计算。以下是一些例子:
-
大多数张量核心指令以比操作数更高精度的数据类型进行累加,通常是FP32或INT32。 -
在Hopper架构上,DeepSeek通过交替使用张量核心累加和CUDA核心累加(在我们的早期文章中讨论过),进一步缓解了FP8 GEMM的精度损失。 -
混合输入GEMM,其中操作数具有不同的数据类型,也可能很有用——例如,我们可能希望通过将模型权重量化为8位或更低来减少模型的内存占用,同时通过保持激活值的高精度来保留质量。
由于低精度类型通常范围较小,简单量化可能导致非常大的值被截断或非常小的值被置零。为了弥补这一点,可以在量化之前将每组值除以一个高精度缩放因子,使其处于可接受的范围内。这些缩放因子随后被保存,并在计算结束时重新乘回。关于如何对值进行分组以进行缩放,有几种合理选择:
-
整个张量使用单一缩放因子(成本低,但会导致严重的饱和问题)。 -
相反,每值一个缩放因子(允许高精度但内存开销巨大)。 -
每矩阵行或列一个缩放因子。 -
瓦片式缩放:输出的固定大小矩阵瓦片(例如128×128)一个缩放因子。 -
块缩放:每行瓦片(例如1×32)一个缩放因子。
Blackwell的UMMA指令原生支持与1×32或1×16块相关联的缩放因子的块缩放。这些缩放因子形成额外的张量,必须正确加载并输入到张量核心中,从而增加了内核的复杂性。在本文中,我们将坚持讨论未缩放的情况,并在本系列的最后(也是最终)部分讨论块缩放。
数据格式
CUTLASS支持多种数据类型,包括许多不同的低精度数据类型。支持的数据类型的完整列表可在CUTLASS文档中找到。在本博客中,我们主要关注浮点数据类型,因此我们将首先简要回顾这种数据类型的存储方式,然后再讨论新的子字节数据类型。
浮点数据的位分为三部分:符号、指数和尾数。(有关浮点数的背景知识,请参阅此处或此处。)符号位(如果存在)仅占用一位,但指数和尾数可以占用任意位数。尾数位数越多,精度越高;而指数位数越多,范围越大。但由于使用的总位数有限,指数和尾数的位数分配之间存在权衡。在低精度格式中,总位数较少,这种权衡变得更加重要。
全精度和低精度格式
NVIDIA GPU支持五种基本浮点数据类型,每种类型的大小最多为1字节:
-
E5M2:8位浮点数,包含5位指数和2位尾数,最大有限值为57344。 -
E4M3:8位浮点数,包含4位指数和3位尾数,最大有限值为448,但精度高于E5M2。 -
E3M2:6位浮点数,包含3位指数和2位尾数,范围为-28到28。 -
E2M3:6位浮点数,包含2位指数和3位尾数,范围为-7.5到7.5,但精度高于E3M2。 -
E2M1:4位浮点数,包含2位指数和1位尾数,可精确表示数字{0, 0.5, 1, 1.5, 2, 3, 4, 5, 6}及其负数。
与IEEE格式不同,6位和4位类型不包含NaN或±∞。
低精度的UMMA
现在让我们深入探讨低精度UMMA的实现方式。我们将再次从UMMA的PTX开始讨论。UMMA的数据类型由.kind限定符确定,它支持多种数据类型,包括子字节数据类型。特别是,tcgen05.mma with .kind::f8f6f4支持的操作数可以是上述五种低精度数据类型中的任意一种(累加使用FP32或FP16)。需要注意的是,A和B的数据类型不必相同,因此这可用于混合输入UMMA。
操作限制
f8f6f4类型对操作数和输出张量施加了一些限制,这些限制可以在PTX文档的支持矩阵表中看到。值得注意的是,对于密集GEMM,MMA瓦片的K维度始终为32。一般来说,密集GEMM的操作数瓦片在K方向上必须为32字节宽,并且正如我们稍后将看到的,f8f6f4指令的操作数值会被填充,使每个值占用1字节。
动态数据类型
在第五代之前的张量核心指令(PTX mma指令)中,所有数据类型都编码在指令本身中,因此必须在编译时确定。另一方面,对于带有.kind::f8f6f4限定符的tcgen05.mma指令,支持上述五种数据类型的任意组合。数据类型的信息现在编码在指令描述符中,这是一个在设备上构建的PTX指令的运行时参数。因此,无需为每种类型单独编译二进制文件,就可以支持多种数据类型。
指令的Layout和TMA Load指令
主存和共享内存的Layout
在一个典型的使用场景中,例如简单的GEMM内核,操作数通常来自SMEM。在这种情况下,SMEM中的操作数数据必须以特定的16字节对齐格式存储,其中16个连续的4位或6位元素被紧密打包,然后填充到16字节边界。通常,SMEM中的数据可以通过几种方式进行重新排列,所有这些方式都遵循16字节边界。
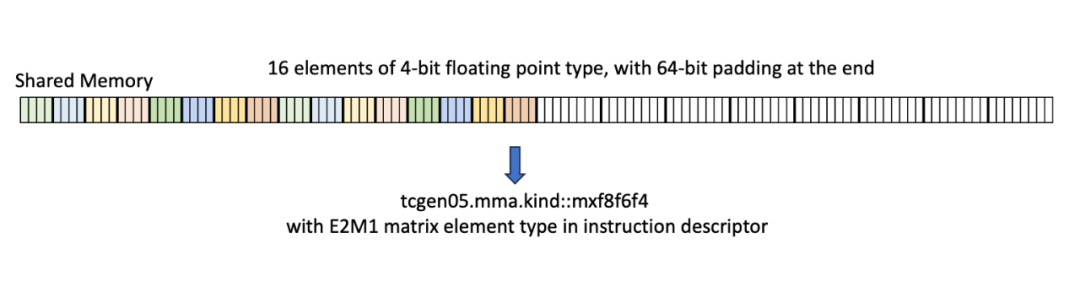
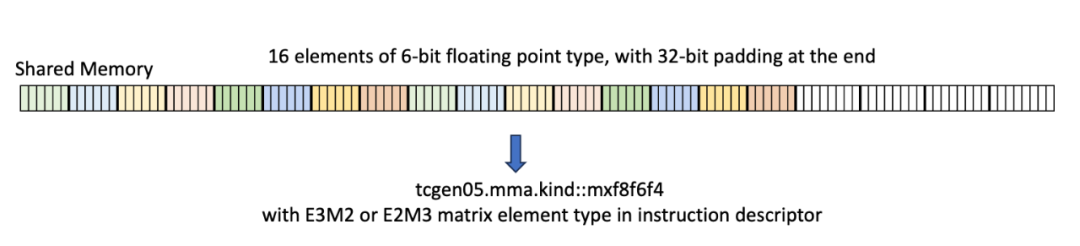
一个结果是,为子字节操作数分配SMEM空间时,会像处理字节操作数一样(这也是允许动态传递数据类型的一部分原因)。在SMEM中不支持完全压缩的连续数据与.kind::f8f6f4限定符一起使用。在下一篇文章中讨论块缩放时,我们将探讨支持压缩SMEM格式的mxf4类型。
SMEM中的操作数瓦片很可能会通过TMA从GMEM加载。当然,可以在GMEM中以相同的填充格式定义操作数布局,但这会浪费大量的GMEM空间和TMA带宽。考虑到低精度量化的部分目的是减少GPU内存中的模型大小,这是一个非常次优的解决方案。理想情况下,我们希望能够在GMEM中以压缩格式存储张量,并在加载到SMEM的过程中扩展到适当的填充格式。
TMA正好具备这种功能。Tensor Map对象是用于构建TMA描述符的低级CUDA抽象,具有tensorDataType选项来确定数据类型。该参数有两个选项,提供了我们需要的精确副本:
-
CU_TENSOR_MAP_DATA_TYPE_16U4_ALIGN16B – 将16个压缩的4位元素从GMEM复制到SMEM中16字节对齐的空间,添加8字节的填充。 -
CU_TENSOR_MAP_DATA_TYPE_16U6_ALIGN16B – 将16个压缩的6位元素从GMEM复制到SMEM中16字节对齐的空间,添加4字节的填充。
这些TMA加载版本在PTX中对应于cp.async.bulk.tensor,数据类型为.b4x16_p64或.b6x16_p32。
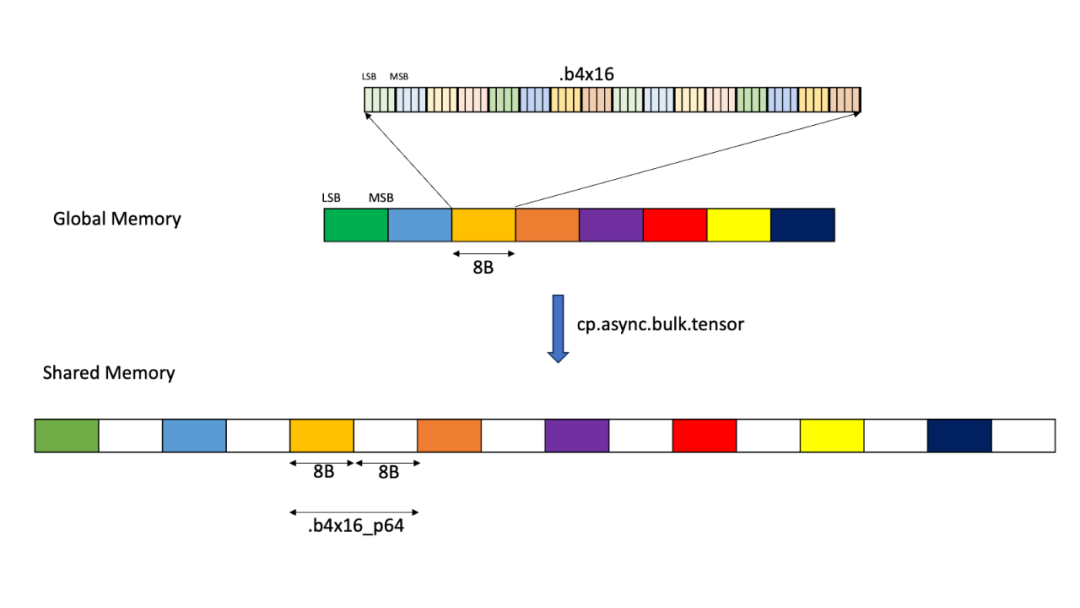
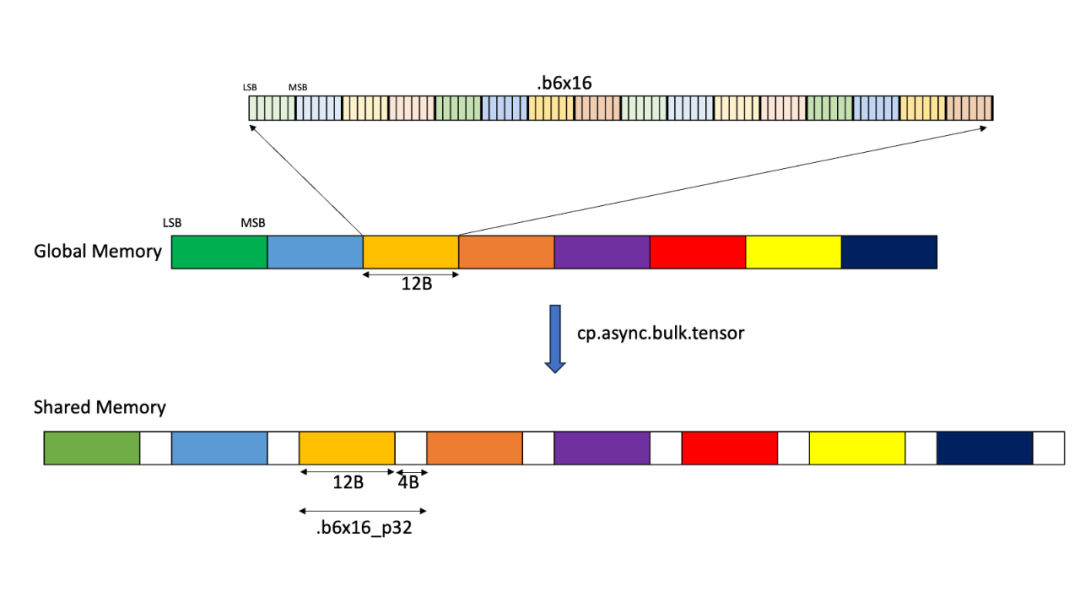
通过使用这些类型的TMA,我们可以从GMEM中的压缩数据源高效地获取所需的格式。这些类型对TMA施加了一些额外的限制,详见CUDA驱动API参考:
-
TMA的基地址必须是32字节对齐(而不是通常的16字节对齐要求)。 -
TMA张量在连续方向(即领先维度)上的大小必须是128个元素的倍数。 -
仅支持128字节的重新排列模式,或不进行重新排列。(感谢Together AI的Alex Angus指出这一点!)
在CUTLASS中,可以使用sm1xx_gemm_is_aligned()来检查GMEM的对齐要求,以及sm1xx_gemm_check_for_f8f6f4_mix8bit_requirement()来检查瓦片大小要求。需要注意的是,CUTLASS实际上要求4位数据应为64字节对齐,6位数据应为96字节对齐,因为这可以确保同时满足领先维度和基地址对齐的约束。
最后,需要注意的是,还有第三种用于子字节数据的Tensor Map数据类型,CU_TENSOR_MAP_DATA_TYPE_16U4_ALIGN8B(在PTX中为.b4x16),它将GMEM中的压缩4位数据复制到SMEM中的压缩、无填充格式。这在我们当前场景下并无用处,但在仅使用FP4的UMMA版本中会很有用,因为这些版本可以使用这种压缩格式。
TMEM layouts
除了从SMEM获取数据外,UMMA还可以从TMEM获取操作数A(但不能获取操作数B)。对于TMEM,UMMA操作期望子字节数据类型被填充到1字节容器中,包括4位数据。
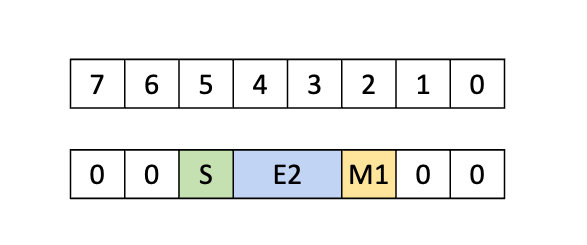
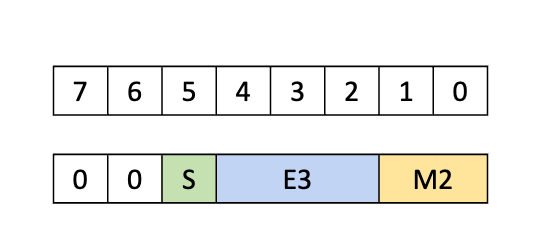
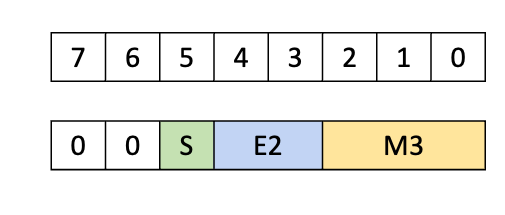
再次注意,为了分配TMEM空间,可以假设所有值均为1字节宽。
为了将子字节数据加载到TMEM以进行GEMM,典型的步骤如下:
-
在全局内存中保持数据压缩。 -
使用上述的“解包”TMA类型之一,从GMEM加载到SMEM,生成SMEM中16字节对齐、填充的数据。 -
最后,使用tcgen05.cp指令(可选解压缩)从SMEM加载到TMEM。这会将数据从SMEM的16字节填充格式转换为TMEM所需的字节填充格式。
CUTLASS 低精度的 UMMA
现在我们已经在硬件层面讨论了子字节UMMA,接下来让我们探讨它在CUTLASS中的抽象方式。目前没有针对子字节UMMA的CuTe示例,因此我们将直接查看CUTLASS内核代码。你也可以参考这个高级示例,它使用Collective Builder API构建了一个低精度GEMM内核,最终调用我们将要查看的内核代码。
数据类型
在CUTLASS中,子字节数据类型由cutlass/float_subbyte.h中定义的以下类型表示:
-
cutlass::float_e3m2_t -
cutlass::float_e2m3_t -
cutlass::float_e2m1_t
这些类型都继承自基类float_exmy_base,该基类表示通用的IEEE类型浮点数。值得注意的是,基本的数学操作是在这个父类中定义的。换句话说,不同数据类型的浮点数可以混合使用简单的数学运算符(如+和*)。但是,对于子字节数据,这些操作没有硬件支持,会以FP32执行。
此外,CUTLASS还为UMMA和TMA专门设计了特殊的子字节数据类型:
-
cutlass::float_e3m2_unpacksmem_t -
cutlass::float_e2m3_unpacksmem_t -
cutlass::float_e2m1_unpacksmem_t
这些类型会指示TMA在适用时使用16字节填充副本。因此,在f8f6f4 UMMA内核中,应优先使用这些类型而不是基本的子字节数据类型。示例代码如下:
using ElementAMma = cutlass::float_e2m3_unpacksmem_t;
using ElementBMma = cutlass::float_e2m1_unpacksmem_t;
using ElementCMma = cutlass::half_t;
Collective Builder通过cutlass::gemm::collective::detail::sm1xx_kernel_input_element_to_mma_input_element将普通类型转换为这些解包类型。内核代码期望从TiledMma中读取适当的类型。
SMEM布局
接下来,我们需要反映16字节对齐数据的SMEM布局。正如我们所见,对于所有子字节类型,这些SMEM布局实际上与8位数据相同,因此我们可以使用uint8_t定义SMEM布局。以下是来自sm100_umma_builder.inl的代码摘录:
using ElementAMma_SmemAllocType =
cute::conditional_t<cute::sizeof_bits_v<ElementAMma> < 8,
uint8_t, ElementAMma>;
using SmemLayoutAtomA =
decltype(cutlass::gemm::collective::detail::sm100_smem_selector<
UmmaMajorA, ElementAMma_SmemAllocType,
SmemShape_M, SmemShape_K>());
在这里,sm100_smem_selector是一个实用函数,根据输入参数选择具有最大重新排列的布局。
TMA
对于TMA,无需对make_tma_atom或2SM等效项进行更改,只需选择子字节数据类型并使用上述填充SMEM即可。CUTLASS TMA会根据unpacksmem数据类型使用专门的16字节对齐TMA。我们可以在cute/arch/copy_sm90_desc.hpp中看到这些数据类型到相应Tensor Map数据类型的映射:
if constexpr (is_same_v<T, float_e2m1_unpacksmem_t>) {
return CU_TENSOR_MAP_DATA_TYPE_16U4_ALIGN16B;
} else if constexpr (is_same_v<T, float_e2m3_unpacksmem_t>) {
return CU_TENSOR_MAP_DATA_TYPE_16U6_ALIGN16B;
} else if constexpr (is_same_v<T, float_e3m2_unpacksmem_t>) {
return CU_TENSOR_MAP_DATA_TYPE_16U6_ALIGN16B;
} else ...
Tiled MMA
最后,创建Tiled MMA也不需要任何更改,只需使用适当的F8F6F4原子即可:
TiledMMA tiled_mma = make_tiled_mma(SM100_MMA_F8F6F4_SS<ElementAMma, ElementBMma,
ElementCMma,
128, 256,
UMMA::Major::K,
UMMA::Major::K>{});
正如我们在之前的博客中看到的,原子名称中的SS表示两个操作数都来自SMEM。这里的元素类型可以是unpacksmem类型或默认类型;CUTLASS MMA已设置为接受两者。不过,Collective Builder使用unpacksmem版本进行MMA和TMA,这似乎是首选类型。
运行时数据类型
为了使用运行时操作数数据类型,需要指定以下类型之一:
-
cutlass::type_erased_dynamic_float8_t -
cutlass::type_erased_dynamic_float6_t -
cutlass::type_erased_dynamic_float4_t
对于SMEM布局,使用这些类型无需任何更改,因为SMEM布局始终按照8位数据计算。类似地,对于TMA,数据格式无关紧要(尽管位数很重要,因为它需要用于构建Tensor Map),因此除了使用这些type_erased类型外,无需其他更改。然而,对于MMA本身,我们需要手动更新指令描述符。例如,我们可以在以下来自sm100集体主循环代码的摘录中看到这一点:
tiled_mma.idesc_.a_format_ = uint8_t(runtime_data_type_a_) & 0b111;
tiled_mma.idesc_.b_format_ = uint8_t(runtime_data_type_b_) & 0b111;
在这里,runtime_data_types是用于指令描述符的数据类型的整数表示。在CUTLASS中,这些可以作为参数传递给内核,作为cute::UMMA::MXF8F6F4枚举类的成员。
总结
在本文中,我们探讨了NVIDIA Blackwell架构对低精度数据类型的支持,特别聚焦于子字节数据类型。我们首先研究了PTX和硬件的细节,讨论了如16字节对齐、填充的SMEM格式以及运行时数据类型选择等内容。然后,我们分析了CUTLASS的实现:创建SMEM布局、指示TMA格式化数据,以及使用运行时数据类型。
与这些低精度数据类型最常用的操作之一是通过块缩放进行量化。Blackwell GPU的硬件现已支持对大小小于或等于1字节的数据类型进行块缩放。我们将在本系列的下一篇文章(也是最后一篇)中详细讨论这一点。
— 完 —
(文:GiantPandaCV)